前些天,在千问的一个官方群里,有朋友询问4060笔记本显卡是否能够运行gpt-oss:20b模型,群里的一些朋友表示这几乎是不可能的。 类似地,之前关于Void编辑器搭配本地模型的一篇文章中也有读者朋友提到,8G内存可能显得稍小,上下文容量可能不够充足,在复杂生产场景中可能会遇到一些挑战。
不过实际测试下来,我这台笔记本虽然只有8G显存的4060显卡,但配上128G内存,跑gpt-oss:20b模型运行起来除了稍慢没发现其他问题,连gpt-oss:120b这种大模型都能正常运行,速度大概在10tokens/s左右,表现还是挺让人满意的。 另外除了编写复杂代码之外,像代码翻译、文本翻译这样的任务,在实际工作中其实非常常见。有时候一些代码或文本信息出于安全考虑不太方便联网处理,这时候使用本地模型就成为了一个很好的选择。
那么,对于这些本地模型,我们该如何简单有效地评测它们的效果呢?到底能不能胜任大家的生产需求呢?其实这可能就和大家各自面对的实际生产需求有很大关系。如果要大部分环节依赖AI来生成代码,而人只是喂一点点提示词,全程交互而几乎不去修改代码,本地模型恐怕很难和在线模型相比;但如果人要自己写代码,而只是用本地模型进行一些简单环节的基础辅助,那么本地模型可能就成为大家生产代码的利器。另外,在其他领域,比如文本润色、外语翻译以及信息问答等等场景,也都有各自的“生产需求”,很难一概而论。
与此同时,虽然学术论文中常用的各种测试方法非常严谨,但对于我们日常的实际需求来说可能显得有些复杂而且又未必很适合。我觉得不如设计一些具有代表性的简单任务,让不同模型来完成,这样既能直观地看到效果差异,又能满足实际使用场景的需求。
基于这个想法,我设计了四种典型的测试场景来评估本地模型的表现:
- 自然语言转代码 - 将自然语言描述转换为相应的代码,重点考察代码的正确性、可读性和效率
- 中英互译 - 中英文双向翻译任务,评估翻译的准确性、流畅性和语言地道性
- 代码解释 - 解释代码的功能和逻辑,测试解释的准确性、清晰度和完整性
- 问题解答 - 回答技术问题,考察答案的准确性、详细程度和实用性
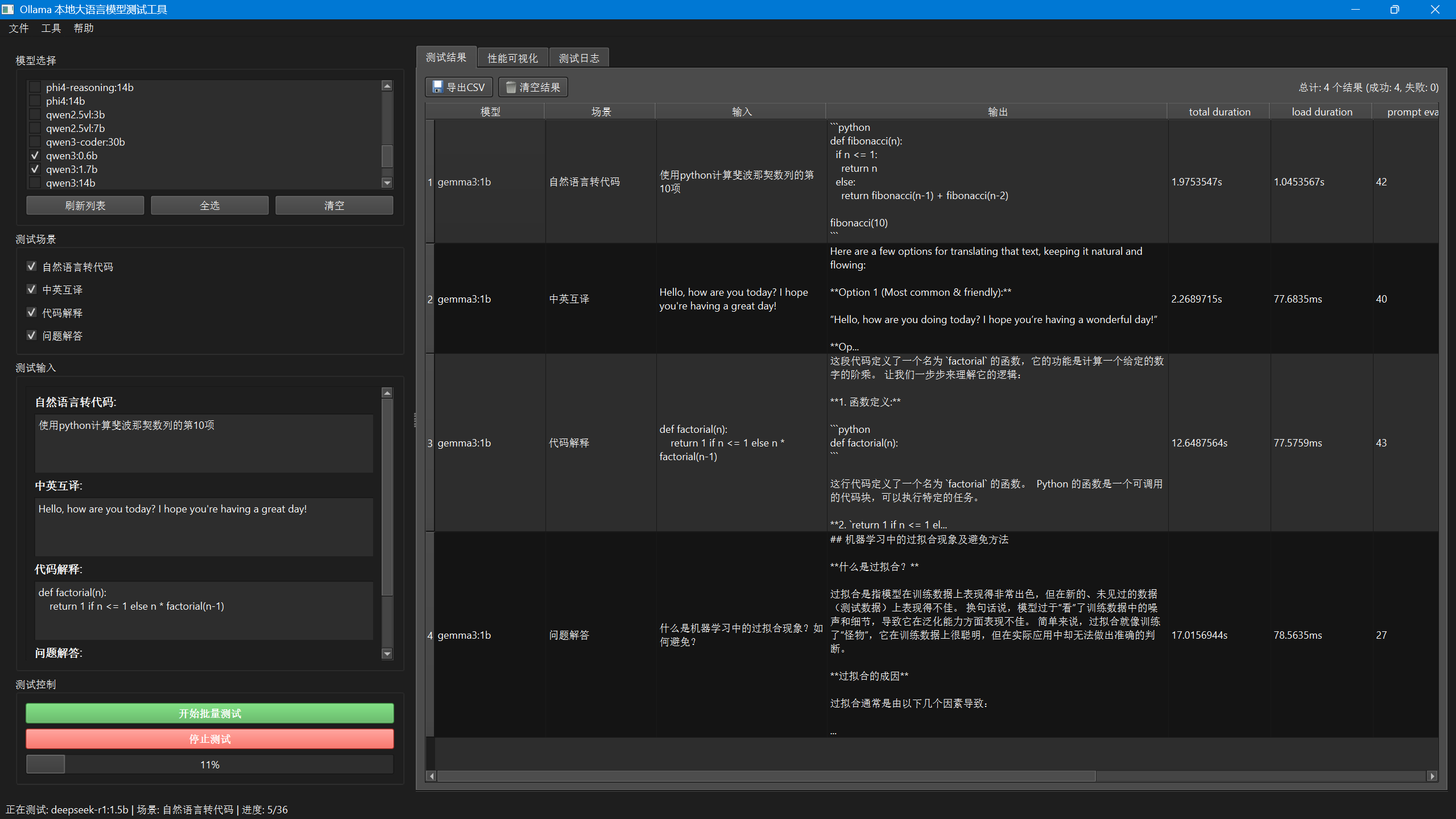
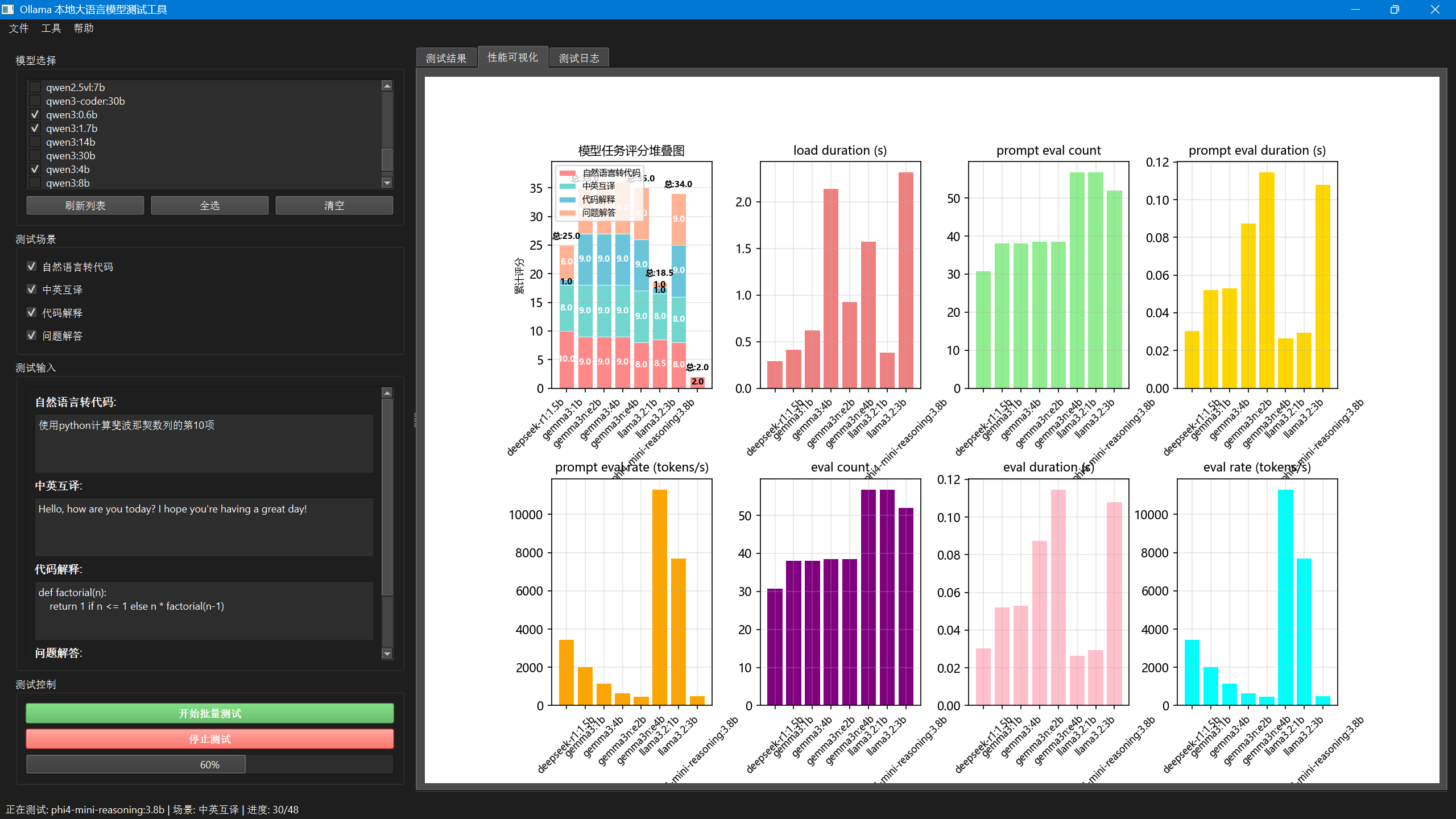
于是我继续用PySide6搭配Briefcase来写了个小工具OllamaModelTester,这个工具是实现对本地Ollama模型的简单批量测试,让用户选择若干模型,然后输入同一任务,让这些所选模型完成任务之后记录所用的时间和各种参数,并且自己评估一下自己给出的结果,最后对所有模型的结果做个对比评价,美滋滋。
运行方法比较简单,克隆之后可以从代码运行:
git clone https://github.com/EasyCam/OllamaModelTester.git
cd OllamaModelTester
pip install -r requirements.txt
cd ollamamodeltester
briefcase dev
也可以下载安装包来安装: 网盘链接: https://pan.baidu.com/s/1imh6uF3lFGSz17KJopF5Ww?pwd=CUGB 提取码: CUGB
界面比较粗糙简陋,大概如下所示,大家自行探索以下基本都能运行起来。测试大概效果如下图所示,具体结论见仁见智了。