关注空间数据的Python编程语言导论
英文原作者:Ujaval Gandhi
中文翻译:CycleUser
导论
这个课程讲的是非常基础的Python内容。针对的是缺乏编程基础经验也不太了解Python的GIS从业者。主要会介绍基础编程概念和用于空间分析的基础库,地学空间接口(geospatial API)和构件空间数据处理通道的各种技术。
至于为什么以及如何学习Python,可以原作者参考之前的一份文章提取码: ws5j.
数据集
本文的代码样例使用了各种数据集。所有需要用到的数据集和 Jupyter Notebook 文件都在一个压缩包python_foundation.zip中。建议将其解压缩到<home folder>/Downloads/python_foundation/路径。
本文相关资料python_foundation.zip提取码: m5ns
安装和设置环境
在你的操作系统上安装Python有很多办法。大多数操作系统(Linux发行版和macOS)都内置了Python。如果你使用的是QGIS之类的软件,就也有随之而来的自带的Python。创建和运行Python项目一般还需要安装第三方库(依赖包、一些工具)。这些第三方库可能有不同的依赖关系,这就可能导致一些依赖关系的冲突,另外各种包对Python的版本支持也不一样。
要实现简单可靠的安装,就建议使用Anaconda。本文使用的是 Anaconda3 来安装Python和空间分析需要用到的第三方库。
很多Python工具的命名都参考了爬行动物的世界。比如默认的Python包管理器叫做Pip ,指的就是爬行动物产卵的过程。不过有意思的事,Python编程语言本身的命名实际上和爬行动物没有任何关系。 安装 Anaconda和依赖包有两种途径:
- 图形界面Graphical User Interface (GUI):这就需要使用Anaconda Navigator 程序,有一个用户友好的界面,可以创建一个个独立的Python环境,以及安装依赖包。适合初学者。
- 命令行界面Command Line Interface (CLI):Anaconda提供了一个
conda命令可以在终端(Windows的Command Prompt,macOS/Linux的Terminal)中运行。这个方法更快、效率更高,但需要对命令行有所了解。
这两种方式你选择哪一种都可以。这里建议大家先使用图形界面,如果遇到问题了,可以在命令行界面中设置环境来解决。两种方法都能够进行同样的环境设置。
图形界面 (Anaconda Navigator)
- TUNA 提供了 Anaconda3 安装包 ,也可以访问 Anaconda 官网。一定注意要选择 Anaconda3,选择最新版本的,还要符合你的操作系统。(译者注:以 Windows 11 64bit 操作系统为例,就要选择 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-Windows-x86_64.exe ;如果用的是 macOS,就可以选择 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-MacOSX-x86_64.pkg )。选最新版本是为了使用 Python 3.8 或更新的版本。下载好之后,双击安装,选择Just Me ,勾选use default settings。
如果你是Windows用户,并且你的用户名里面有空格或者非英文用户名,那就可能导致问题。这时就要将路径设置为
C:\anaconda。
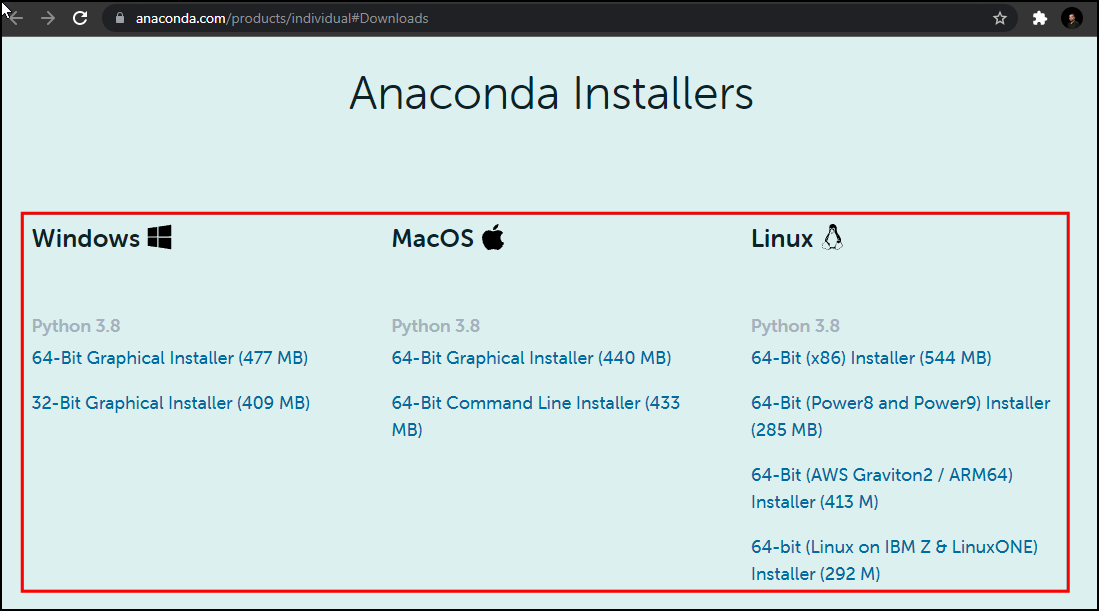
- 安装完成后,就可以启动Anaconda Navigator程序,在实践中,可以给你的每一个Python项目创造一个对应的单独的新环境environment。一个环境就是一个你用来安装各种依赖包的空间。很多包的依赖关系可能发生冲突,所以就不适合安装到一个单独的环境中去。分别创建环境就可以很好地规避这种问题。点击环境Environments 标签。
Linux用户需要打开终端输入
anaconda-navigator来加载程序。
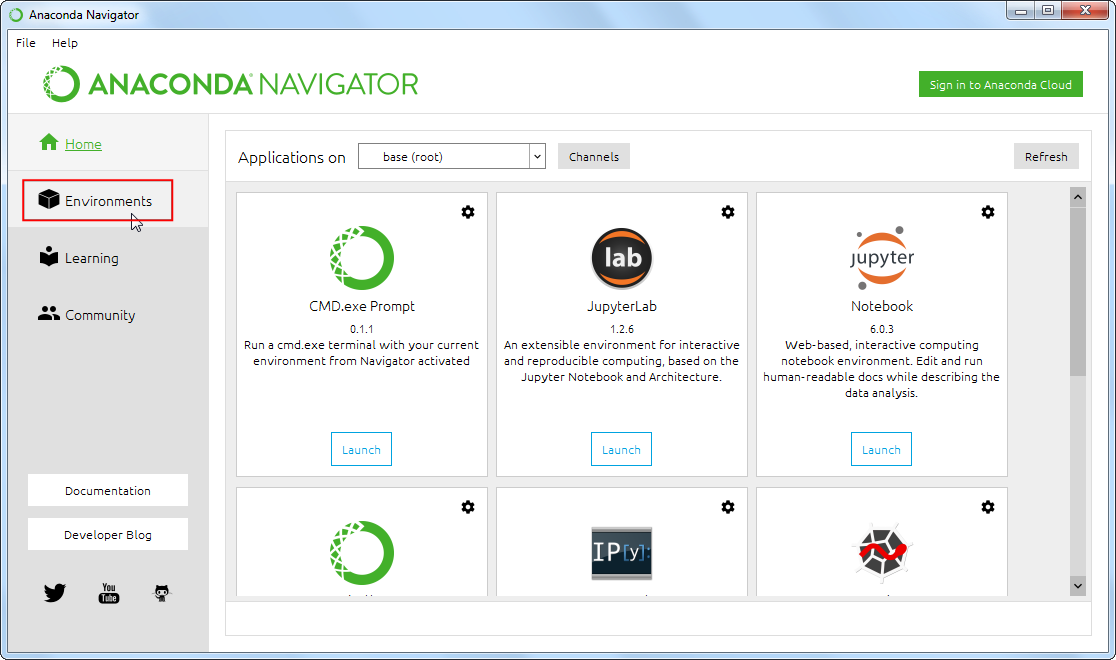
- 点击+ Create 按钮,然后输入环境名称为
python_foundation。选中Python,设置版本为默认值就可以。然后点击创建Create。
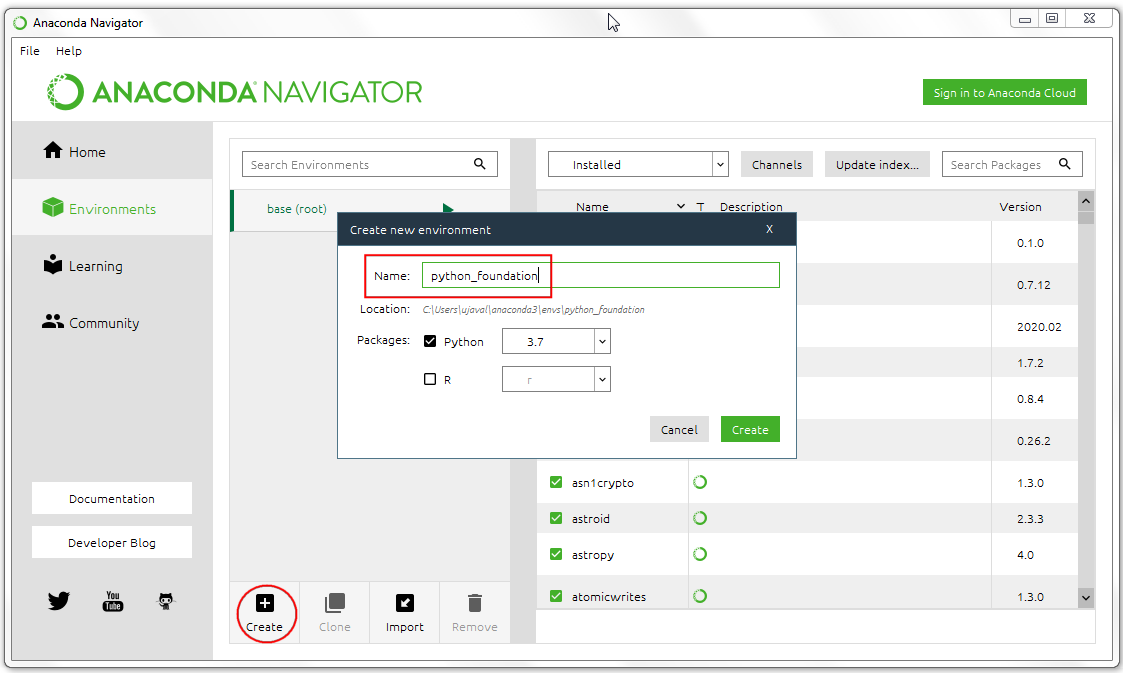
- 创建环境之后,点击Channels 按钮。一个频道(channel)就是一个存储包的存放处(repository)。默认频道对于大多数通用用途来说都不错,但没有提供我们需要的一些依赖包。所以我们需要添加其他频道。在Manage channels对话框点击Add添加,然后输入
conda-forge,之后按Enter回车键。
更多相关内容可以参考 conda-forge官方文档

- 点击Update Channels按钮更新。
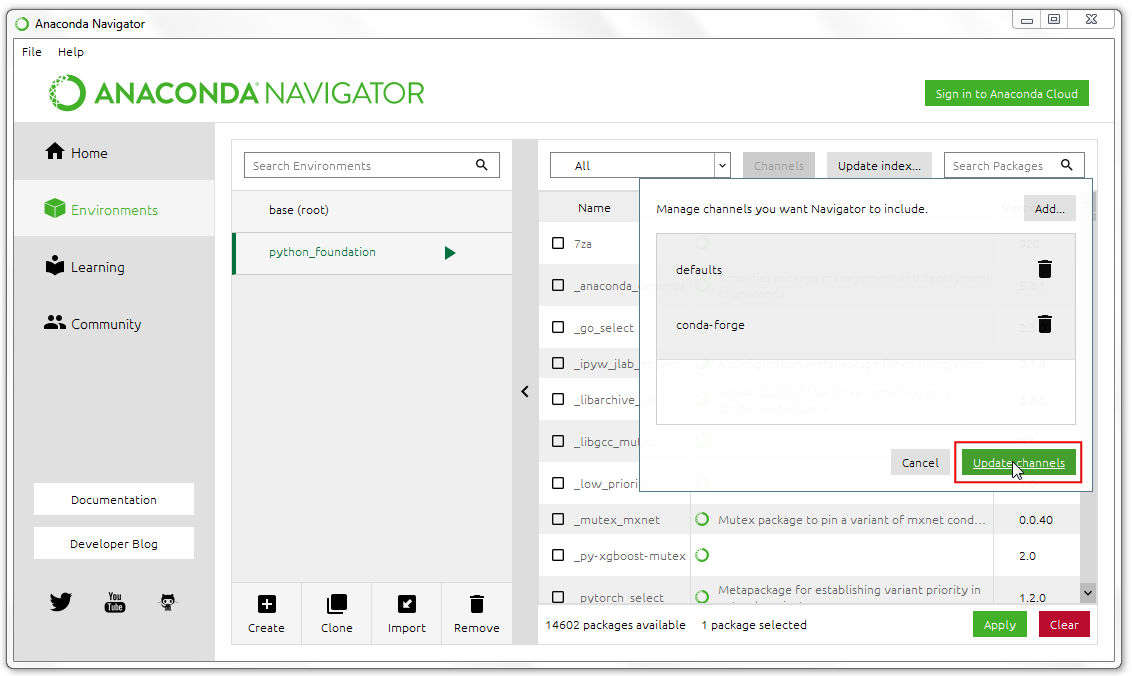
- 更新完成后,搜索一个名为
geopandas的包。这个包适用于在Python中处理矢量地理空间数据进(vector geospatial data)。选中第一个搜索结果旁边的勾选框,然后点击应用Apply来安装所选包及其全部依赖。
如果你没发现有搜索结果,确保没输入错名字,以及检查一下在 Channels 旁的下来菜单是否选中了All。不要选Installed,Installed意思是在你已经安装的包里面检索。
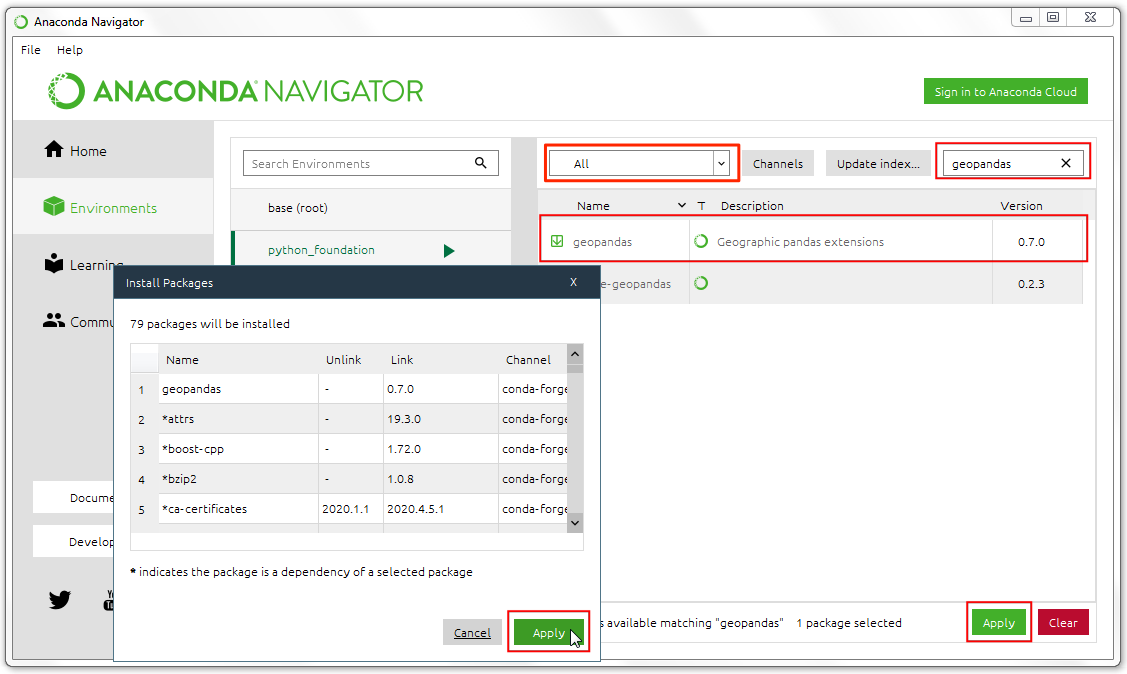
-
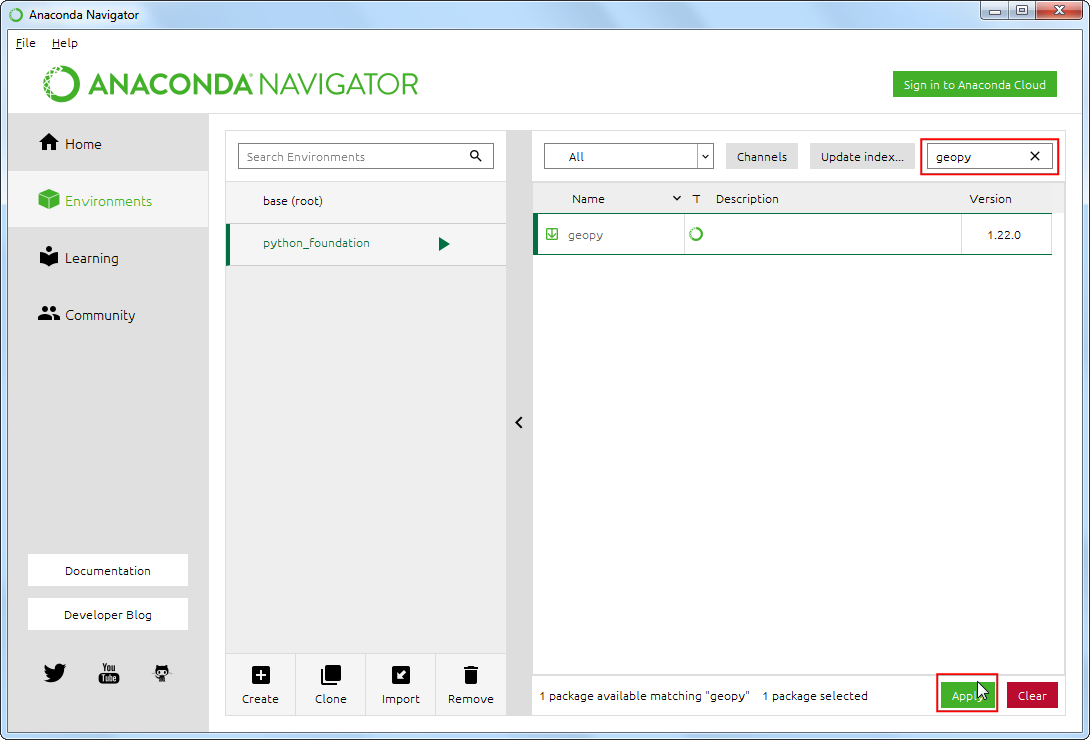
下面几个包也要用上面的步骤来安装。
-
geopy rasteriomatplotlib
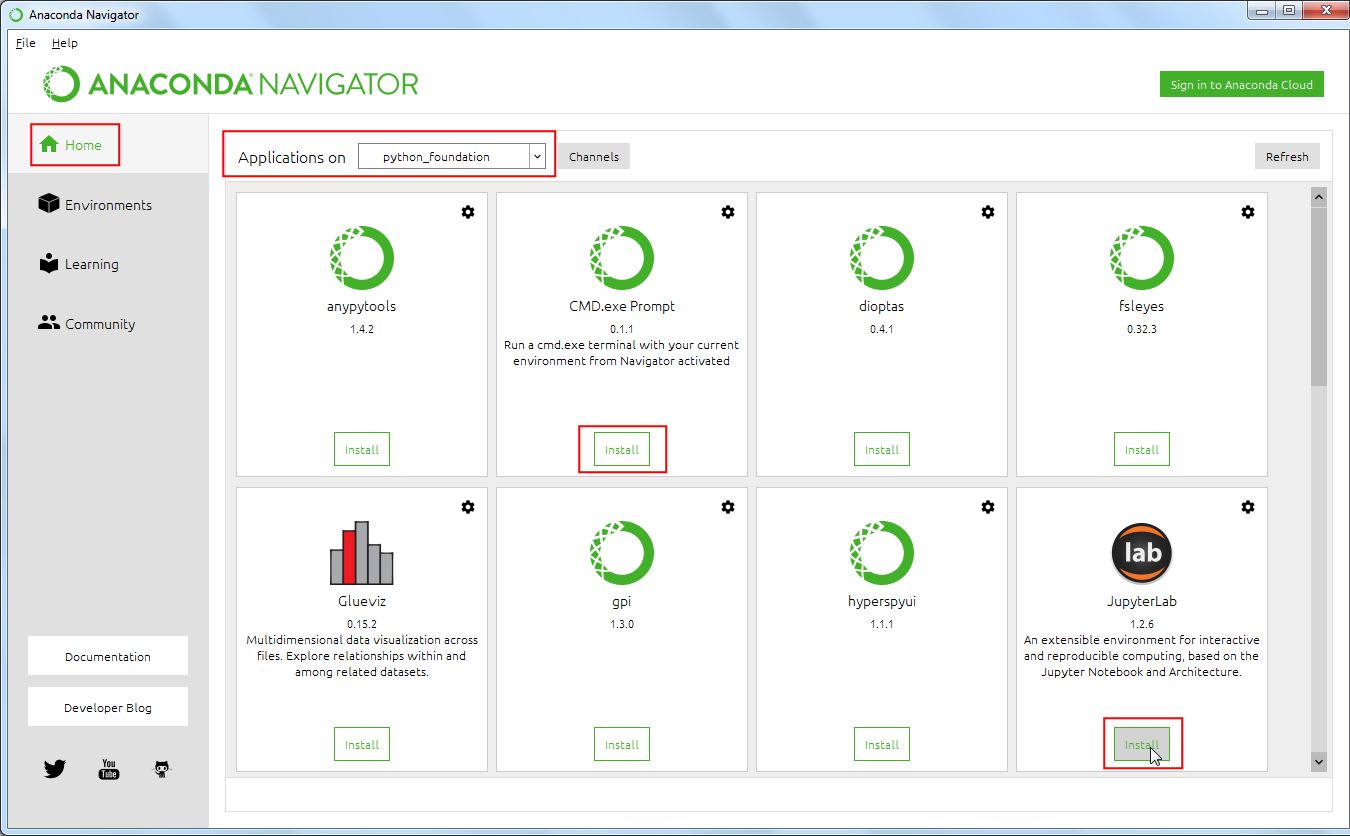
- 切换到Home标签页。确保你选中的事咱们刚创建的环境python_foundation 。接下来要安装几个程序来编写和运行Python脚本代码等等。在Home标签页上,选中安装
JupyterLab这一程序。Windows系统用户可能需要安装CMD.exe prompt程序。
- 安装完成后,点击JupyterLab程序旁边的Launch 按钮来启动。JupyterLab是一个基于浏览器的应用,允许你来编写代码、文档以及运行代码。你可以在内部交互地运行一些小段代码。也支持图表、地图等等输出内容在界面上进行展示。这个程序的名字Jupyter来自于三种编程语言:Julia、Python、 R。本文的所有练习都使用Jupyter来进行。
Linux和macOS的命令行用户可以在终端中输入
conda activate python_foundation来激活环境。然后终端中输入jupyter-lab命令就可以运行JupyterLab。
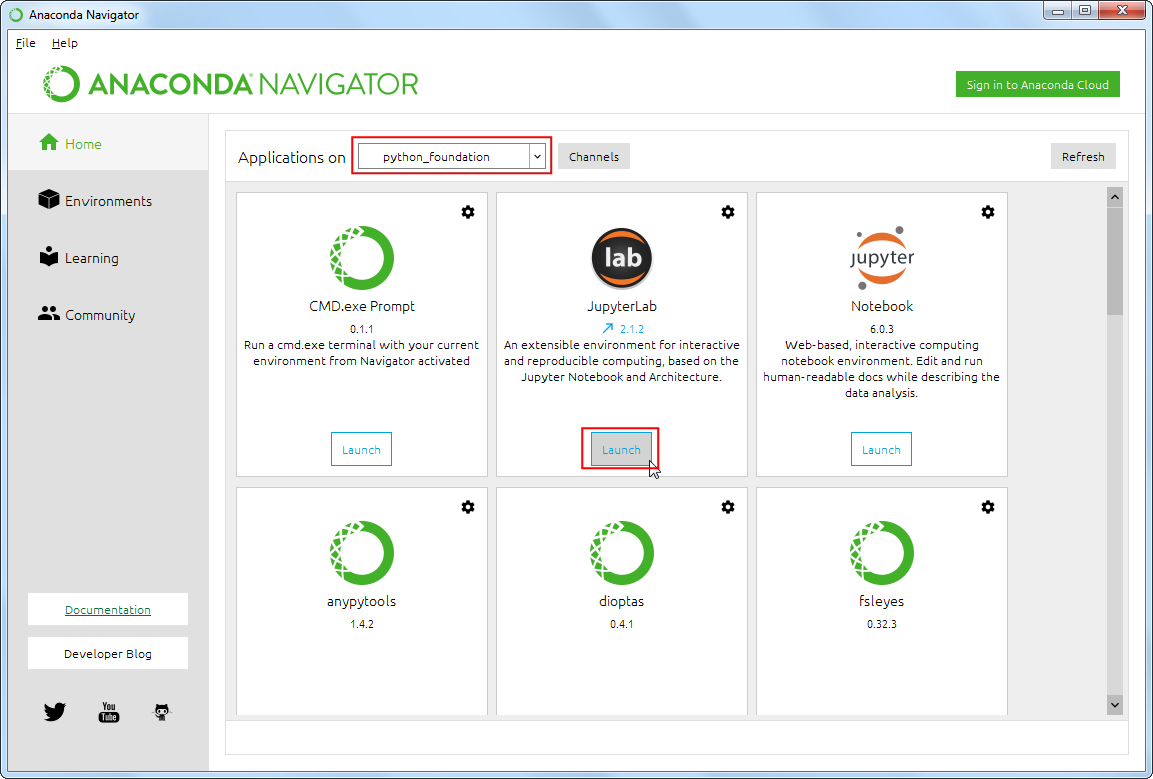
- 浏览器会弹出一个标签页,就是JupterLab的界面了。点击Notebook下面的Python 3按钮启动。
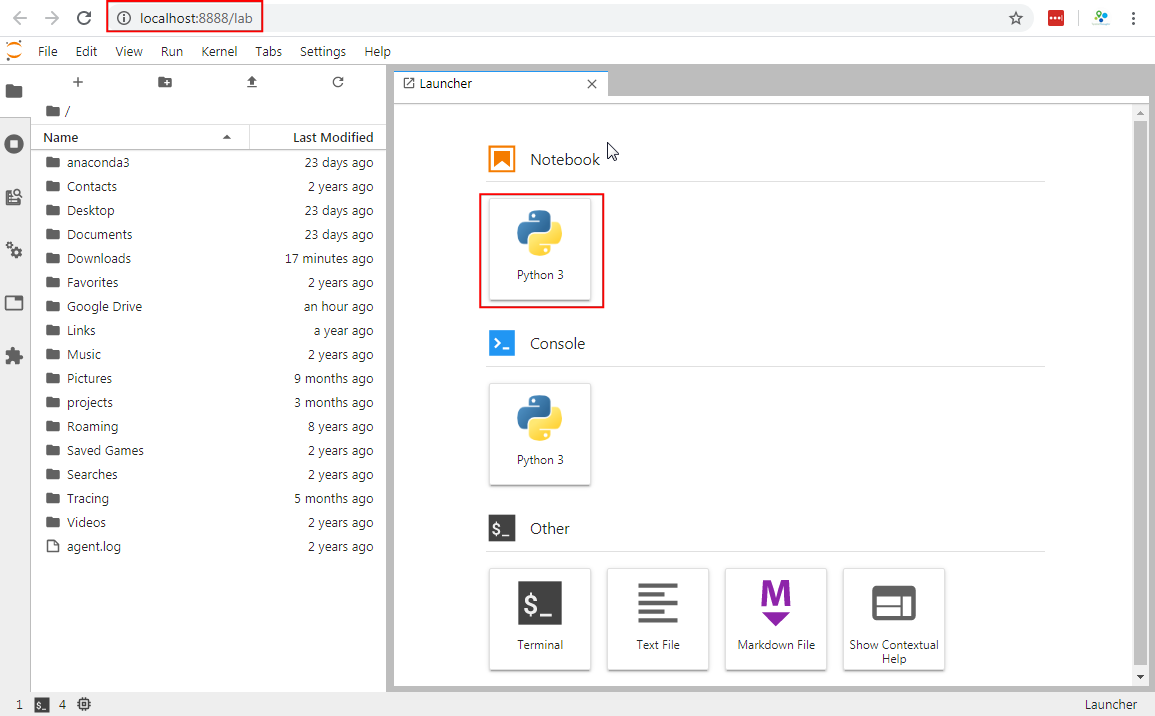
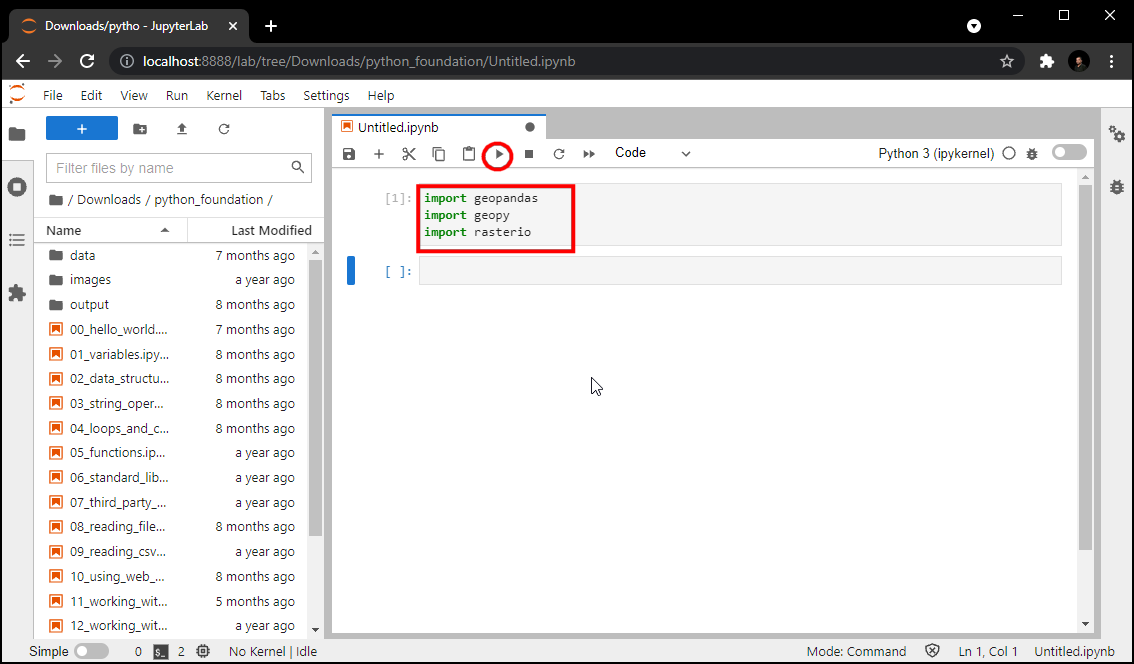
- 在第一个代码块(cell)中输入下面的代码,然后点击 Run 按钮来运行。如果什么都没有发狠过就证明你这几个依赖包的安装都成功了,没有任何问题。如果你遇到了导入错误 ImportError,就说明对应的包安装不成功,你得按照上面的教程重新安装一下。如果持续出现错误,就可能需要参考下一章的内容来使用命令行界面解决问题了。
import geopandas
import geopy
import rasterio
命令行界面(Anaconda Prompt / Terminal)
这部分讲的是命令行模式的安装过程。如果你之前已经用图形界面的方法安装成功了,这部分就可以略过了。
- 还是到 Anaconda3 官网下载安装包,版本还是要 Python3.8或者更高版本的,选对应你操作系统的版本。下载完成后还是选择Just Me以及使用默认设置use default settings。
和上面一样,如果你是Windows用户,并且你的用户名里面有空格或者非英文用户名,那就可能导致问题。这时就要将路径设置为
C:\anaconda。
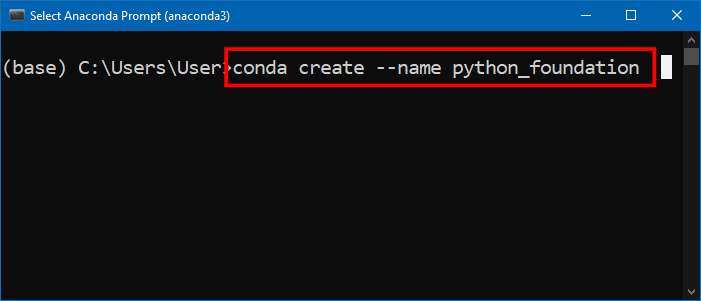
- 安装完成后,Windows用户从开始菜单找到并启动Anaconda Prompt 程序,macOS/Linux用户打开终端Terminal 。和上面一样,还是要为你的每个Python项目创建对应的独立的新环境。这个新环境就是用来存储这个Python项目对应的依赖包的。这样可以避免不同项目依赖包不同或者Python版本不同等因素导致的各种冲突和潜在问题。在命令行中输入下面的命令,回车执行。
conda create --name python_foundation
- 接下来会让你确认;输入y然后按回撤就继续完成环境创建了。
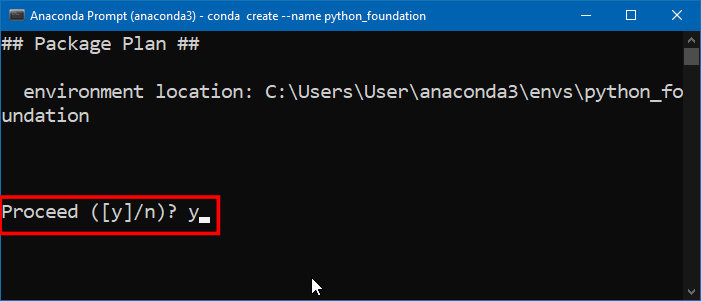
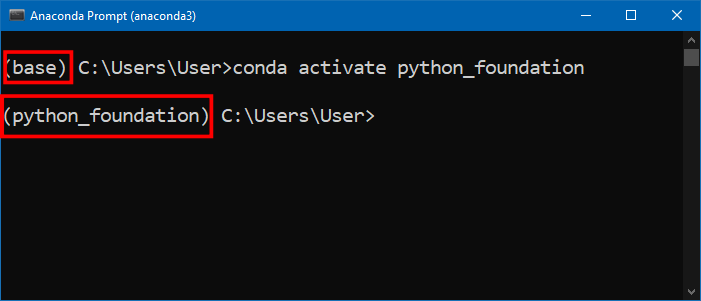
- 创建好环境之后还是要激活才生效,输入下面的命令然后按回车确认。激活之后,最前面的
(base)会变成(python_foundation)。
conda activate python_foundation
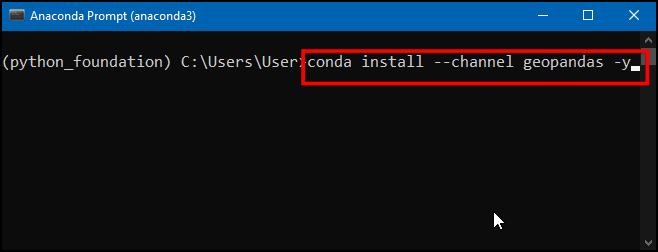
- 接下来就可以利用
conda install命令来安装需要的包了。首先安装geopandas,用来让Python能处理矢量化空间数据。需要使用conda-forge频道(channel)来安装这个包。后面的后缀-y是用来确认,就跳过了它询问你是否继续哪一步来。输入命令后回车运行。
conda install --channel conda-forge geopandas -y
更多相关内容可以参考 conda-forge官方网站。
- 安装成功后,终端界面显示如下。
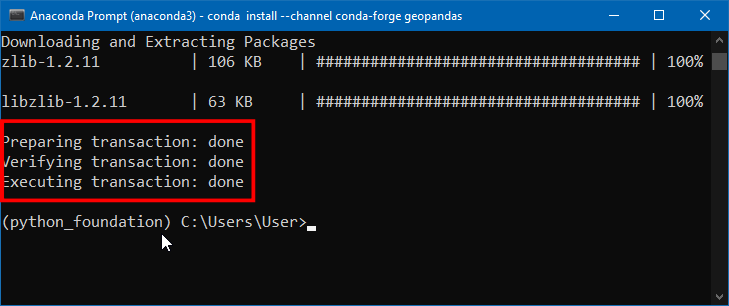
geopandas的安装还挺麻烦的,有时候可能不一定成功。所以安装完成后你可以用下面的命令来导入测试一下,看看有没有出错信息。python命令后加一个-c选项就是直接执行对应的语句,千万要注意这里要加英文双引号。输入命令后回车,没有任何错误信息输出就成功了。
python -c "import geopandas"
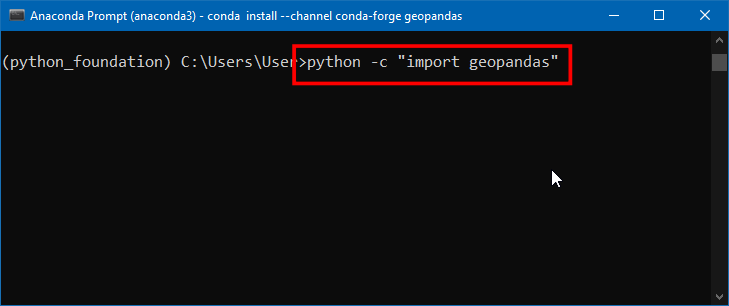
- 如果你的 geopandas 安装没问题,就什么输出都不会有。 什么都没发生,就说明你安装成功了。
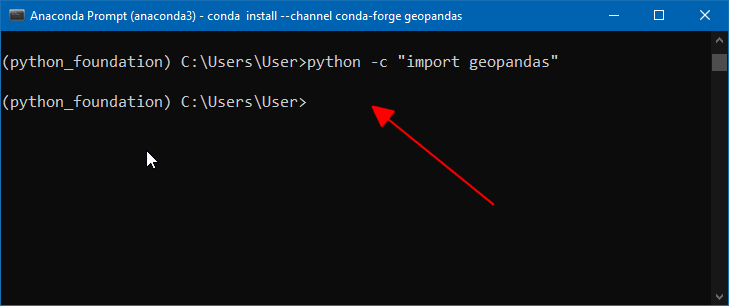
- 然后再安装其他的几个包,
geopy,rasterio,matplotlib,jupyterlab,安装命令如下,复制粘贴到终端,然后回车运行。
conda install --channel conda-forge geopy rasterio matplotlib jupyterlab -y
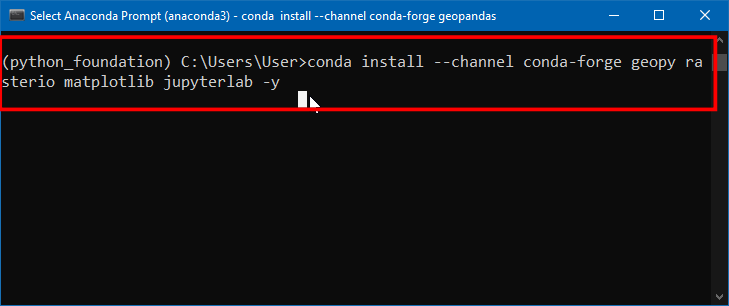
- 上述命令成功完成后,屏幕应该如下所示。
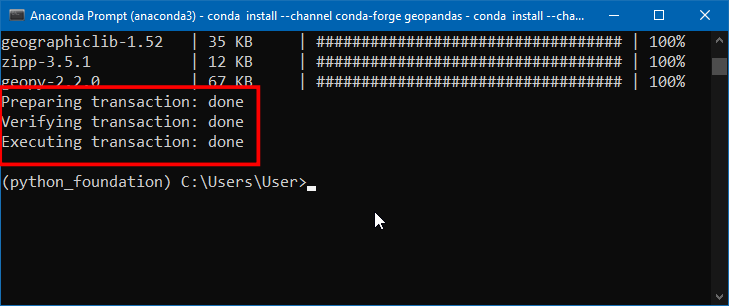
- 你的Python环境这就应该创建好了。在终端中输入下面的命令来启动JupyterLab就可以了。它会在你的系统上启动一个本地服务器,然后打开你的默认浏览器来访问JupyterLab的主界面。
注意:在你使用JupyterLab期间千万别关闭刚刚这个命令行界面。你要一直留着它在那运行着,你一关闭的话,JupyterLab就退出了。
jupyter-lab
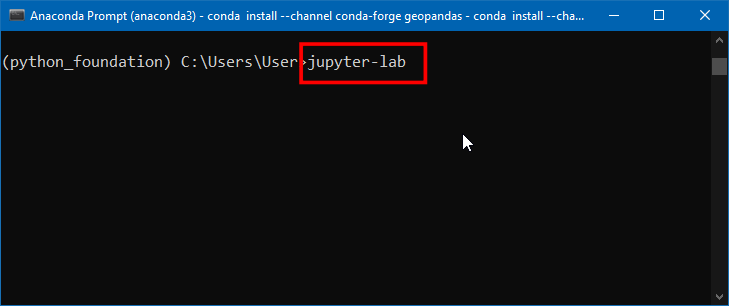
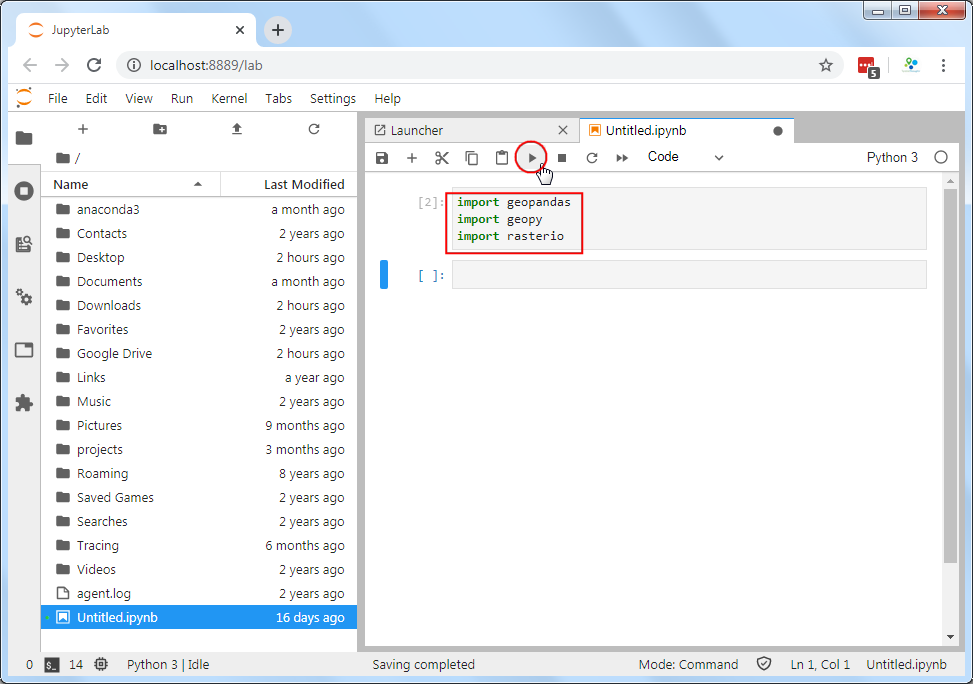
12.浏览器页面会打开一个新标签页,就是JupyterLab的界面了。点击Notebook下面的Python 3 按钮。

- 在第一个代码块(cell)里面输入下面的命令,然后点击小三角的那个 Run 运行按钮。 如果什么输出都没有,就说明安装成功了。如果你遇到导入错误ImportError,就说明安装未成功,重新安装吧。
import geopandas
import geopy
import rasterio
使用 Jupyter Notebooks
本课程提供的压缩包里面已经有多个 Jupyter Notebooks 文件,里面包含了本课程的代码和练习数据。
- 运行JupyterLab 程序,会打开你的默认浏览器,加载一个新的标签页。从左边的面板中,找到本课程所提供压缩包解压后的位置。
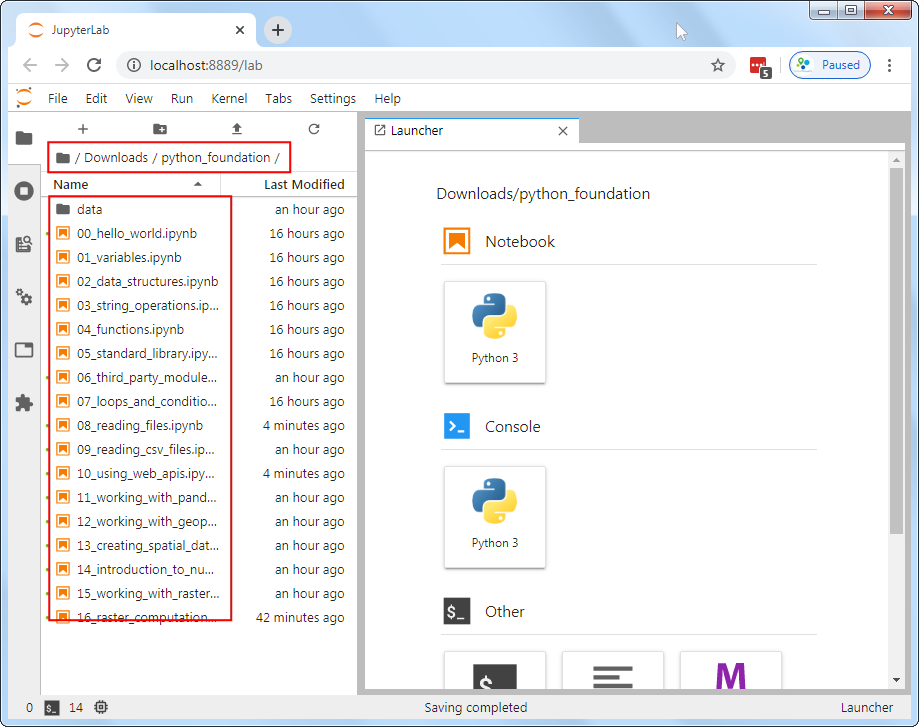
- Jupyter notebooks 的文件后缀是
.ipynb。在左侧的面板中找到一个这样的文件双击来打开。这里面的代码是一个个按照块(cell)来执行的。你可以选择一个块,然后点击运行按钮Run来运行一下看看输出是什么样的。
- 每个notebook结尾,都有一个对应的联系。在添加新代码块来完成练习之前,一定要记得到Run → Run All Cells来执行完毕整个 notebook 中的所有代码。这会保证你需要在练习中用到的变量都可用。
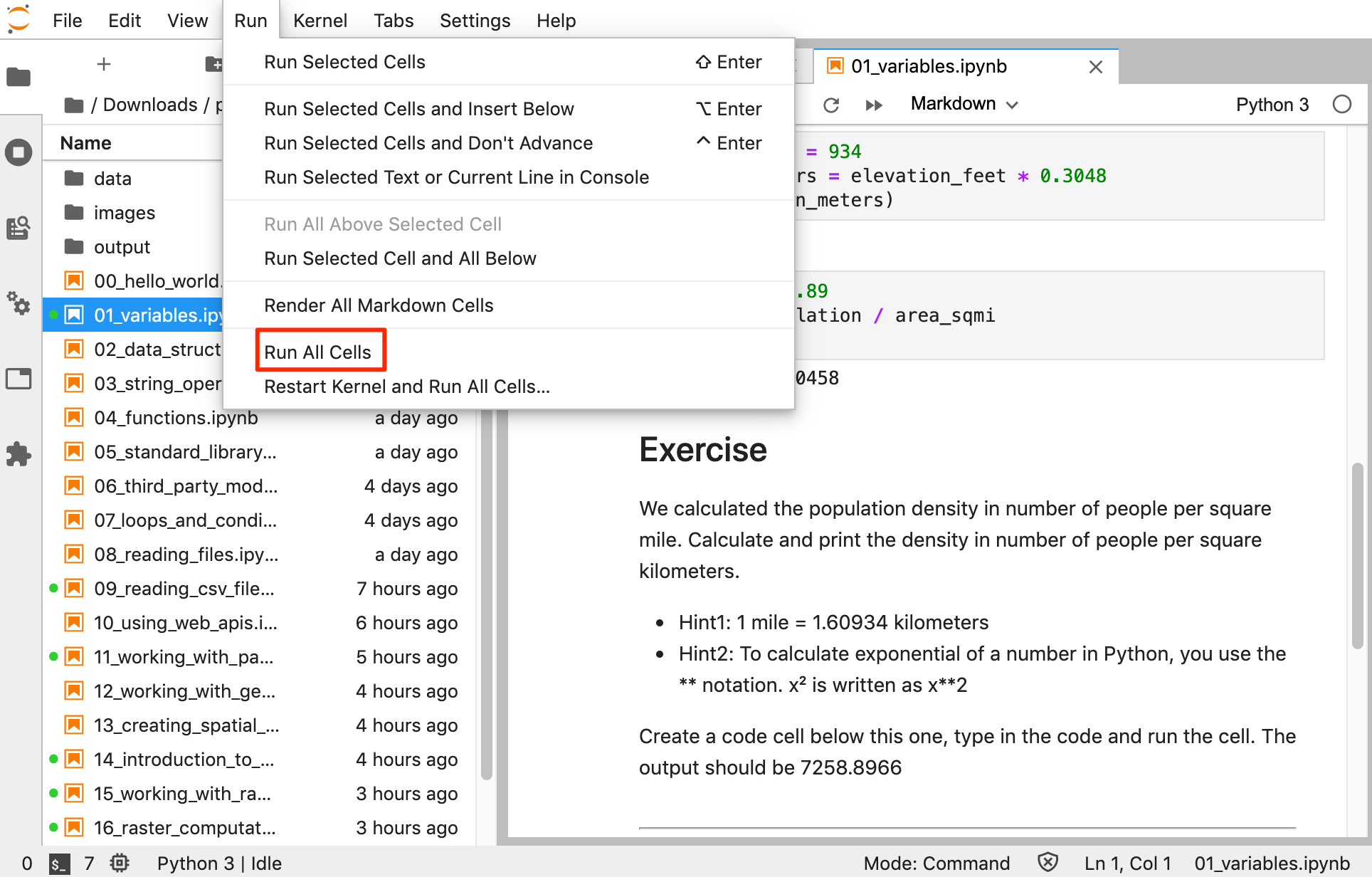
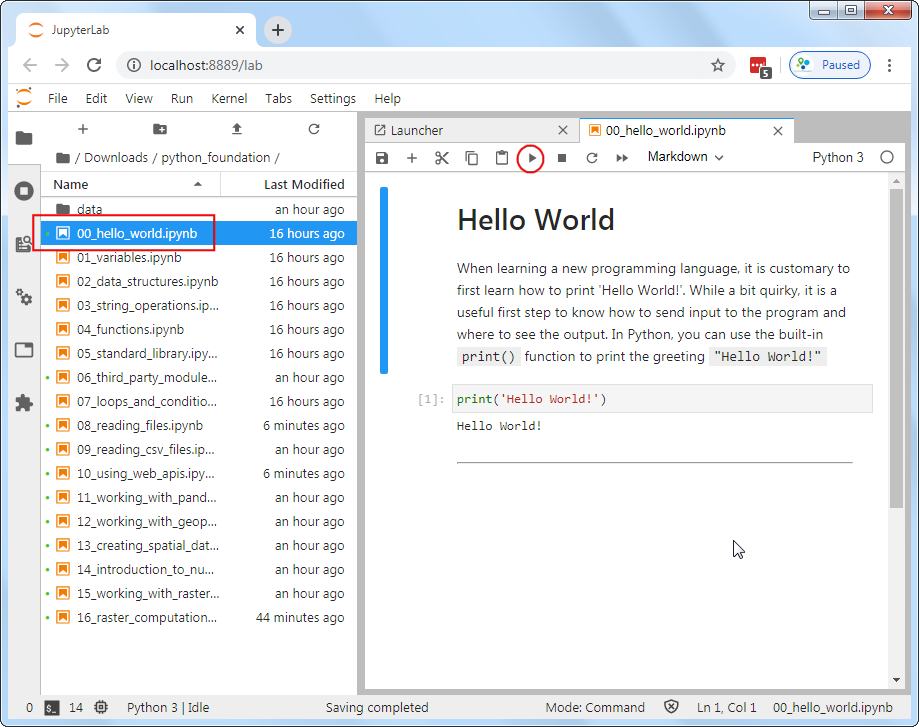
打开 00_hello_world.ipynb.
Hello World
学习一门新的编程语言,总是躲不开打印输出‘Hello World!’。在Python里面,使用的就是内置的print() 来输出就行了,如下所示:
print('Hello World!')
打开 01_variables.ipynb.
变量类型
字符串(Strings)
字符串就是字符、数字、标点符号等组成的一个序列,也就是平常所说的文本。
Python 里面使用单引号或者双引号来创建字符串。
city = 'San Fransico'
state = 'California'
print(city, state)
print(city + state)
print(city + ',' + state)
数值(Numbers)
Python支持的数值类型很多,不过最常用的就是下面这两种:
- int,整数
- float,浮点数
population = 881549
latitude = 37.7739
longitude = -121.5687
print(type(population))
print(type(latitude))
elevation_feet = 934
elevation_meters = elevation_feet * 0.3048
print(elevation_meters)
area_sqmi = 46.89
density = population / area_sqmi
print(density)
练习:单位转换
以公里为单位的变量distance_km的值是 4135,这就是旧金山和纽约之间的距离。创建另一个变量 distance_mi来转换到英里。
- 提示1: 1 mile 英里 = 1.60934 kilometers 公里
在下面的代码基础上添加语句并运行,结果应该是2569.37。
distance_km = 4135
# Remove this line and add code here
打开 02_data_structures.ipynb.
数据结构
元组(Tuples)
元组 tuple 是对象(object)组成的序列。内部的对象可以有任意多个。在 Python里面,元组的特点是外面用圆括号()包着的。
latitude = 37.7739
longitude = -121.5687
coordinates = (latitude, longitude)
print(coordinates)
通过位置也就是索引(index)可以读取元组中的每个元素。一定要注意,在编程语言中,查数的起点是0.所以第一个元素的索引值是0,而第二个元素的索引值才是1,这一点一定要记住。设置索引值的时候使用方括号 []。
y = coordinates[0]
x = coordinates[1]
print(x, y)
列表(Lists)
列表list和元组有点相似,但有一个关键不同。元组在创建后就不能修改,即元组不可变(immutable)。而列表是可以修改的(mutable)。你可以对列表中的元素进行增、删、改。在Python中,列表的外面用方括号[]包起来。
cities = ['San Francisco', 'Los Angeles', 'New York', 'Atlanta']
print(cities)
列表的索引方式和元组一样。
print(cities[0])
在Python中可以使用内置的len()函数来计算对象的长度。
print(len(cities))
对列表可以使用append()方法(method)来添加元素。
cities.append('Boston')
print(cities)
列表可修改,所以添加元素后长度就变了。
print(len(cities))
另一个有用的列表方法就是排序sort() 。
cities.sort()
print(cities)
排序默认是升序(ascending ),如果想要降序(decending ),需要调用的时候加上参数reverse=True。
cities.sort(reverse=True)
print(cities)
集合(Sets)
集合和列表有点像,但还有一些有趣的特性。主要就是集合内的元素不能重复。另外还支持集合运算符(set operations),比如交集、并集、取异(intersection、union、difference)。具体使用中,一般都是用列表来创建集合。
capitals = ['Sacramento', 'Boston', 'Austin', 'Atlanta']
capitals_set = set(capitals)
cities_set = set(cities)
capital_cities = capitals_set.intersection(cities_set)
print(capital_cities)
集合可以用于寻找列表中的不重复元素。将两个列表使用extend()来合并,得到的列表可能会有重复的。然后可以从这个得到的列表创建一个集合,就可以移除重复元素。
cities.extend(capitals)
print(cities)
print(set(cities))
字典(Dictionaries)
Python中的字典是用大括号{}括起来的。字典由键名keys和值values组成的键值对构成。列表和元组是按照顺序来读取元素,而字典则是要通过键名来读取元素。键和值之间用冒号:分隔。
data = {'city': 'San Francisco', 'population': 881549, 'coordinates': (-122.4194, 37.7749) }
print(data)
将键名用方括号括着,然后就可以读取字典中对应位置的值了。
print(data['city'])
练习
从下面的字典中要读取经纬度的值,怎么实现? 下面字典的地理位置是纽约城,从中提取一下经纬度。 正确的结果应该是:
40.661
-73.944
nyc_data = {'city': 'New York', 'population': 8175133, 'coordinates': (40.661, -73.944) }
打开 03_string_operations.ipynb.
字符运算(String Operations)
city = 'San Francisco'
print(len(city))
print(city.split())
print(city.upper())
city[0]
city[-1]
city[0:3]
city[4:]
转义字符(Escaping characters)
Python语言本身有很多特殊字符有特定用途。比如单引号 ’ 就用来定义字符串。如果你就想要一个字符串包含这样一个单引号该怎么办?
这时候,就可以在Python字符串中使用反斜杠**,这是一个特殊字符,也叫做「转义字符」。将这个字符添加在任何字符前面,都使得该字符成为一个常规字符。(提示,反斜杠前面放一个反斜杠会使得后者也变成一个常规的反斜杠字符而没有特殊作用。)
另外,反斜杠也用于表示特定的语义字符,比如\n就是换行,\t就是一个tab(四个空格或者八个空格,和系统相关)等等。
删除掉#号,就可以去掉块中的注释,然后就能运行了。
# my_string = 'It's a beautiful day!'
因为单引号没有加转义字符,所以会报错。可以通过在单引号前面添加反斜杠来解决掉这个问题。
my_string = 'It\'s a beautiful day!'
print(my_string)
还有一个办法就是对整个字符串用双引号,这样中间的单引号也没问题了。
my_string = "It's a beautiful day!"
可是,如果你的字符串里面同时包含单引号和双引号怎么办呢? 可以在外面用三重单引号!这样就能解决全部问题了。
latitude = '''37° 46' 26.2992" N'''
longitude = '''122° 25' 52.6692" W'''
print(latitude, longitude)
对于Windows用户来说,反斜杠在路径的时候带来了问题。
#path = 'C:\Users\ujaval'
#print(path)
这时候可以在整个字符串前面加一个字母r,意思就是这是一个原生字符串Raw string。这样就不会把反斜杠解释成特殊字符了。
path = r'C:\Users\ujaval'
print(path)
打印字符串(Printing Strings)
从变量创建字符串的现代方式是利用format()方法。
city = 'San Fransico'
population = 881549
output = 'Population of {} is {}.'.format(city, population)
print(output)
还可以使用format()来控制输出数字的精度。
latitude = 37.7749
longitude = -122.4194
coordinates = '{:.2f},{:.2f}'.format(latitude, longitude)
print(coordinates)
练习
使用字符串切片提取并打印度分秒。输出应该如下所示:
37
46
26.2992
latitude = '''37° 46' 26.2992"'''
打开 04_loops_and_conditionals.ipynb.
循环和条件
For 循环
For 循环要使用一个序列进行迭代(iterating)。这个序列可以是列表、元组、字典、集合,或者字符串。
cities = ['San Francisco', 'Los Angeles', 'New York', 'Atlanta']
for city in cities:
print(city)
要对一个字典进行迭代,可以调用items()方法,返回的是一个元组,由一个键和值组成。
data = {'city': 'San Francisco', 'population': 881549, 'coordinates': (-122.4194, 37.7749) }
for x, y in data.items():
print(x, y)
内置的range()允许你基于数值来创建可迭代的序列。
for x in range(5):
print(x)
还可以设置起止点和步长。
for x in range(1, 10, 2):
print(x)
条件判断
Python支持的逻辑条件包括等于、不等、大于、小于、大于等于、小于等于等等。这些条件可以有多种用法,最常见的是放在if语句和循环体中。
很自然,if 语句就是用if关键词写的了。
注意:有一个常见的错误就是在逻辑条件判断的时候使用单等号=,单个等号=是用来赋值的,不是用来判断相等关系的。判断相等关系要用双等号==才行。
for city in cities:
if city == 'Atlanta':
print(city)
和if配合使用的else就可以做多个条件的判断了。
for city in cities:
if city == 'Atlanta':
print(city)
else:
print('This is not Atlanta')
Python的代码要靠缩进来区分段落。所以一定要做好代码缩进。
使用elif还可以评估一系列的判断条件。
多个条件的组合可以使用and 和 or。
cities_population = {
'San Francisco': 881549,
'Los Angeles': 3792621,
'New York': 8175133,
'Atlanta':498044
}
for city, population in cities_population.items():
if population < 1000000:
print('{} is a small city'.format(city))
elif population > 1000000 and population < 5000000:
print('{} is a big city'.format(city))
else:
print('{} is a mega city'.format(city))
控制语句
For循环每次在序列中迭代一个元素。有时候可能要停止执行,或者跳过某部分。这时候可以使用break、continue、pass这三种语句。
break 停止循环并跳出。
for city in cities:
print(city)
if city == 'Los Angeles':
print('I found Los Angeles')
break
continue 跳过循环体内剩余部分直接进行下一部分迭代。
for city in cities:
if city == 'Los Angeles':
continue
print(city)
pass 语句什么都不做。这个在你需完成一些语法结构但还不希望任何代码执行的时候就很有用。一般用作未完成函数部分的占位符。
for city in cities:
if city == 'Los Angeles':
pass
else:
print(city)
练习
Fizz Buzz挑战。
写一个程序输出从1到100的数字,如果是3的倍数,就输出Fizz ,如果是5的倍数就输出Buzz。如果同时是3和5的倍数,就输出FizzBuzz。
输出应该如下所示:
1, 2, Fizz, 4, Buzz, Fizz, 7, 8, Fizz, Buzz, 11, Fizz, 13, 14, FizzBuzz, ...
将问题进一步拆解,需要创建下面几种条件的for循环:
- 如果一个数同时是3和5的倍数,输出FizzBuzz
- 如果一个数是3的倍数,输出Fizz
- 如果一个数是5的倍数,输出Buzz
- 其他情况输出这个数本身
提示:代码如下所示。这里要使用求余数运算符(modulus operator)%来验证一个数能不能被另一个数整除。比如10 % 5 等于0,余数为零,那就是能整除了。
for x in range(1, 10):
if x%2 == 0:
print('{} is divisible by 2'.format(x))
else:
print('{} is not divisible by 2'.format(x))
打开 05_functions.ipynb.
函数(Functions)
函数是一段代码,接受一个或多个输入inputs,进行一些内部处理,然后返回一个或多个输出outputs。函数内的代码只在函数被调用的时候才会被运行。(译者注:编程语言里的函数都是把重复使用的代码封装起来,有没有输入输出都可以;另外,python多个输出时其实也是一个元组tuple,无输出的时候可以看作是一个空的元组tuple。)
定义函数要使用def关键词,如下所示:
def my_function():
....
....
return something
函数非常有用处,可以让我们关注的代码的逻辑,然后每次用不同的输入来获得不同的输出,复用代码。
def greet(name):
return 'Hello ' + name
print(greet('World'))
函数可以接受多个参数(arguments)。接下来就写一个坐标单位转换的函数,将度分秒转换成十进制下的度。这个转换在处理收集的GPS位置数据的时候会经常用到。
- 1 度(degree) 等于 60 分钟(minutes)
- 1 分(minute)等于 60 秒(seconds)
要计算十进制的度,可以用下面的公式:
如果度数是正值:
十进制度 Decimal Degrees = 度degrees + (分minutes/60) + (秒seconds/3600)
如果度数是负值:
十进制度 Decimal Degrees = 度degrees - (分minutes/60) - (秒seconds/3600)
代码如下:
def dms_to_decimal(degrees, minutes, seconds):
if degrees < 0:
result = degrees - minutes/60 - seconds/3600
else:
result = degrees + minutes/60 + seconds/3600
return result
运行一下试试:
output = dms_to_decimal(10, 10, 10)
print(output)
练习
对任意一个度分秒的坐标值,调用上面的dms_to_decimal函数将其转换成十进制的度。
def dms_to_decimal(degrees, minutes, seconds):
if degrees < 0:
result = degrees - minutes/60 - seconds/3600
else:
result = degrees + minutes/60 + seconds/3600
return result
coordinate = '''37° 46' 26.2992"'''
# 在下面添加代码,从字符串中提取出坐标数值
# 然后调用函数将坐标转换成十进制度并打印输出
# 正确结果应该是 37.773972
# 提示:先将字符串转换成淑芝
# 当你直接从字符串中提取坐标的时候,提取到的是字符串
# 所以你需要使用内置的浮点数转换函数foat()来将其转换成数值
x = '25'
print(x, type(x))
y = int(x)
print(y, type(y))
打开 06_standard_library.ipynb.
Python 标准库(Standard Library)
Python 有内置的很多模块,提供了很多方便的功能,能解决各种常见变成问题。要使用这些模块,你必须用import来导入。导入到你的Python代码之后,就可以在你的代码中使用这个模块提供的函数了。
接下来用内置的数学模块math来演示如何使用复杂数学函数。
import math
你也可以只导入模块中的某个具体函数。
from math import pi
print(pi)
计算距离
给定2个经纬度坐标点,使用哈维辛方程(Haversine Formula)就可以算出两点之间的短程线距离,这里是假设地球是球形。
这个方程特别简单,可以在数据表格里直接写出来。如果你很好奇,也可以参考本文原作者之前的一篇文章来了解更多信息。
有了公式,就可以写一个函数,接收一对经纬度数值对,分别表示起点和终点坐标,然后计算出距离来。
san_francisco = (37.7749, -122.4194)
new_york = (40.661, -73.944)
def haversine_distance(origin, destination):
lat1, lon1 = origin
lat2, lon2 = destination
radius = 6371000
dlat = math.radians(lat2-lat1)
dlon = math.radians(lon2-lon1)
a = math.sin(dlat/2) * math.sin(dlat/2) + math.cos(math.radians(lat1)) \
* math.cos(math.radians(lat2)) * math.sin(dlon/2) * math.sin(dlon/2)
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
distance = radius * c
return distance
distance = haversine_distance(san_francisco, new_york)
print(distance/1000, 'km')
探索 Python 的彩蛋
程序员很喜欢在程序里面放一些菜单。Python就有一个彩蛋,就是导入模块this。
import this
Let’s try one more. Try importing the antigravity module.
再试试,还可以导入一个 antigravity 模块。
另外可以参考 Python 里的彩蛋列表。
练习
找两个你身边城市的位置坐标,然后计算两地之间的距离,使用下面的haversine_distance函数。
def haversine_distance(origin, destination):
lat1, lon1 = origin
lat2, lon2 = destination
radius = 6371000
dlat = math.radians(lat2-lat1)
dlon = math.radians(lon2-lon1)
a = math.sin(dlat/2) * math.sin(dlat/2) + math.cos(math.radians(lat1)) \
* math.cos(math.radians(lat2)) * math.sin(dlon/2) * math.sin(dlon/2)
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
distance = radius * c
return distance
# city1 = (lat1, lng1)
# city2 = (lat2, lng2)
# call the function and print the result
打开 07_third_party_modules.ipynb.
第三方模块
Python的第三方模块(也可以叫做库或者包)有一个非常繁荣的生态。有成千上万个第三方模块,你可以安装并使用。
安装第三方模块
Python的包管理器是pip。所有可安装的包都可以在 PyPI (Python Package Index)中找到。在终端中运行下面的命令就可以安装一个包了:
pip install <package name>
本文中使用的是Anaconda,也有自己的包管理器conda。可以使用Anaconda Navigator来安装,或者也可以运行下面的命令:
conda install <package name>
更多内容可以参考 pip 和 conda 的对比 。
计算距离
本文开头的时候,我们就已经安装了geopy这个包了。geopy可以利用很多已经实现的函数来计算距离。
distance.great_circle(): 使用哈维辛方程(haversine formula)计算大圆距离distance.geodesic(): 使用文森特方程(vincenty’s formula)计算所选的椭球提距离
from geopy import distance
san_francisco = (37.7749, -122.4194)
new_york = (40.661, -73.944)
straight_line_distance = distance.great_circle(san_francisco, new_york)
ellipsoid_distance = distance.geodesic(san_francisco, new_york, ellipsoid='WGS-84')
print(straight_line_distance, ellipsoid_distance)
练习
还是距离计算的练习,和之前不一样的是这次要用geopy库。
from geopy import distance
# city1 = (lat1, lng1)
# city2 = (lat2, lng2)
# call the geopy distance function and print the great circle and ellipsoid distance
打开 08_using_web_apis.ipynb.
使用网络接口(API)
API 是 Application Program Interface 的缩写,意思是应用程序接口,允许一个程序和另一个程序进行沟通。很多网站或者服务商都提供了API,允许以自动的方式查询信息。
对于地图绘制和空间分析的用途,使用API非常重要。很长时间以来,谷歌地图的API是网上最流行的API。API允许你向网络服务器查询和获取结果,而不需要下载数据或者在本地机器上运行计算。
空间分析领域使用API的常见场景包括:
- 获取方向、导航
- 路径最优化
- 地理位置编码(Geocoding)
- 下载数据
- 获取实时天气数据
- …
这类的API有很多种不同的实现。有的是一些标准,比如REST, SOAP, GraphQL等等。REST 是用于空间分析的最流行的网络API标准。REST 是用在HTTP协议上的,所以叫做网络接口。
理解 JSON 和 GeoJSON
JSON 是 JavaScript Object Notation 的缩写。这个文件格式是用来存储和传输数据的,也是接口之间进行数据传输的事实上的标准。GeoJSON就是对JSON格式的扩展,使之用于表征空间数据。
Python 有一个内置的json模块,内部的方法可以读取JSON并将其转化成Python对象,还可以反过来将Python对象存储成JSON文件。在这个例子中,我们使用requests 模块来查询接口来实现转化。Python中最基础的JSON方法也有必要学习一下。
GeoJSON 数据包含很多特征(features),其中每个特征都有若干属性(properties)和集合信息(geometry)。
geojson_string = '''
{
"type": "FeatureCollection",
"features": [
{"type": "Feature",
"properties": {"name": "San Francisco"},
"geometry": {"type": "Point", "coordinates": [-121.5687, 37.7739]}
}
]
}
'''
print(geojson_string)
使用json.loads() 方法可以将JSON字符串转换成Python对象(这也就是解析JSON)。
import json
data = json.loads(geojson_string)
print(type(data))
print(data)
现在就有了已经解析出来的GeoJSON字符串,以及一个Python对象,可以从中提取信息来。数据存储在特征集(FeatureCollection)中,也就是特征(features)组成的列表。在本文利自重,只有一个特征,所以使用索引0就可以获取到了。
city_data = data['features'][0]
print(city_data)
上述特征表示来一个字典,每个独立元素都可以使用键名keys来读取。
city_name = city_data['properties']['name']
city_coordinates = city_data['geometry']['coordinates']
print(city_name, city_coordinates)
requests模块
要向一个服务器查询(query),要发送一个GET请求,附加一些参数,然后服务器会发回一个响应(response)。requests允许用户这样发送HTTP请求以及使用Python将反馈信息解析出来。
服务器返回的信息包含的数据有HTTP状态码(status_code ),这个状态码来告诉用户请求是否成功。比如HTTP状态码200就表示成功(Sucess OK)。
import requests
response = requests.get('https://www.spatialthoughts.com')
print(response.status_code)
使用 OpenRouteService API 计算两点间距离
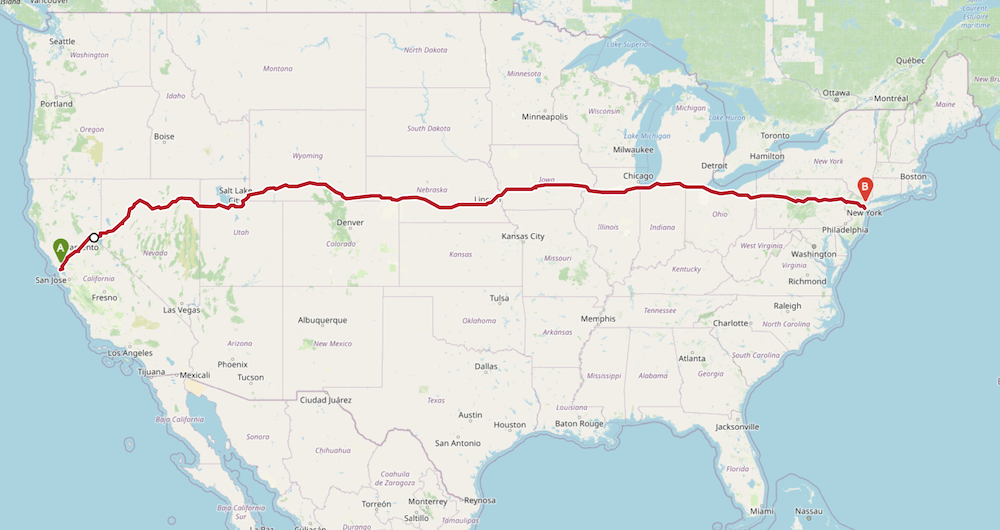
OpenRouteService (ORS) 提供了免费接口,可以用于路径规划和导航的、距离矩阵、地理编码、路径最优化等等。接下来我们既要学习通过Python来使用此接口,来获取现实世界中两个城市之间的距离。
几乎所有的接口都需要你登录,然后获得一个密钥key。这个密钥可以用来对你进行身份识别和资源限制,这样就不会有对服务的过度使用。对OpenRouteServie也是要先获取密钥然后再使用接口。
访问OpenRouteService Sign-up page 来注册一个账户。激活账户后,访问主页面获取一个密钥(token)。选择免费类型,然后输入python_foundation 作为密钥名。点击CREATE TOKEN。完成后,把显示出来的一大串字符串复制输入到下面的变量中。
ORS_API_KEY = '<replace this with your key>'
接下来要使用 OpenRouteServices 提供的 导航服务 Directions Service。这个服务反悔的是给定的起点和终点之间的驾驶、骑行或者步行的路径导航。
import requests
san_francisco = (37.7749, -122.4194)
new_york = (40.661, -73.944)
parameters = {
'api_key': ORS_API_KEY,
'start' : '{},{}'.format(san_francisco[1], san_francisco[0]),
'end' : '{},{}'.format(new_york[1], new_york[0])
}
response = requests.get(
'https://api.openrouteservice.org/v2/directions/driving-car', params=parameters)
if response.status_code == 200:
print('Request successful.')
data = response.json()
else:
print('Request failed.')
可以调用json()方法来读取JSON格式文件中的response。
data = response.json()
返回的是一个GeoJSON对象,表示的是两点之间的行驶方向。这个对象是一个特征集合,只有一个特征。可以使用索引0来读取。特征的属性包含了summary总结信息,这正是我们要用到的。
summary = data['features'][0]['properties']['summary']
print(summary)
提取出 distance 然后转换成公里为单位。
distance = summary['distance']
print(distance/1000)
可以将这个距离与上面的直线距离来对比一下,看看差别。
接口频率限制(API Rate Limiting)
很多网络接口都很重视频率限制(rate limiting),也就是单位时间内允许的访问数是有限的。有了计算机,很容易写一些for循环,或者同时开多个程序来发送请求,每秒可能成百上千。服务器可能应付不来这么大的访问量。所以提供商就指定了单位时间内的访问次数和每次访问之间的时间间隔。
OpenRouteService 列出了几条接口限制API Restrictions。免费用户最多允许每分钟40次导航请求。
很多库可以帮助实现访问频率的限制。但这里我们用一个内置的time模块来实现一个非常简单的频率控制方法就可以了。
time模块
Python标准库(Standard Library)内置了一个time模块,可以进行各种时间相关的运算。其中的一个方法time.sleep()可以在指定的时间内暂停程序执行。
import time
for x in range(10):
print(x)
time.sleep(1)
练习
下面的代码块中包含了一个字典,其中有三个目标城市及其坐标。写一个for循环来针对目标城市destination_cities这个字典进行循环,然后调用get_driving_distance()这个函数来输出从旧金山(San Fransico)到每个目标城市的真实驾驶距离。在每次成功的函数调用之间利用time.sleep(2)添加两秒休眠来限制查询频率。
import csv
import os
import requests
import time
ORS_API_KEY = '<replace this with your key>'
def get_driving_distance(source_coordinates, dest_coordinates):
parameters = {
'api_key': ORS_API_KEY,
'start' : '{},{}'.format(source_coordinates[1], source_coordinates[0]),
'end' : '{},{}'.format(dest_coordinates[1], dest_coordinates[0])
}
response = requests.get(
'https://api.openrouteservice.org/v2/directions/driving-car', params=parameters)
if response.status_code == 200:
data = response.json()
summary = data['features'][0]['properties']['summary']
distance = summary['distance']
return distance/1000
else:
print('Request failed.')
return -9999
san_francisco = (37.7749, -122.4194)
destination_cities = {
'Los Angeles': (34.0522, -118.2437),
'Boston': (42.3601, -71.0589),
'Atlanta': (33.7490, -84.3880)
}
打开 09_reading_files.ipynb.
读取文件(Reading Files)
Python提供了内置函数进行文件读写。
想要读取一个文件,就必须要知道它存储在磁盘的路径。Python内置一个 os 模块可以帮助解决操作系统方面的问题。使用 os 的一个好处就是你写的代码不用修改就可以在其支持的操作系统上运行。
import os
打开文件必须知道路径。假设要打开并读取文件worldcitites.csv,其位置就在你的数据包里面。在数据包文件夹内部他的位置是在data/这个文件夹下。就可以使用相对路径来访问,这里要用到os.path.join()方法。
data_pkg_path = 'data'
filename = 'worldcities.csv'
path = os.path.join(data_pkg_path, filename)
print(path)
打开文件要使用内置的open()函数。如果只需要只读模式,就可以设置参数 mode为r。如果要对文件进行修改或者写入一个新文静,就要在打开的时候设置参数mode为w.
本文用到的输入文件包含有Unicode字符,所以编码方式设置为UTF-8。
open()函数返回的是一个文件对象。可以调用readline()方法来对文件的内容进行逐行读取。
在用完了文件之后,一定要关闭,这是个好习惯。要关闭文件就必须要在文件对象上调用 close() 方法。
f = open(path, 'r', encoding='utf-8')
print(f.readline())
print(f.readline())
f.close()
对文件中的每一行分别调用readline()函数就太麻烦了。理想情况下,我们希望循环访问文件中的所有行。可以使用下面代码的方法来进行遍历。
可以对文件中的每一行进行循环,然后每次循环一行就在一个计数变量count上加一。这样在末尾,count这个变量的值就等于文件的行数了。
f = open(path, 'r', encoding='utf-8')
count = 0
for line in f:
count += 1
f.close()
print(count)
练习
打印输出文件的前五行。
- 提示:使用 break 语句
import os
data_pkg_path = 'data'
filename = 'worldcities.csv'
path = os.path.join(data_pkg_path, filename)
# 在此处添加代码来读取文件的前五行
打开 10_reading_csv_files.ipynb.
读取CSV(逗号分隔符)文件
CSV 是 Comma-separated Value 的缩写,意思是逗号分隔符,是一种很常用的文本文件格式,可以用于存储地理空间信息。文件中每行中的各个列(columns)都通过一个英文字符逗号(comma)来分隔开。(译者注:新手常犯的错误就是混用中英文标点符号,一定要记得CSV当中用的是英文字符的逗号,不是中文输入法下的中文逗号。实际上,推荐大家尽量在写代码的过程中一律使用英文字符的标点符号,这样能减少很多麻烦。)
一般来说,分隔的字符就叫做分隔符(delimiter)。除了逗号(comma)之外,还有其他分隔符:制表tab (\t)、冒号colon (:) 和 分号semi-colon (;) 。
正确地读取CSV文件需要先知道使用的是哪种分隔符,另外引号字符还将有空格的字段值包含起来。由于读取分隔符文件是很常用的操作,要处理各种稀奇古怪的情况又很麻烦,Python就提供了内置库csv来读取和写入CSV文件。导入一下就可以使用了。
import csv
这里推荐的一种读取CSV文件的方式是使用DictReader()方法。该方法直接读取每一行,从中创建一个字典,列名作为键名(key),列值作为键值(value)。接下来的代码是使用csv.DictReader()方法来读取一个文件。
import os
data_pkg_path = 'data'
filename = 'worldcities.csv'
path = os.path.join(data_pkg_path, filename)
f = open(path, 'r')
csv_reader = csv.DictReader(f, delimiter=',', quotechar='"')
print(csv_reader)
f.close()
使用枚举函数enumerate()
在对一个对象进行迭代的时候,经常要用到计数器。之前的例子中,我们使用了一个count变量,每次迭代都加一,以此来计数。有一种更简单的方法来实现这个目的,就是使用内置的enumerate()函数。
cities = ['San Francisco', 'Los Angeles', 'New York', 'Atlanta']
for x in enumerate(cities):
print(x)
可以在任何可迭代对象上使用enumerate()函数,然后得到一个元组,包含了一个索引和每次迭代值。接下来就用这个函数来输出DictReader对象的前五行。
f = open(path, 'r', encoding='utf-8')
csv_reader = csv.DictReader(f, delimiter=',', quotechar='"')
for index, row in enumerate(csv_reader):
print(row)
if index == 4:
break
f.close()
使用 with 语句
文件操作需要打开文件,对文件对象进行操作然后关闭文件。很烦的一个事,就是在代码结尾可能会忘掉调用close()。如果处理文件的代码遇到了文件未关闭的错误,就可能导致问题,尤其是写文件的时候。
解决这个问题的一个推荐办法就是使用with语句。得到的是更简单、简洁的代码,还确保了文件对象能够正确关闭,避免出错。
如下代码琐事,使用with语句打开文件得到文件对象f。Python就可以在代码执行完毕后自动关闭掉该文件。
with open(path, 'r', encoding='utf-8') as f:
csv_reader = csv.DictReader(f)
筛选行
对行迭代,使用条件语句,然后就可以选择和处理满足特定条件的行。假设要计算一下一个文件中有多少个城市属于某个特定国家。
在下面的代码中的home_country变量替换成任意国家。
home_country = 'Italy'
num_cities = 0
with open(path, 'r', encoding='utf-8') as f:
csv_reader = csv.DictReader(f)
for row in csv_reader:
if row['country'] == home_country:
num_cities += 1
print(num_cities)
计算距离
将目前所学都用到一个复杂问题场景。我们要读取CSV文件worldcities.csv,然后找到某个国家或地区的所有城市,计算一下从所有城市到某个城市的距离,并写出结果,保存成一个新的CSV文件。
首先从文件中找到所选的home_city的坐标值。然后将代码中的home_city替换成你感兴趣的城市地名。要注意这里使用的是city_ascii来进行城市名称对比,所以要确定home_city变量包含的是ASCII版本的城市名称。
home_city = 'Rome'
home_city_coordinates = ()
with open(path, 'r', encoding='utf-8') as f:
csv_reader = csv.DictReader(f)
for row in csv_reader:
if row['city_ascii'] == home_city:
lat = row['lat']
lng = row['lng']
home_city_coordinates = (lat, lng)
break
print(home_city_coordinates)
接下来就循环遍历文件,找到选中国家或地区的城市,然后调用geopy.distance.geodesic()函数来计算距离。在下面的代码样例中,只计算前面五对。
from geopy import distance
counter = 0
with open(path, 'r', encoding='utf-8') as f:
csv_reader = csv.DictReader(f)
for row in csv_reader:
if (row['country'] == home_country and
row['city_ascii'] != home_city):
city_coordinates = (row['lat'], row['lng'])
city_distance = distance.geodesic(
city_coordinates, home_city_coordinates).km
print(row['city_ascii'], city_distance)
counter += 1
if counter == 5:
break
写入文件
这次咱们不再使用打印输出,而是将得到的结果写入到一个新的文件里。读文件用的是csv.DictReader()方法,写文件就可以用csv.DictWriter()方法。创建一个csv_writer对象,然后使用writerow()方法按行写入。
首先创建一个output文件夹来保存结果。可以先检查一下这个文件夹是否存在,如果不存在就可以创建了。
output_dir = 'output'
if not os.path.exists(output_dir):
os.mkdir(output_dir)
output_filename = 'cities_distance.csv'
output_path = os.path.join(output_dir, output_filename)
with open(output_path, mode='w', encoding='utf-8') as output_file:
fieldnames = ['city', 'distance_from_home']
csv_writer = csv.DictWriter(output_file, fieldnames=fieldnames)
csv_writer.writeheader()
# Now we read the input file, calculate distance and
# write a row to the output
with open(path, 'r', encoding='utf-8') as f:
csv_reader = csv.DictReader(f)
for row in csv_reader:
if (row['country'] == home_country and
row['city_ascii'] != home_city):
city_coordinates = (row['lat'], row['lng'])
city_distance = distance.geodesic(
city_coordinates, home_city_coordinates).km
csv_writer.writerow(
{'city': row['city_ascii'],
'distance_from_home': city_distance}
)
下面的是读取、筛选、计算距离并写入结果到文件的完整代码。
import csv
import os
from geopy import distance
data_pkg_path = 'data'
input_filename = 'worldcities.csv'
input_path = os.path.join(data_pkg_path, input_filename)
output_filename = 'cities_distance.csv'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
if not os.path.exists(output_dir):
os.mkdir(output_dir)
home_city = 'Bengaluru'
home_country = 'India'
with open(input_path, 'r', encoding='utf-8') as input_file:
csv_reader = csv.DictReader(input_file)
for row in csv_reader:
if row['city_ascii'] == home_city:
home_city_coordinates = (row['lat'], row['lng'])
break
with open(output_path, mode='w') as output_file:
fieldnames = ['city', 'distance_from_home']
csv_writer = csv.DictWriter(output_file, fieldnames=fieldnames)
csv_writer.writeheader()
with open(input_path, 'r', encoding='utf-8') as input_file:
csv_reader = csv.DictReader(input_file)
for row in csv_reader:
if (row['country'] == home_country and
row['city_ascii'] != home_city):
city_coordinates = (row['lat'], row['lng'])
city_distance = distance.geodesic(
city_coordinates, home_city_coordinates).km
csv_writer.writerow(
{'city': row['city_ascii'],
'distance_from_home': city_distance}
)
print('Successfully written output file at {}'.format(output_path))
练习
将home_city和home_country变量设成某个城市和国家地区,然后创建一个某国家或地区的某城市到其他城市距离列表的CSV文件。
打开 11_working_with_pandas.ipynb.
使用Pandas
![]()
Pandas 是一个非常强大的数据处理库,提供了简便高效的函数来读取和分析文件中的数据。
Pandas 基于另一个库numpy,也广泛用于科学计算。Pandas扩展了numpy,提供了新的数据类型,比如Index、Series 和 DataFrames。
Pandas的实现非常快速高效,和其他数据处理方法相比,使用pandas能够让代码更简单快速。接下来将上面的文件读取和距离计算的代码用Pandas重新实现一下。
按照惯例,一般将pandas导入简化成pd。
import pandas as pd
读取文件
import os
data_pkg_path = 'data'
filename = 'worldcities.csv'
path = os.path.join(data_pkg_path, filename)
DataFrame是最常用的Pandas对象。可以将一个Pandas对象看作是一个数据表(Spreadsheet)或者GIS涂层上的一个属性表格(Attribute Table)。
Pandas提供了直接读取文件生成DataFrame的简单方法。可以使用read_csv()、read_excel()、read_hdf()等来读取各种格式的文件。这里我们使用read_csv()来读取worldcitites.csv文件。
df = pd.read_csv(path)
文件读取后,DataFrame对象创建,然后可以使用head()方法来看一下简要信息。
print(df.head())
另外还有一个info()方法也能介绍一个DataFrame的基本信息,比如行列书以及每一列的数据类型等等。
print(df.info())
筛选数据
Pandas有很多从一个DataFrame来选择和筛选数据的方法。接下来试试如何使用布尔筛选 Boolean Filtering来筛选出满足条件的行。
home_country = 'Canada'
filtered = df[df['country'] == home_country]
print(filtered)
筛选出来的DataFrame只是对原始数据的一个呈现,还不能对其进行修改。可以将筛选出来的数据使用copy()方法存到一个新的DataFrame中。
country_df = df[df['country'] == home_country].copy()
要定位到一个DataFrame中的某个行列位置,可以使用Pandas提供的loc[]和iloc[]方法,就可以定位到特定的数据切片。Pandas里面还有更多的索引方法 。这里使用iloc[] 来寻找home_city匹配的某一行。由于iloc[]使用索引,0表示的就是第一行。
home_city = 'Rome'
filtered = country_df[country_df['city_ascii'] == home_city]
print(filtered.iloc[0])
现在就将数据筛选出单独一行来,可以再用列名来选择单独的某个值。
home_city_coordinates = (filtered.iloc[0]['lat'], filtered.iloc[0]['lng'])
print(home_city_coordinates)
运行计算
接下来试试在一个DataFrame上进行计算。我们可以对每一行进行迭代然后运行一些计算。实际上Pandas还提供了更简单的方法。可以使用apply() 方法来对每一行运行一个函数。这样速度更快,也是的在大数据集上进行复杂运算更加容易。
apply()函数接收两个参数。一个是要应用的函数,另一个是对应的轴方向。比如axis=0意思是对每一列运行,而axis=1则表示应用到各行。
from geopy import distance
def calculate_distance(row):
city_coordinates = (row['lat'], row['lng'])
return distance.geodesic(city_coordinates, home_city_coordinates).km
result = country_df.apply(calculate_distance, axis=1)
print(result)
将这些结果放到新的列当中就可以存进DataFrame中了。
country_df['distance'] = result
print(country_df)
现在就完成分析,可以存储结果了。接下来可以筛选结果到特定的几列。
filtered = country_df[['city_ascii','distance']]
print(filtered)
将city_ascii 列重命名一个更可读的名字。
filtered = filtered.rename(columns = {'city_ascii': 'city'})
print(filtered)
现在就有了筛选的原始数据和计算出来的所有城市距离,可以将得到DataFrame存储到一个文件中。和读取的方法类似,Pandas也有几个写入文件的方法,比如to_csv()、to_excel()等等。
这里我们使用to_csv()方法将数据写到一个CSV文件中。Pnadas会默认给DataFrame添加一个索引列(一系列不同的整数值)。可以设置index=False来避免添加索引列。
output_filename = 'cities_distance_pandas.csv'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
filtered.to_csv(output_path, index=False)
print('Successfully written output file at {}'.format(output_path))
练习
你会发现,输出的文件也有一行home_city。修改filtered就可以移除这一行,然后输出到文件中。
提示:使用之前学到的布尔筛选方法可以选择不符合home_city的行。
使用 Geopandas

GeoPandas扩展了Pandas库,增加了空间分析操作,还提供了新的数据类型,比如GeoDataFrame和GeoSeries分别是DataFrame和Series的子类 ,允许用Python进行向量数据的高效处理。
GeoPandas使用了很多其他广泛应用的空间分析库,但提供了和Pandas相似的洁面,因此很容易用来进行空间分析。GeoPandas基于下面这些库。
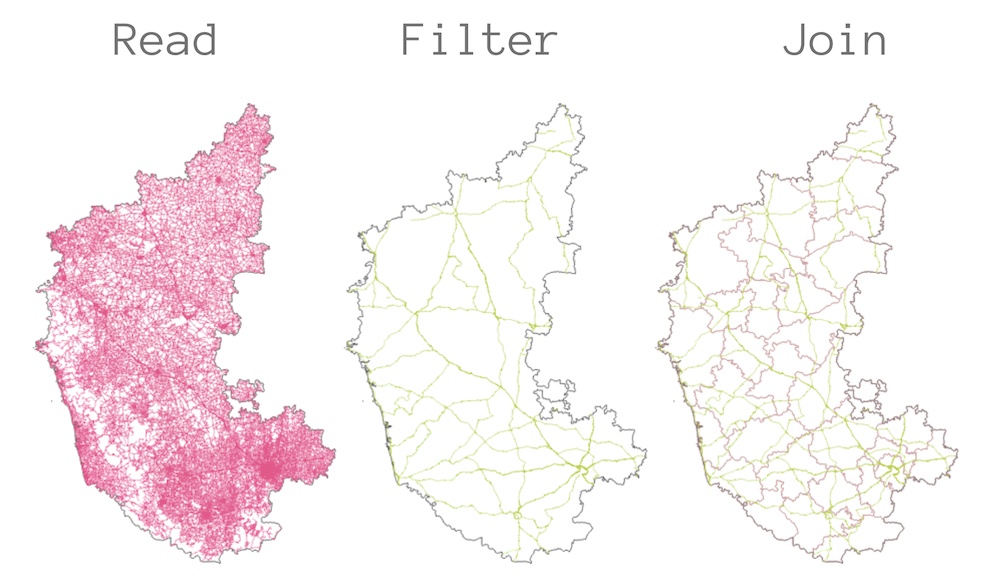
接下来会进行一个地理信息处理任务,利用GeoPandas这一库的各种功能,同时实现在Python中的地理信息数据处理过程。这个任务就是从 OpenStreetMap and中选择一个道路数据涂层,然后计算出一个州内每个区范围内的国家高速公路的总长度。这个问题的详细描述可以参考原作者的另一个课程 Advanced QGIS 中,里面记录了使用QGIS进行这项工作的步骤。在这个例子中,我们用Python来实现。
根据惯例,geopandas一般被导入作为gpd。
import geopandas as gpd
读取空间数据
import os
data_pkg_path = 'data'
filename = 'karnataka.gpkg'
path = os.path.join(data_pkg_path, filename)
GeoPandas有一个read_file()方法可以读取各种各样的矢量数据集,包括zip文件等等。这里我们打开一个GeoPackage文件karnataka.gpkg,然后读取其中一个叫作`karnataka_major_roads的涂层。读取方法所得到的结果就是一个GeoDataFrame对象。
roads_gdf = gpd.read_file(path, layer='karnataka_major_roads')
print(roads_gdf.info())
一个GeoDataFrame包含了一个特殊列叫做geometry。在GeoDataFrame中所有的空间运算都要应用到geometry列。geometry列可以使用geometry参数进行读取。
print(roads_gdf.geometry)
筛选数据
对GeoDataFrame,可以使用标准的Pandas筛选方法来选择一个子集。另外,GeoPandas还提供了cx[] indexer索引来获得数据子集的方式。
本次练习中,需要提取出ref属性开头为‘NH’的道路片段,也就是国家级高速公路。搭配正则表达式来使用Pandas中的str.match()方法可以应用布尔筛选。
filtered = roads_gdf[roads_gdf['ref'].str.match('^NH') == True]
print(filtered.head())
处理投影
处理投影是空间数据分析的关键。GeoPandas使用的是pyproj库来进行投影。每个GeoDataFrame都有一个crs属性,包含的就是投影信息。我们这里用到的数据集使用的是EPSG:4326 WGS84坐标参考系(CRS)。
print(filtered.crs)
由于我们的任务是计算线条长度,就需要用到投影的坐标参考系。这里可以使用to_crs()方法来讲GeoDataFrame进行再次投影。
roads_reprojected = filtered.to_crs('EPSG:32643')
print(roads_reprojected.crs)
现在图层已经重新投影了,就可以利用length属性来计算每个几何体的长度了。结果单位是米。可以将线条长度存放在一个名为length的新列中。
roads_reprojected['length'] = roads_reprojected['geometry'].length
也可以对DataFrame列进行空间运算。这里调用sum()方法来计算某个州中的国家高速公路的总长度。
total_length = roads_reprojected['length'].sum()
print('Total length of national highways in the state is {} KM'.format(total_length/1000))
进行空间连接
在GeoPandas中有两种方法连接数据集,表连接(table joins)和空间连接(spatial joins)。对我们的这次练习,需要每个路段所属的区域信息。这可以通过另一个空间层实现,进行空间连接来将区域图层的属性转移至道路段图层。
文件karnataka.gpkg包含一个名为karnataka_districts的涂层,里面有区域边界和名称。
districts_gdf = gpd.read_file(path, layer='karnataka_districts')
print(districts_gdf.head())
在将该图层连接到道路图层之前,必须要对其进行重投影,使之匹配道路图层的坐标参考系。
districts_reprojected = districts_gdf.to_crs('EPSG:32643')
空间连接可以通过 sjoin()方法来实现,这个方法接收两个核心参数。
op: 空间动作(spatial predicate),决定要连接的对象。选项包括intersects、within、contains(交叉、在内、包含)。how: 连接的类型。选项包括left、right、inner(左、右、内)。
本次练习中,使用的是left连接,op选择为intersect将区的属性与道路交叉。
joined = gpd.sjoin(roads_reprojected, districts_reprojected, how='left', op='intersects')
print(joined.head())
分组统计(Group Statistics)
所得到的GeoDataFrame现在就有了对应的交叉区域特征的列。现在可以将道路长度加起来,然后按照区进行分组。这可以使用Pandas的group_by()方法来进行分组统计(Group Statistics)。
results = joined.groupby('DISTRICT')['length'].sum()/1000
print(results)
group_by()的方法得到的结果是一个Pandas的系列Series数据类型。可以使用to_csv()方法将其存储成CSV文件。
output_filename = 'national_highways_by_districts.csv'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
results.to_csv(output_path)
print('Successfully written output file at {}'.format(output_path))
练习
在将输出数据写入到文件之前,先要将距离数据四舍五入成为整数。
打开 13_creating_spatial_data.ipynb.
创建空间数据
空间分析中一种常见的操作就是读取非空间数据,比如CSV文件,然后使用文件中的坐标信息创建一个空间数据集。GeoPandas提供了从分隔符文本文件创建几何体并将结果写入到空间数据集的便利方法。
接下来读取一个制表符分隔的地名文本,然后筛选出特征累,创建一个GeoDataFrame,并导出成一个GeoPackage文件。
import os
import pandas as pd
import geopandas as gpd
data_pkg_path = 'data/geonames/'
filename = 'US.txt'
path = os.path.join(data_pkg_path, filename)
读取制表符分隔文件(Tab-Delimited Files)
本次练习使用的源数据来自GeoNames,这是一个自由开放的世界地名数据库。这个数据库非常庞大,每个国家都包含了上百万条记录。这个数据的发布形式是按照国家或地区区分的文本文档,使用制表符进行分隔。这些文件不包含带有列名的首行,所以需要在读取数据的时候指定各列的名字。数据格式的具体信息可以参考Data Export页面。
真对该数据,要使用 \t 作为参数来调用read_csv()方法。要注意文件体积可能比较大,比如美国的数据就有超过两百万条。
column_names = [
'geonameid', 'name', 'asciiname', 'alternatenames',
'latitude', 'longitude', 'feature class', 'feature code',
'country code', 'cc2', 'admin1 code', 'admin2 code',
'admin3 code', 'admin4 code', 'population', 'elevation',
'dem', 'timezone', 'modification date'
]
df = pd.read_csv(path, sep='\t', names=column_names)
print(df.info())
筛选数据
输入数据中有一列feature_class将地名分为9 个特征类。可以选择所有值为T的行,类别为mountain,hill,rock…等等。
mountains = df[df['feature class']=='T']
print(mountains.head()[['name', 'latitude', 'longitude', 'dem','feature class']])
创建几何体
GeoPandas有一个很方便的points_from_xy()函数,可以使用X和Y坐标创建一个几何体列。由此可以接收一个Pandas的DataFrame,然后创建一个GeoDataFrame,带有指定的坐标参考系(CRS)和几何体列。
geometry = gpd.points_from_xy(mountains.longitude, mountains.latitude)
gdf = gpd.GeoDataFrame(mountains, crs='EPSG:4326', geometry=geometry)
print(gdf.info())
写入文件
可以将上面的道德GeoDataFrame写入成任何支持的矢量文件格式。这里将其存储成 GeoPackage文件。
然后可以在GIS软件中打开所得到的GeoPackage文件,然后查看数据。
output_dir = 'output'
output_filename = 'mountains.gpkg'
output_path = os.path.join(output_dir, output_filename)
gdf.to_file(driver='GPKG', filename=output_path, encoding='utf-8')
print('Successfully written output file at {}'.format(output_path))
练习
数据文件中的geonames/文件夹中包含了多个国家的不同的地名文本文件。写代码读取所有文件,将其合并在一起,然后提取所有山地特征(mountain)到一个单独的GeoPackage文件。
- 提示1: 使用
os.listdir()方法来获得一个路径中的所有文件。 - 提示2: 使用Pandas的方法
concat()来合并多个DataFrame。
import os
import pandas as pd
import geopandas as gpd
data_pkg_path = 'data/geonames/'
files = os.listdir(data_pkg_path)
filepaths = []
for file in files:
filepaths.append(os.path.join(data_pkg_path, file))
print(filepaths)
# 迭代所有文件,使用Pandas读取然后创建DataFrame列表。
# 然后使用pd.concat()函数进行合并
打开 14_introduction_to_numpy.ipynb.
NumPy 简介

NumPy (Numerical Python)是一个用于科学计算的重要的Python库。Pandas和GeoPandas这样的库都基于NumPy。
NumPy提供了处理数组Arrays的快速高效方式。在空间数据分析领域中,NumPy在处理卫星图像、航拍照片、高程数据等栅格数据(Raster data)的时候发挥了重要作用。由于这些栅格数据是每个通道二维数组的结构,所以学习NumPy对于使用Python来处理栅格数据来说也是至关重要的。
按照惯例,numpy一般被导入为np。
import numpy as np
数组(Arrays)
NumPy的数据对象叫做ndarray。这一数据类型提供了很多支持函数,处理数组又快又方便。数组(Array)和Python的列表很相似,但ndarray在数学运算上至少要更快50倍。可以使用array()方法来创建一个数组。得到的对象就是numpy.ndarray。
a = np.array([1, 2, 3, 4])
print(type(a))
数组可以有任意的维度dimensions。下面的代码是创建一个二维数组。ndarray对象的属性ndim存储的就是数组维度数。另外也可以使用shape属性来查看数组尺寸。
b = np.array([[1, 2, 4], [3, 4, 5]])
print(b)
print(b.ndim)
print(b.shape)
可以像Python的列表一样使用方括号[]来读取数组中的元素。
print(b[0])
print(b[0][2])
数组运算(Array Operations)
NumPy数组上的数学运算方便又快捷。NumPy有很多内置函数可以用于常见运算。
print(np.sum(b))
数组上还能使用很多函数运算。
c = np.array([[2, 2, 2], [2, 2, 2]])
print(np.divide(b, c))
如果对象是NumPy对象,也可以使用Python的运算符。
print(b/c)
另外可以将数组和标量对象(Scalar objects)联合起来。标量运算将应用到数组的每个元素上。
print(b)
print(b*2)
print(b/2)
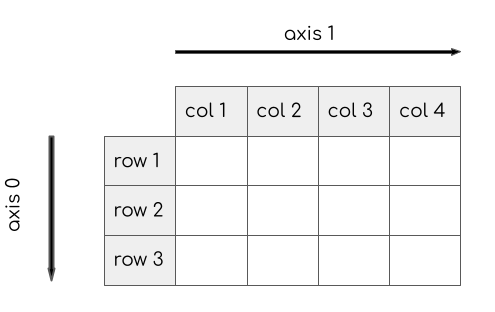
NumPy的一个重要概念就是数组轴(Array Axes)。和pandas库类似,在二维数组中,0轴是行方向,1轴是列方向。下图展示的就是数组轴方向。
接下来看看如何针对某个指定轴应用一个函数。这里对一个二维数组的0轴应用sum 函数,得到的是一个一维数组,数组值是各行的求和。
print(b)
row_sum = b.sum(axis=0)
print(row_sum)
练习
将数组b沿着1轴求和。你认为结果是什么?
import numpy as np
b = np.array([[1, 2, 4], [3, 4, 5]])
print(b)
打开 15_working_with_rasterio.ipynb.
使用 RasterIO
RasterIO是一个用于处理网格格式的地理空间数据的第三方库。该库提供了一个用于读写栅格数据的简单方式,也可以读取各波段数据,将像素作为numpy数组。
RasterIO基于流行的地理空间数据抽象库 GDAL (Geospatial Data Abstraction Library)。GDAL是用C++写的,所以其提供的Python接口对Python用户来说挺难适应。RasterIO的目的是让Python用户以更符合直觉的方式来使用GDAL库。
在这部分中,我们使用珠穆朗玛峰附近的四个SRTM地图切片,然后使用RasterIO将其合并在一个单独的GeoTiff文件。

import rasterio
import os
data_pkg_path = 'data'
srtm_dir = 'srtm'
filename = 'N28E087.hgt'
path = os.path.join(data_pkg_path, srtm_dir, filename)
读取栅格数据
RasterIO可以读取任何GDAL支持的栅格数据文件。可以对栅格数据文件路径调用open()函数来打开。得到的数据集就像是一个Python里面的文件对象。
dataset = rasterio.open(path)
使用meta属性可以读取栅格数据的更多信息。
数据集的变换(transform)是一种重要属性。这个属性包含了数据集的像素分辨率以及数据集左上角的行列坐标值。
metadata = dataset.meta
metadata
要读取像素质,需要调用read()方法,传递通道索引值。按照GDAL管理,通道数是从1开始索引的。由于我们的数据集只有一个通道,所以可以按照如下的方法来读取。
band1 = dataset.read(1)
print(band1)
最终,数据集处理完毕了,就必须关闭掉。这在写数据的时候非常重要。
dataset.close()
合并数据集
接下来我们来看看如何将四个地图切片拼接到一起。RasterIO提供了用于栅格数据运算的很多子模块。这次可以使用rasterio.merge模块来进行合并运算。
我们首先使用os.listdir()函数查看目录下的所有文件。
srtm_path = os.path.join(data_pkg_path, 'srtm')
all_files = os.listdir(srtm_path)
print(all_files)
rasterio.merge模块有一个merge()方法,接收一个数据集列表,返回合并的数据集。所以茶u你国军爱你一个空列表,然后打开每个文件,将其添加到列表中。
dataset_list = []
for file in all_files:
path = os.path.join(srtm_path, file)
dataset_list.append(rasterio.open(path))
print(dataset_list)
我们可以将地图切片数据集的列表传递给合并方法,然后得到合并后的数据和一个新的变换(transform),其中包含着合并后栅格数据的更新范围。
from rasterio import merge
merged_result = merge.merge(dataset_list)
print(merged_result)
然后将数据和变换保存成不同的变量。
merged_data = merged_result[0]
merged_transform = merged_result[1]
打印输出一下合并数据的形状,验证一下是否是各个栅格数据的总和。
print(merged_data.shape)
写入栅格数据
和常规Python文件类似,要建立新文件,还是要用write模式打开输出的文件。RasterIO提供了一个write()方法,可以用于将各个通道写入到文件。
output_filename = 'merged.tif'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
对输出的数据集,要设置很多元数据参数来初始化。一些参数值可以直接从输入文件中复制,比如crs、dtype、nodata等,而其他的就需要从合并的数据集里面来获取,比如高度height和宽度width。
一定要记得在完成文件并写入到磁盘后,要调用close()方法来关闭文件。
new_dataset = rasterio.open(output_path, 'w',
driver='GTiff',
height=merged_data.shape[1],
width=merged_data.shape[2],
count=1,
nodata=-32768.0,
dtype=merged_data.dtype,
crs='+proj=latlong',
transform=merged_transform)
new_dataset.write(merged_data)
new_dataset.close()
print('Successfully written output file at {}'.format(output_path))
练习
合并的数组表示的是高程值。地图切片的范围覆盖了珠穆朗玛峰范围。读取得到的栅格数据,找到其中的最大高程。
import rasterio
import os
import numpy as np
output_filename = 'merged.tif'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
# 将输出文件读取为NumPy数组然后找到最大值
写独立的Python脚本
目前我们都是在Jupyter Notebooks中编写和执行Python代码。这对于交互式探索、可视化和记录工作流都是很好的选择。但这并不适合编写自动化脚本。如果有需要长期运行的任务或者某种日程化的运行任务,就必须要将代码脚本写成一个单独的.py文件,然后在终端中运行。
使用文本编辑器
软件开发总是需要有合适的文本编辑器。如果你已经有喜欢的文本编辑器或者一个集成开发环境(Integrated Development Environment,缩写为IDE),你就可以用自己喜欢的选择。另外,各平台都有各种文本编辑器,选择符合你需求的即可。
推荐给新手的文本编辑器是 VS Codium 是一个自由的开源版本的VS Code,基本上和VS Code功能都差不多,体验也基本一样,能安装各种插件等等。
写一个脚本
将下面的代码复制粘贴到你的文本编辑器,保存到数据包文件夹,存储为get_distance.py。一定要注意扩展名,要保存成.py。
from geopy import distance
san_francisco = (37.7749, -122.4194)
new_york = (40.661, -73.944)
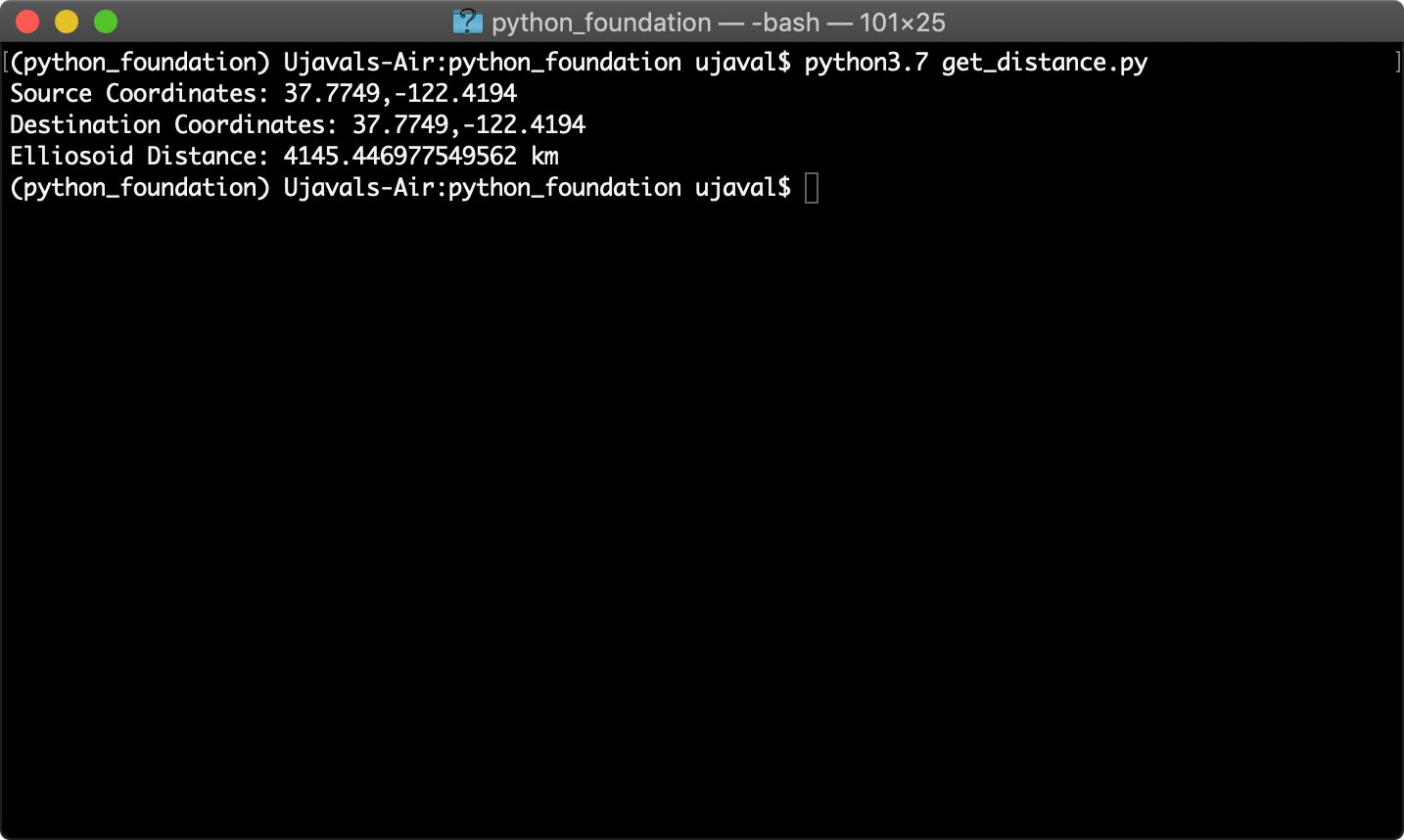
ellipsoid_distance = distance.geodesic(san_francisco, new_york, ellipsoid='WGS-84').km
print('Source Coordinates: {},{}'.format(san_francisco[0], san_francisco[1]))
print('Destination Coordinates: {},{}'.format(san_francisco[0], san_francisco[1]))
print('Elliosoid Distance: {} km'.format(ellipsoid_distance))
运行脚本
Windows
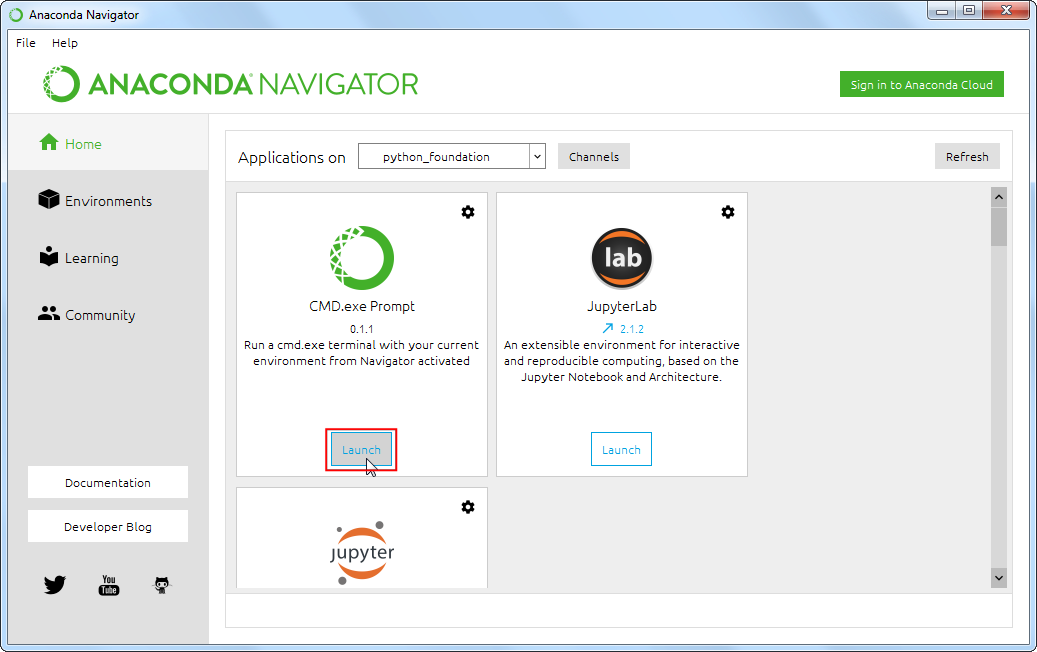
- 运行 Anaconda Navigator 程序。选择
python_foundation环境,然后运行CMD.exe Prompt程序。
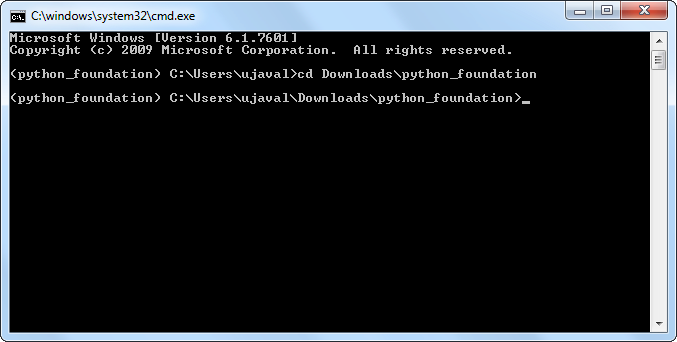
- 定位到包含脚本的文件夹,使用
cd命令。
cd Downloads\python_foundation
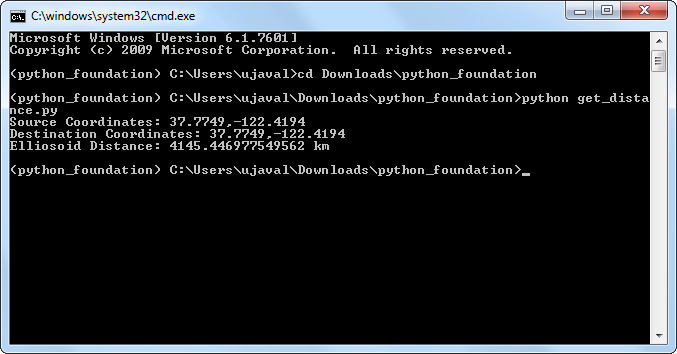
- 使用
python命令来运行脚本,脚本会输出计算出的距离。
python get_distance.py
macOS 和 Linux
- 打开终端(Terminal)。
- 切换到当前的conda环境。
conda activate python_foundation
- 定位到包含脚本的文件夹,使用
cd命令。
cd Downloads/python_foundation
- 使用
python命令来运行脚本,脚本会输出计算出的距离。如果你的系统安装了多个Python,就需要选择正确的Python实例。
python get_distance.py
接下来呢?
想要精通变成,就要联系写代码,解决各种问题。强烈推荐读者选一个项目,然后利用Python来实现,以此来提升技能。另外也可以看看其他课程来学习Python和空间数据处理。
做项目
下面推荐一些适合新手的项目,这些项目虽然简单,也还是有点挑战性。可以从中选择一个喜欢的来上手试试。
- 地理信息编码 Geocoding: 找一系列的地址列表,然后对其进行地理信息编码,创建一个点图层,可以参考 geocoding using geopy。
- 网络分析 Network Analysis: 使用osmnx 包来利用OpenStreetMap数据使用Python进行网络分析。开始以参考此处的例子。
- 可视化和交互地图: 使用投图库geoplot或者地图绘制库folium 来创建一个交互地图。可以参考此处的例子。
- 地理信息处理 Geo-processing: 之前有若干中级水平的地理信息处理的简介,使用的是QGIS。可以参考下面链接中的教程,然后用geopandas和rasterio这两个库来实现。
另外还可以参考有用的Python地理信息系统库 。
持续学习
接下来的事一些推荐的课程,你可以在学完本课程后继续学习。
- 赫尔辛基大学(University of Helsinki)的免费Geo-Python 课程;
- 赫尔辛基大学(University of Helsinki)的免费自动化地理信息系统处理课程;
- Kaggle的免费Python 课程,其中还包含了地理空间数据分析课程;
- Allen Downey 的免费数据科学基础课程;
- 使用Python进行地理信息处理在线课程,这其中有更多的地理空间数据分析库,主要使用OGC服务和元数据。
补充信息
使用GeoPandas创建地图
GeoPandas有一些内置的函数可以对地理空间数据进行可视化以及建立地图。实际上使用的是强大的matplotlib库来进行投图的。如果你对matplotlib不太熟悉,可以参考相关导论。
这里使用来自GeoPandas练习的数据进行可视化。
import geopandas as gpd
import os
data_pkg_path = 'data'
filename = 'karnataka.gpkg'
path = os.path.join(data_pkg_path, filename)
districts = gpd.read_file(path, layer='karnataka_districts')
roads = gpd.read_file(path, layer='karnataka_major_roads')
national_highways = roads[roads['ref'].str.match('^NH') == True]
Matplotlib 基础
在 Jupyter Notebook 内使用matplotlib 之前,要先设置matplotlib的 backend为inline,也就是在代码块之间现实出图。对此,要使用magic function %matplotlib。
%matplotlib inline
import matplotlib.pyplot as plt
要理解下面的两个matplotlib对象:
- Figure: 这就是投图plot的主容器。一个Figure可以包含多个Plot。
- Axes: Axes表示的是一个独立的Plot或者图(Graph),一个Figure可以包含1个或多个Axes。
现在就可以创建一个有多个axes的figure了,每个axes都在地图图层上有各自的渲染。
渲染地图输出
subplots()函数在一个figure内创建一个或多个plots。可以设计一个多行多列的地图。在下面的代码中,创建的是一行三列的地图。使用了set_size_inches()函数将地图的规格设置为15 x 7英寸。
fig, axes = plt.subplots(1, 3)
fig.set_size_inches(15,7)

subplots() 返回两个项目。一个是图,另一个是figure内所有axes组成的远足。由于我们有三个axes,就将它们解包获得分开的几个变量。
ax0, ax1, ax2 = axes
GeoDataFrame对象有一个plot()方法,使用的是pyplot来创建投图。这里将ax对象传递给函数,然后得到的投图结果就会显示在前面创建的Axes上来。这里添加districts多边形图层到ax0对象中,也就是第一个subplot。
districts.plot(ax=ax0, linewidth=1, facecolor='none', edgecolor='#252525')
fig
<Figure size 432x288 with 0 Axes>
与上面类似,接下来在第二个axes上添加roads图层。
roads.plot(ax=ax1, linewidth=0.4, color='#2b8cbe')
fig
<Figure size 432x288 with 0 Axes>
接下来,在第三个axes上添加national_highways图层。
national_highways.plot(ax=ax2, linewidth=1, color='#de2d26')
fig
<Figure size 432x288 with 0 Axes>
可以使用plt.axis('off')来关闭X轴和Y轴上的坐标显示。另外可以给每个地图使用set_title()函数来添加对应的标题。设置一个负值的y参数来将标题放在地图下面。
ax0.axis('off')
ax0.set_title('Karnataka Districts', y=-0.1)
ax1.axis('off')
ax1.set_title('Karnataka Major Roads', y=-0.1)
ax2.axis('off')
ax2.set_title('Karnataka National Highways', y=-0.1)
fig
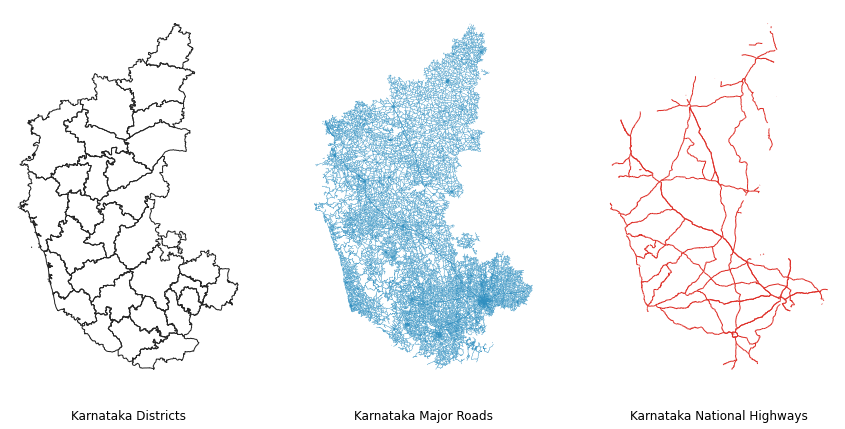
现在地图就完成了,可以使用savefig()函数将地图保存到电脑中。
output_filename = 'map_layout.png'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
if not os.path.exists(output_dir):
os.mkdir(output_dir)
fig.savefig(output_path, dpi=300)
创建多层地图
如果要先十多个图层,就可以在同一个Axes上创建新的plots。这里创建一个单个axes的figure,然后在同一个axes上添加districts、roads、 national_highways。
fig, ax = plt.subplots()
fig.set_size_inches(10,15)
plt.axis('off')
districts.plot(ax=ax, linewidth=1, facecolor='none', edgecolor='#252525')
roads.plot(ax=ax, linewidth=0.4, color='#2b8cbe')
national_highways.plot(ax=ax, linewidth=1, color='#de2d26')
output_filename = 'multiple_layers.png'
output_path = os.path.join(output_dir, output_filename)
plt.savefig(output_path, dpi=300)
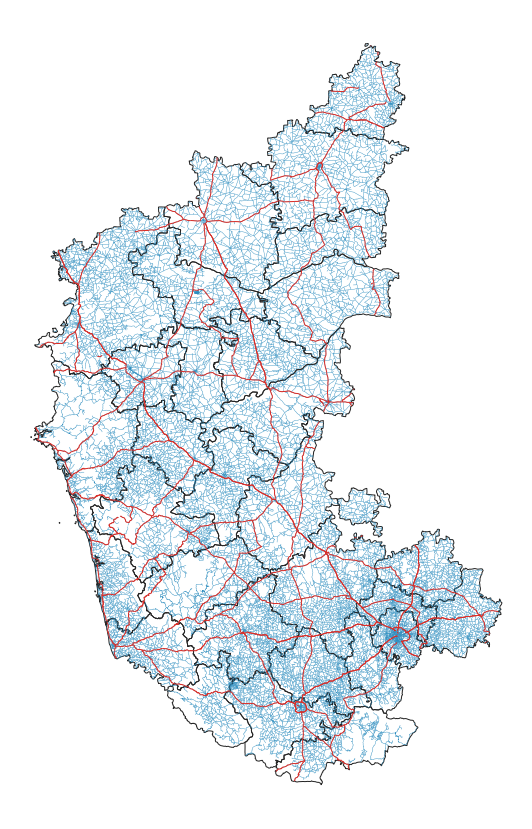
标注特征
还可以在地图上增加标注,不过这就需要一点预处理。假如要给每个行政区多边形家上标注。首先,需要确定好标签的锚定位置。可以使用representative_point()来得到每个多边形内的一个最能代表该几何形状的点。这和找中心(centroid)类似,但能够保证在多边形内不。下面的代码就在GeoDataFrame内创建了一个名为label_position的新域,存储的就是锚定点的坐标。
districts['label_position'] = districts['geometry'].apply(lambda x: x.representative_point().coords[:])
districts['label_position'] = [coords[0] for coords in districts['label_position']]
然后可以使用annotate()函数来对每个多边形进行迭代,从DISTRICT列中添加对应的行政区名,对应的位置就是label_position列的坐标。
fig, ax = plt.subplots(figsize=(10, 15))
plt.axis('off')
districts.plot(ax=ax, linewidth=1, facecolor='none', edgecolor='#252525')
for idx, row in districts.iterrows():
plt.annotate(text=row['DISTRICT'], xy=row['label_position'], horizontalalignment='center')

使用Xarray
Xarray 是改进版的rasterio,收到pandas等用于处理栅格数据的库的启发。特别适合处理多维度的时序的栅格数据( multi-dimensional time-series raster datasets)。还和dask紧密结合,支持使用并行计算来将栅格数据处理规模化。
rioxarray是对xarray的扩展,使之更适合用于地理空间栅格数据。可以使用conda-forge或者pip来安装rioxarray.
使用 RasterIO 的练习展示了如何重现相关分析,也介绍了使用matplotlib的栅格数据可视化。
XArray 和 rioxarray 基础
开视线读取一个单独的SRTM tile切片文件,其中包含着高程数据。
import os
data_pkg_path = 'data'
srtm_dir = 'srtm'
filename = 'N28E087.hgt'
path = os.path.join(data_pkg_path, srtm_dir, filename)
按照惯例,rioxarray导入为rxr。
import rioxarray as rxr
open_rasterio()方法可以用于读取任何rasterio库支持的数据格式。
rds = rxr.open_rasterio(path)
得到的就是一个xarray.DataArray对象。
type(rds)
xarray.core.dataarray.DataArray
可以使用values属性来读取每个像素的值,返回的是一个numpy数组。
rds.values
array([[[5217, 5211, 5208, ..., 5097, 5098, 5089],
[5206, 5201, 5200, ..., 5080, 5075, 5069],
[5199, 5194, 5191, ..., 5063, 5055, 5048],
...,
[5347, 5345, 5343, ..., 5747, 5750, 5757],
[5338, 5338, 5336, ..., 5737, 5740, 5747],
[5332, 5331, 5332, ..., 5734, 5736, 5744]]], dtype=int16)
一个xarray.DataArray对象也包含一个或多个坐标coordinates。每个坐标都是一个一维数组,表示的沿着一个数据轴的值。在单通道的SRTM高程数据中,就有三个坐标(coordinates):x、y、band。
rds.coords
Coordinates:
* band (band) int64 1
* x (x) float64 87.0 87.0 87.0 87.0 87.0 ... 88.0 88.0 88.0 88.0
* y (y) float64 29.0 29.0 29.0 29.0 29.0 ... 28.0 28.0 28.0 28.0
spatial_ref int64 0
xarray的一个关键特征是可以使用索引查找 index lookup方法来读取数据集的切片。例如,可以使用sel()方法从主数据集中切片,然后得到通道1(Band1)的数据。
band1 = rds.sel(band=1)
栅格数据的元数据(metadata)存储在rio访问器中。这来自rioxarray库,其基于xarray提供了地理空间分析函数。
print('CRS:', rds.rio.crs)
print('Resolution:', rds.rio.resolution())
print('Bounds:', rds.rio.bounds())
print('Width:', rds.rio.width)
print('Height:', rds.rio.height)
CRS: EPSG:4326
Resolution: (0.0002777777777777778, -0.0002777777777777778)
Bounds: (86.99986111111112, 27.999861111111112, 88.00013888888888, 29.000138888888888)
Width: 3601
Height: 3601
合并栅格数据
现在你已经理解了xarray和rio扩展名文件的基本数据结构来,现在在用来处理一些数据。使用4个SRTM的地图切片,然后将其合并成一个单独的GeoTiff文件。你会注意到使用rioxarray来处理坐标参考系(CRS)和变换(transform)会更好
,处理内部细节并提供了一个简单的接口(API)。
记住一定要导入
rioxarray,哪怕你只是用子模块。导入rioxarray可以激活rio访问器,这是所有运算都需要用到的。
import rioxarray as rxr
from rioxarray.merge import merge_arrays
定义输入和输出路径。
srtm_path = os.path.join(data_pkg_path, 'srtm')
all_files = os.listdir(srtm_path)
output_filename = 'merged.tif'
output_dir = 'output'
output_path = os.path.join(output_dir, output_filename)
使用open_rasterio()方法打开每个源文件,然后将结果数据集存储在一个列表中。
datasets = []
for file in all_files:
path = os.path.join(srtm_path, file)
datasets.append(rxr.open_rasterio(path))
使用rioxarray.merge模块中的merge_arrays()方法合并栅格数据。
merged = merge_arrays(datasets)
最后,将合并的数组保存成磁盘上的GeoTiff文件。
merged.rio.to_raster(output_path)
使用Matplotlib进行栅格数据可视化
xarray的投图函数其实也是基于流行的matplotlib库。
%matplotlib inline
import matplotlib.pyplot as plt
对任何DataArray对象都可以调用plot()方法。这里我们创建一个4个plots的行,渲染每个源SRTM栅格数据文件。可以使用cmap选项来指定一个彩色方案。这里使用内置的灰度Greys。将_r加上去可以逆转彩图方向,黑色表示低高程,浅色表示高的高程。
fig, axes = plt.subplots(1, 4)
fig.set_size_inches(15,3)
plt.tight_layout()
for index, dataset in enumerate(datasets):
ax = axes[index]
dataset.plot(ax=ax, cmap='Greys_r')
ax.axis('off')
filename = all_files[index]
ax.set_title(filename)

与之类似,就可以对合并的栅格数据进行可视化。
fig, ax = plt.subplots()
fig.set_size_inches(12, 10)
merged.plot(ax=ax, cmap='Greys_r')
ax.set_title('merged')
plt.show()

数据来源
- 世界城市数据: 基础数据库。Copyright SimpleMaps.com 2010-2020
- Geonames 地名数据库 美国、加拿大、墨西哥的地名数据。
- 卡纳塔克(Karnataka)的行政边界:下载自Datameet Spatial Data repository.
- OpenStreetMap (osm) 数据图层:数据和地图 Copyright 2019 Geofabrik GmbH and OpenStreetMap Contributors. OSM India free extract downloaded from Geofabrik.
- 班加罗尔(Bangalore)哨兵-2(Sentinel-2)图像。下载自Copernicus Open Access Hub. Copyright European Space Agency - ESA.
- NASA 航天飞机地形图高程数据(Shuttle Radar Topography Mission (SRTM) Elevation Dataset),下载自 30m SRTM Tile Downloader.
授权协议
本课程材料采用知识共享署名-非商业性4.0国际许可协议授权。你可以为任何非商业目的自由使用该材料。请适当注明原作者的名字。
本中文翻译版本禁止商用。
如果你想利用英文原版内容作为商业产品的一部分,需要 联系英文原作者 询问价格和使用条款,获得培训授权,付对应费用。
© 2020 Ujaval Gandhi www.spatialthoughts.com