使用 QGIS 处理空间数据集
英文原作者:Ujaval Gandhi
中文翻译:CycleUser
导论
本课程对位置数据集的使用进行简要介绍。课程会涉及到一系列的使用场景和应用工具,让你能亲自上手体验地图数据的可视化,并从中提取深层信息。这门课假设你对地理信息系统、遥感都一无所知,也适合所有学科的从业人员。我们这里所有练习都用开源软件QGIS ,所以此课程也适合用于学习QGIS。
软件
本课程使用的版本是 QGIS LTR version 3.16 (长期支持版本),具体的安装可以参考QGIS-LTR 安装指南 。【译者注:也可以自行探索,这一步挺简单的。需要注意的就是尽量用默认设置,别自己乱改安装路径导致环境变量设置不对等等自作孽。】
获取数据集
课程的练习中要用到一系列的数据集,都存放在一起来。下载之后,里面有所有的图层文件、项目文件等等,建议将这些文件到Downloads文件夹下。
完成准备工作
准备工作需要一小时。在开始练习前,理解空间数据如何建模非常重要,还要了解坐标参考系统。
关于地理信息系统的一个使用简介视频
为了对地理信息系统的基本概念有一个初步了解,可以观看下面的视频和对应幻灯片。

做个测试
看完了上面的视频和幻灯片后,可以做一下下面的测试,来试试你对地理信息系统的初步了解。
地理信息系统简介的基础测试
这个小测验是检测你对地理信息系统基础知识的掌握情况。 - 每道题一分。
-
下列哪一个不是矢量数据格式(Vector data format)?
a. Shapefile b. GeoPackage c. GeoTIFF d. CSV
-
地理信息系统是用于下列哪些功能的软件工具?
a. 创建地图 b. 查看地理空间数据 c. 分析空间数据 d. 创建空间数据通道 e. 以上全都对
-
假如你要创建一个非洲地图,你可以选择下列哪种坐标参考系?(多选)
a. Africa Lambert Conformal Conic b. Africa Albers Equal Area c. Equal Earth d. WGS84 Lat/Lon
-
下列哪种数据类型可以用来表示地下水位?
a. 点向量层,展示每个取样位置的水位 b. 栅格数据层,整个区域的每个像素都插值表示水位 c. 线向量层,展示水位的轮廓线 d. 以上全都对
-
在WGS84坐标系中,班加罗尔(Bangalore)的经纬度坐标是 12.9716° N, 77.5946° E,哪一个是Y坐标?
a. 12.9716 b. 77.5946
-
猜一猜GPS坐标为 35.6762° N, 139.6503° E 的是下面哪座城市?
a. 澳大利亚悉尼 b. 日本东京 c. 巴西里约热内卢 d. 加拿大温哥华
-
参考系'EPSG:4326' 中的 EPSG 是什么的缩写?
a. European Petroleum Survey Group b. Earth Projection Standard Group c. European Projection Survey Group
-
保角投影(如墨卡托)保留了以下哪种特性?
a. 形状 b. 面积 c. 距离 d. 以上全都对
-
下图中红色方框所示位置的UTM分区应该是哪个?
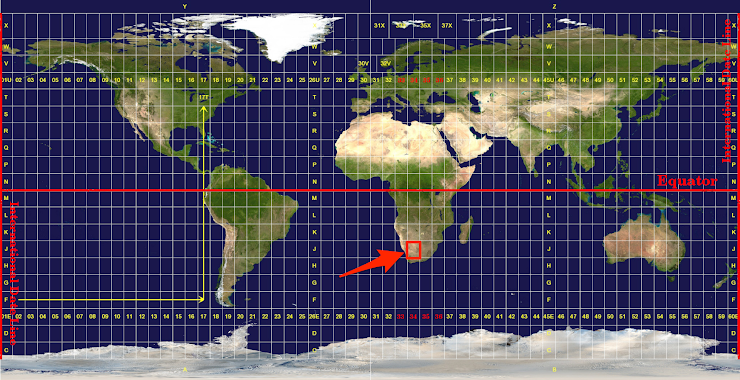
a. 34 b. 34S c. 34N d. 34J
-
下列关于'Geoid' 命题为真的是:
a. 近似地球的平均海平面 b. 是使用精确地表高程测量得到的表面 c. 是使用重力测量推测出的数学表面 d. 以上全都对
参考答案:
c; d; ab; d; a; b; a; a; b; d
理解空间数据
为什么要在意位置?
“Everything is related to everything else, but near things are more related than distant things. 所有事物都和其他的事物相联系,而近距离事物之间的联系比远距离的更紧密。” - Waldo Tobler’s 《地理学第一定律(First Law of Geography)》
当对现实世界进行建模和分析的时候,位置是一个关键的因子。非空间模型无法准确反映现实世界中发生的过程和互动。例如对预测房价 的问题中,空间预测模型的效果就远胜过非空间模型。
位置数据随处可见
现在获取位置数据对个人或者企业都很容易。空间数据为数据增加了额外的维度,能够揭示出原本不显著的模式。
个体有了手机上的定位传感器,就可以将他们的数据附加上位置信息。智能手机拍摄的照片就有内嵌的位置信息。如果选择加入位置信息,用户就可以持续地存储和访问他们的位置历史。
很多企业也有各种各样的位置数据,顾客地址、网站访客的IP地址、销售区域、供应链条等等。对于其他的一些商业活动,比如出租车服务商、餐饮快递、物流等都产生了大量的位置数据,能用来挖掘出情报。
物联网设备也在收集传感器数据的同时持续采集位置数据。
政府机构也在越来越多地采集和分享基于位置的数据。这些与城市基础设施、人口普查、激光雷达和航空图像等等相关的数据,正在被大量采集。很多政府都提供了开放数据共享政策,使得这些数据可以供个人和企业使用。
空间数据模型 Spatial Data Model
空间数据的模型包含两个部分:几何(geometry) + 性质(properties)。
几何(Geometry) (形状 Shape) 是通过坐标和坐标参考系统定义的; 性质(Properties) (属性 Attributes) 是用数据和数据类型来定义的。
下面就是将班加罗尔这个城市表示成一个点:
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [ 77.58270263671875, 12.963074139604124]
},
"properties": {
"id": 1,
"name": "Bengaluru"
}
}
上面的格式使用的是 GeoJson 格式 。点的几何坐标使用了X (经度 Longitude) 和 Y (纬度 Latitude)两者来定义。这个点都被分配了两个属性,第一个 id 的值是 1,而 name 就设置成城市名字 Bengaluru。GeoJson 格式只支持一个坐标参考系统(WGS84),所以这里不需要在具体指定。
空间数据格式
前面已经讲了表征空间数据的最基本的方法。实际上有很多种数据格式能表征空间数据,这些数据格式有个字适合的不同应用。大多数情况下,空间数据格式就是对已有数据格式的扩展。
| 类型 | 非空间数据 | 空间数据 |
|---|---|---|
| 文本 | csv, json, xml | csv, geojson, gml, kml |
| 二进制/压缩包 | pdf, xls, zip | shapefile, geopdf, geopackage |
| 图像 | tiff, jpg, png | geotiff, jpeg2000 |
| 数据库 | SQLite, PostgreSQL, Oracle | Spatialite, PostGIS, Oracle Spatial |
空间数据类型
空间数据一般可以分成两类,矢量数据(Vector)和栅格数据(Raster)。在网络上提供相关服务的这些数据一般都是被切成一个个小的块(切片,tiles),这些就可以作为第三类来分出来。
| 类型 | 子类 | 样例 |
|---|---|---|
| 矢量 | 点 | 传感器观测数据, 位置 |
| 线 | GPS 轨迹, 道路, 河流, 轮廓线条 | |
| 多边形 | 行政区划, 建筑 | |
| 点云 | 激光雷达测量 LIDAR surveys | |
| 栅格 | 照片 | 航拍和无人机照片 |
| 网格 Grids | 卫星图像, 高程数据 | |
| 网状结构 Mesh | 气候和科学观测数据 | |
| 切片 | 栅格数据切片层 | 网络地图 |
| 矢量数据切片层 | 网络地图 |
地图投影和坐标参考系统
如果说空间数据有什么特殊之处,那一定就是坐标参考系统(Coordinate Reference System,缩写为 CRS)
地图投影(Map Projection) 将地球从立体球型(三维)投射成平面形状(二维)。
坐标参考系(Coordinate Reference System,CRS) 就定义了这个投影得到的二维地图如何关联到地球上的真实位置。
在QGIS 官方文档 中提供了对这一话题的详细介绍。
目前市面上有几百种不同的地图投影和对应的坐标参考系,每一种都有不同的性质和用途。最重要的是要记住,每一种投影都或多或少在某些方面存在畸变。有一篇 地图投影集锦 提供了常见投影方案的可视化介绍。更进一步的相关信息可以参考 Jochen Albrecht 所写的指南:选择一个投影. 另外一篇 最近发表的文章 表明了投影选择对面积和体积计算的影响。
那么你要选择什么投影方案呢?这可能是一个很宏大且复杂的话题,而且答案通常是,看情况。但接下来的这些内容会帮到你。
- 全球地图: 如果你要绘制的是全球地图,目前的主流选择是使用Equal Earth 投影。这种投影的附加优势就是保持了面积,所以对于需要等面积网格进行全球规模分析的场景来说是很好的选择。相比于其他的投影方案,比如 Gall-Peters 投影等等,Equal Earth在视觉上效果也更好些。新版本的 QGIS 已经内置了对多种 Equal Earth 坐标参考系的支持. 如果你用的是旧版本,可以通过下面的字符串来 自定义坐标参考系(Custom CRS) :
+proj=eqearth +datum=WGS84 +wktext
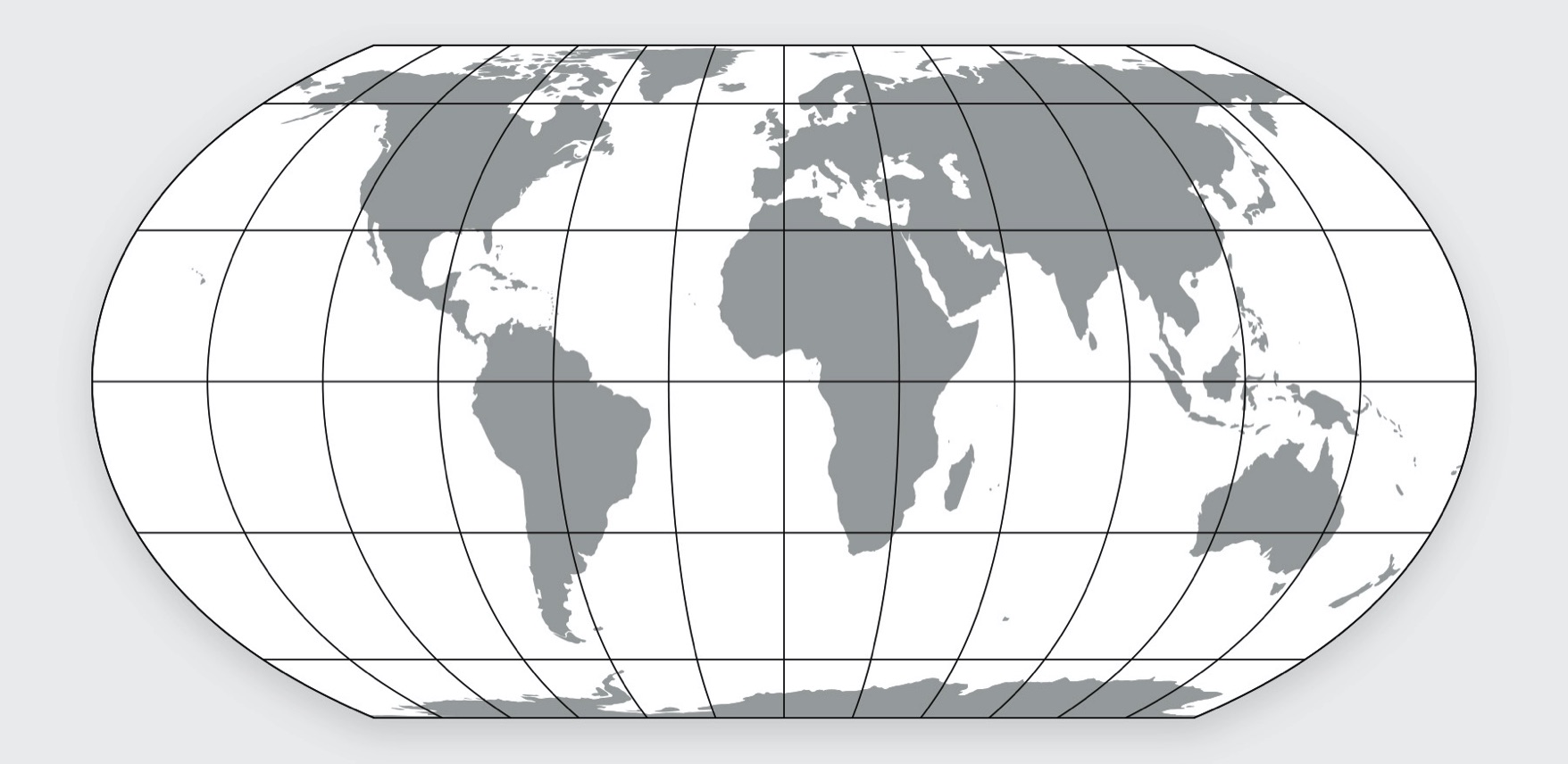
The Equal Earth Projection
-
国家地图: 很多国家都制定了某个特定版本的坐标参考系统,目的是最小化本国内的畸变。可以通过访问对应国家的相关机构来获取相关信息。
-
局部和区域地图: 和国家层面的坐标参考系类似,很多国家都还有州、省一级的坐标参考系。另外,通用横轴墨卡托变换(Universal Transverse Mercator,UTM)为全球任意地区都提供了良好的坐标参考系。在每个区域内的畸变都是最小的。如果你的研究去包含在某个UTM区域内,使用UTM是分析和制图的好选择。

UTM Zones of the world
QGIS 简介
QGIS 是一个自由、开源软件,可以用于创建、编辑、可视化、分析和出版地理空间数据。QGIS支持Windows、macOS和Linux。本课程使用的是QGIS的长期支持版(Long Term Release,缩写为LTR),可以在QGIS 官网下载页面 下载安装包。
插件(Plugins)
QGIS为开发者提供了插件这种非常简单的方式来扩展软件核心功能。安装和管理插件,需要在 QGIS 的菜单中选择Plugins → Manage and Install Plugins..,然后切换到 All 标签,然后搜索要安装的插件。找到之后,选中,然后点击Install Plugin 就安装了。
本课程中,我们使用的是下面两个插件,需要大家来安装一下: * QuickMapServices * QuickOSM
可视化
点
对空间数据的最简单表述方式就是使用表格。一个地理位置可以表示成一对坐标,经度和纬度,然后再加上与之相关的其他属性信息。很多空间数据都是这样的形式,比如Excel表格、CSV逗号分隔符文本,数据库表格等。
练习:将空气质量投在地图上
世界上很多国家和地区都面对着空气质量变差的问题。要更好地理解这个问题,首先的一步是持续收集各地的空气质量数据,很多机构都有这类数据的收集和公开,比如OpenAQ 。
我们使用 PM2.5 浓度数据 中一天的数据,然后对其进行投图。目的是将表格数据转换成位置数据的可视化。
本次练习中,我们使用的是2021年12月30奥地利当天的数据,下载自OpenAQ Data Download。
- 在编辑器中打开下载的文件
measurements.csv然后看一下。value是测量值,latitude是纬度,longitude是经度。
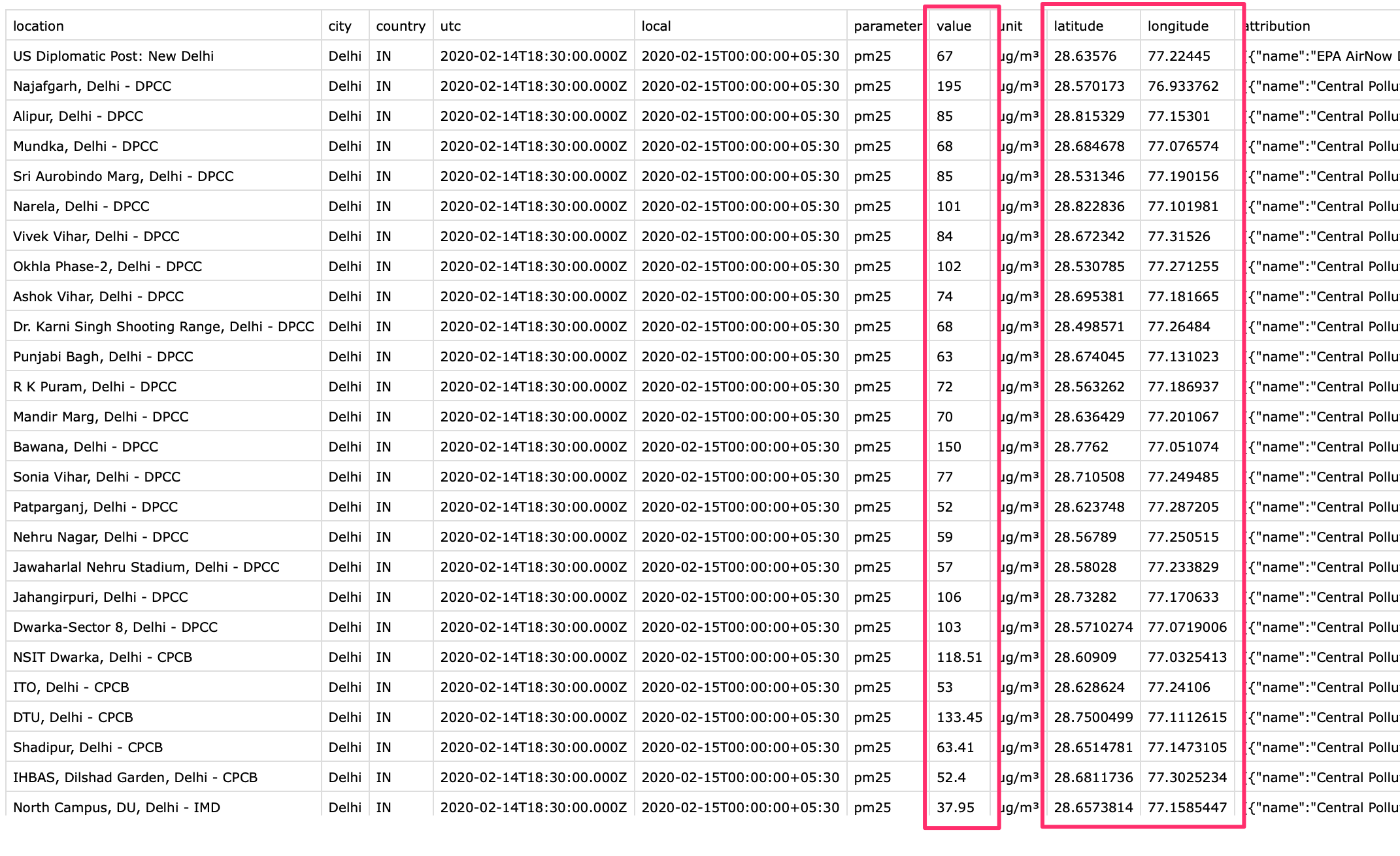
- 下载的这种
csv格式的文件可以算作是一种分隔符文档Delimited Text,可以在QGIS里面通过Data Source Manager来进行导入。在QGIS主界面点击Open Data Source Manager 按钮即可。
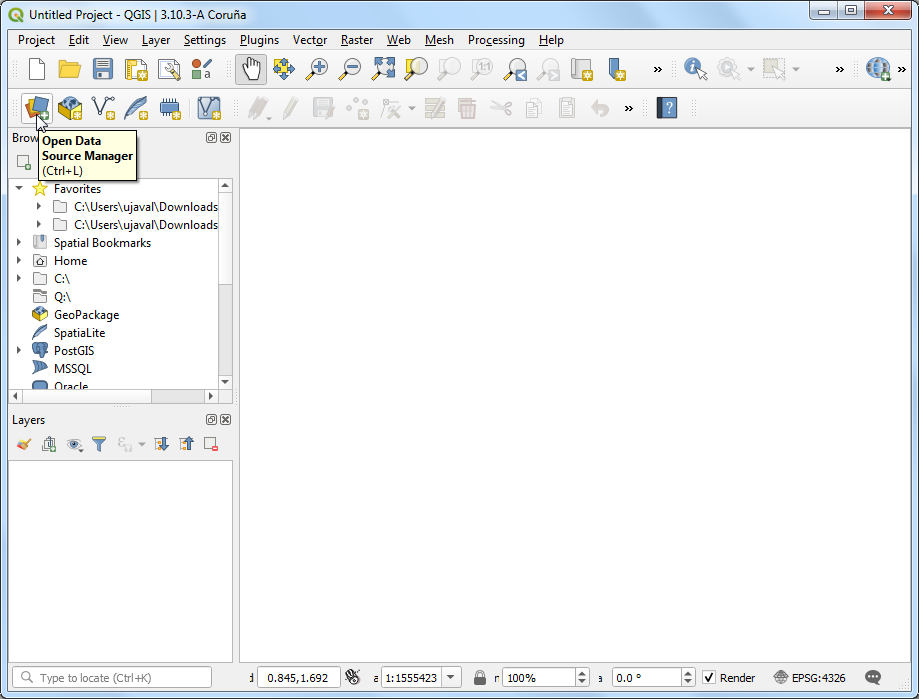
- 浏览到下载的
measurements.csv文件打。在 Data Source Manager 里面选择Delimited Text,然后在File name里面定位到目标文件,在Geometry Definition里面选择Point coordinates,设置longitude为 X Field,latitude为 Y Field,然后选择EPSG 4326 - WGS 84作为Geometry CRS,点击Add。
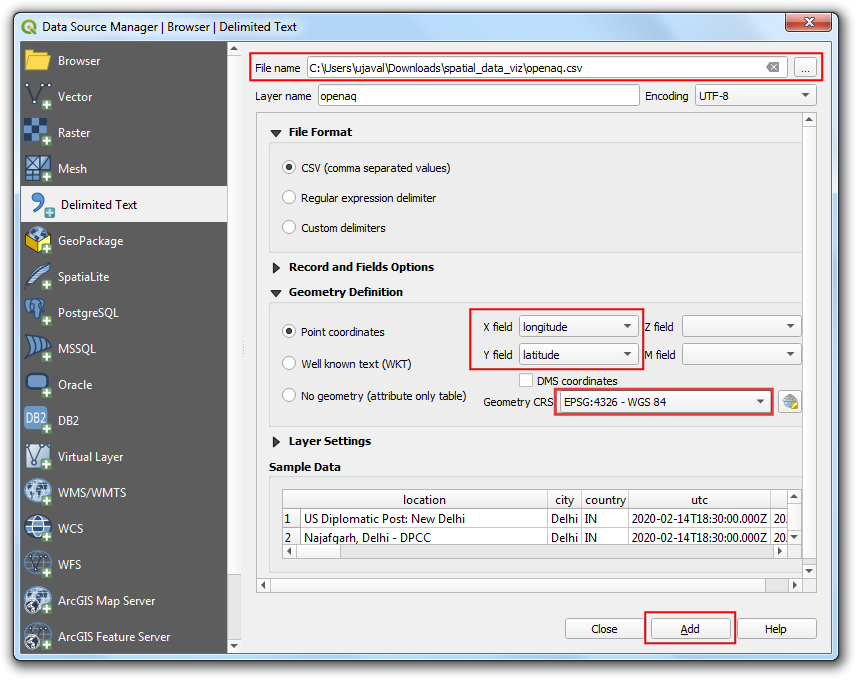
- 然后就能看到表格数据加载到QGIS的画布上了,成了一个空间数据层。使用 Identify 按钮来查看各个点,就能看到对应的各项数据。
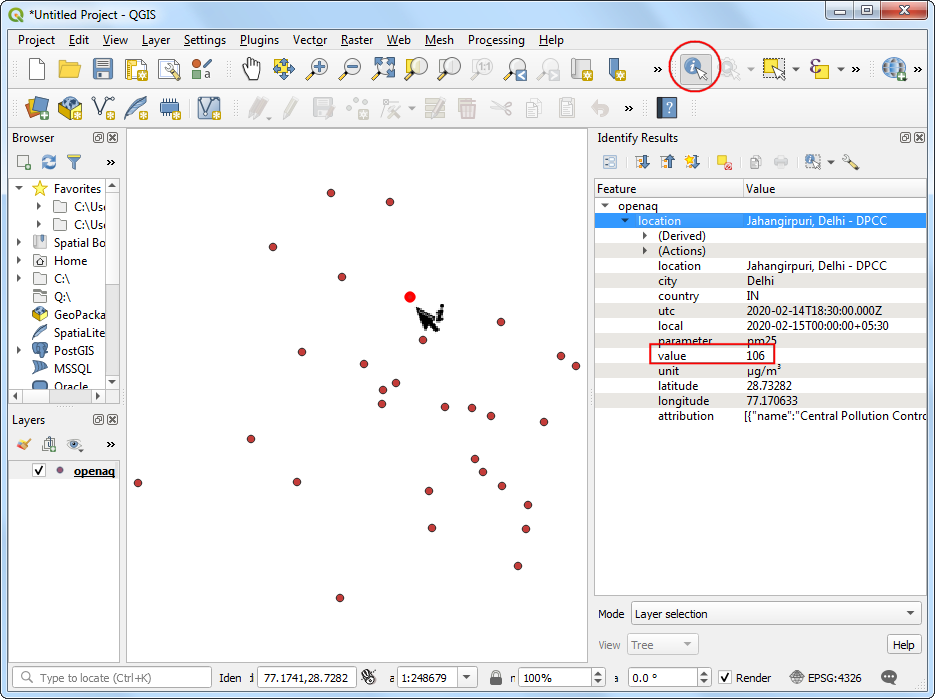
- 点的分布在城市周围,但图上现在还没添加城市地图,所以就要加一个地图层(base-map layer)。这里使用QuickMapServices 这个插件来加载多种地图,点击 Web → QuickMapServices → OSM → OSM Standard 图层.
注意:如果你想要用其他的地图图层,到 Web → QuickMapServices → Settings 中,切换到 More services,点击
Get Contributed Pack,然后点击 Save保存即可。
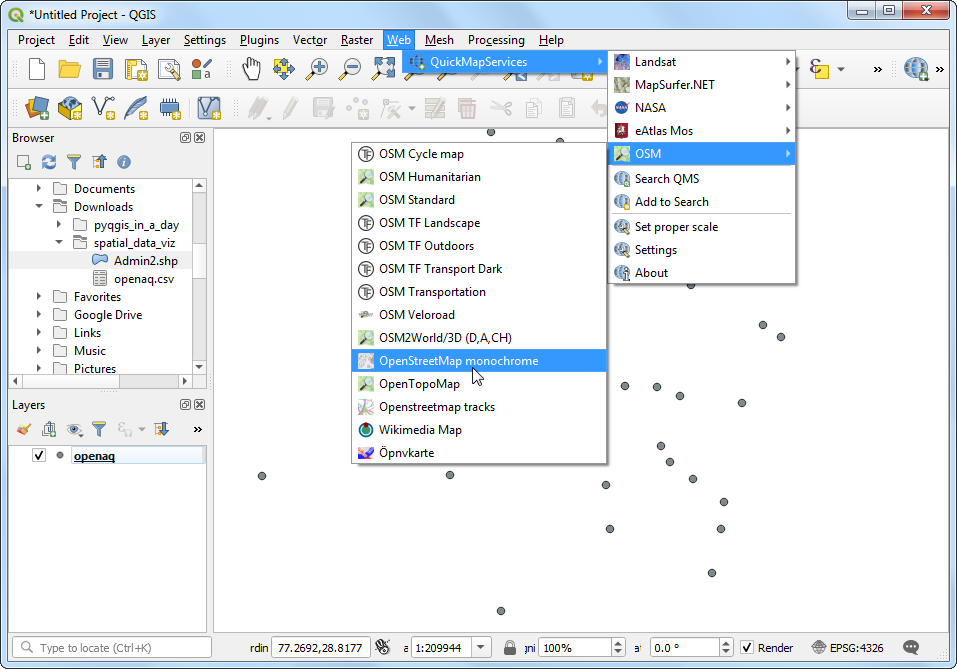
- 新图层就添加到左侧的 Layers 面板中了,也同时呈现在了画布Canvas中。现在你就能看到数据点出现在城区地图上面了。接下来咱们点击 Open the Layer Styling Panel 来让数据点看着更好一点。
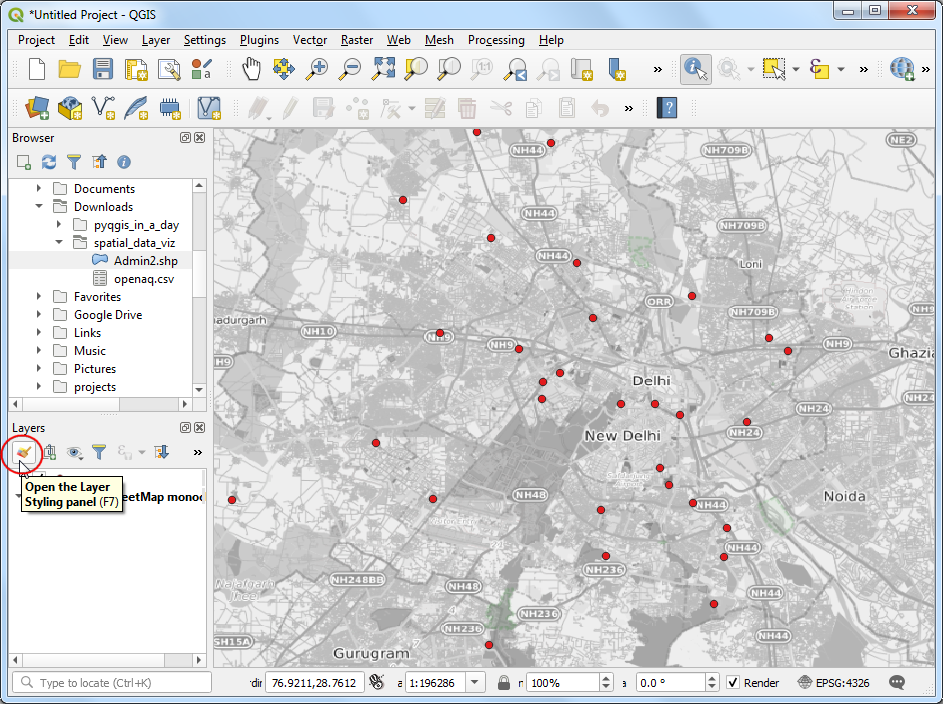
- 这回咱要根据每个点的观测到的
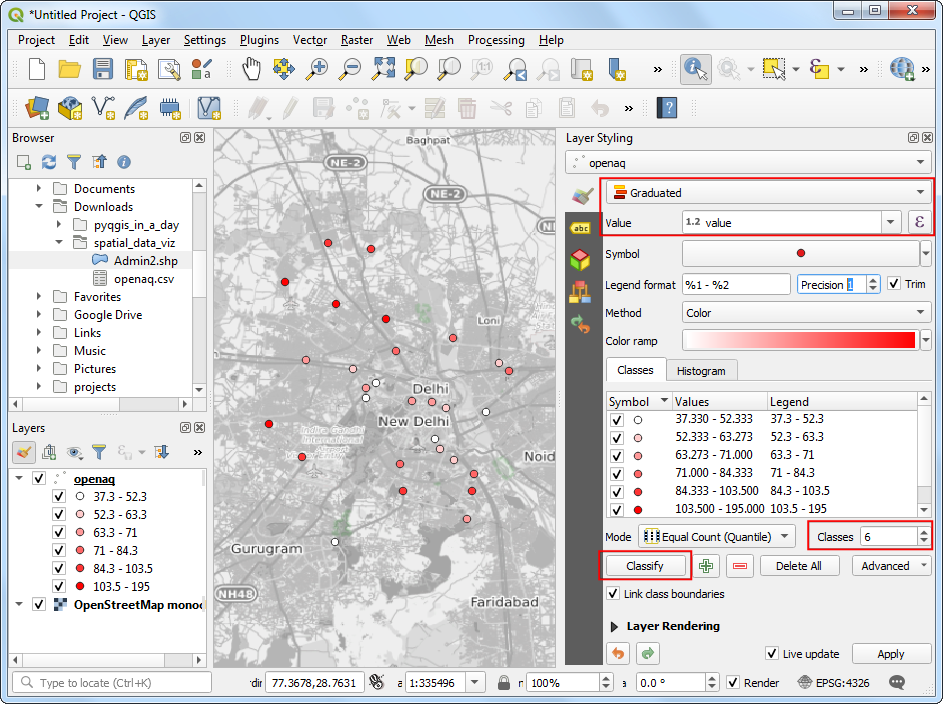
value来对其进行着色。选择Graduated着色器,然后将value设置为 Value 列。将Classes 到分类数设置为6然后点击 Classify。
注意:默认的分类模式是Equal Count - 这对于咱们的练习来说也能用。 关于数据分类的更多内容可以参考 QGIS 官方文档。
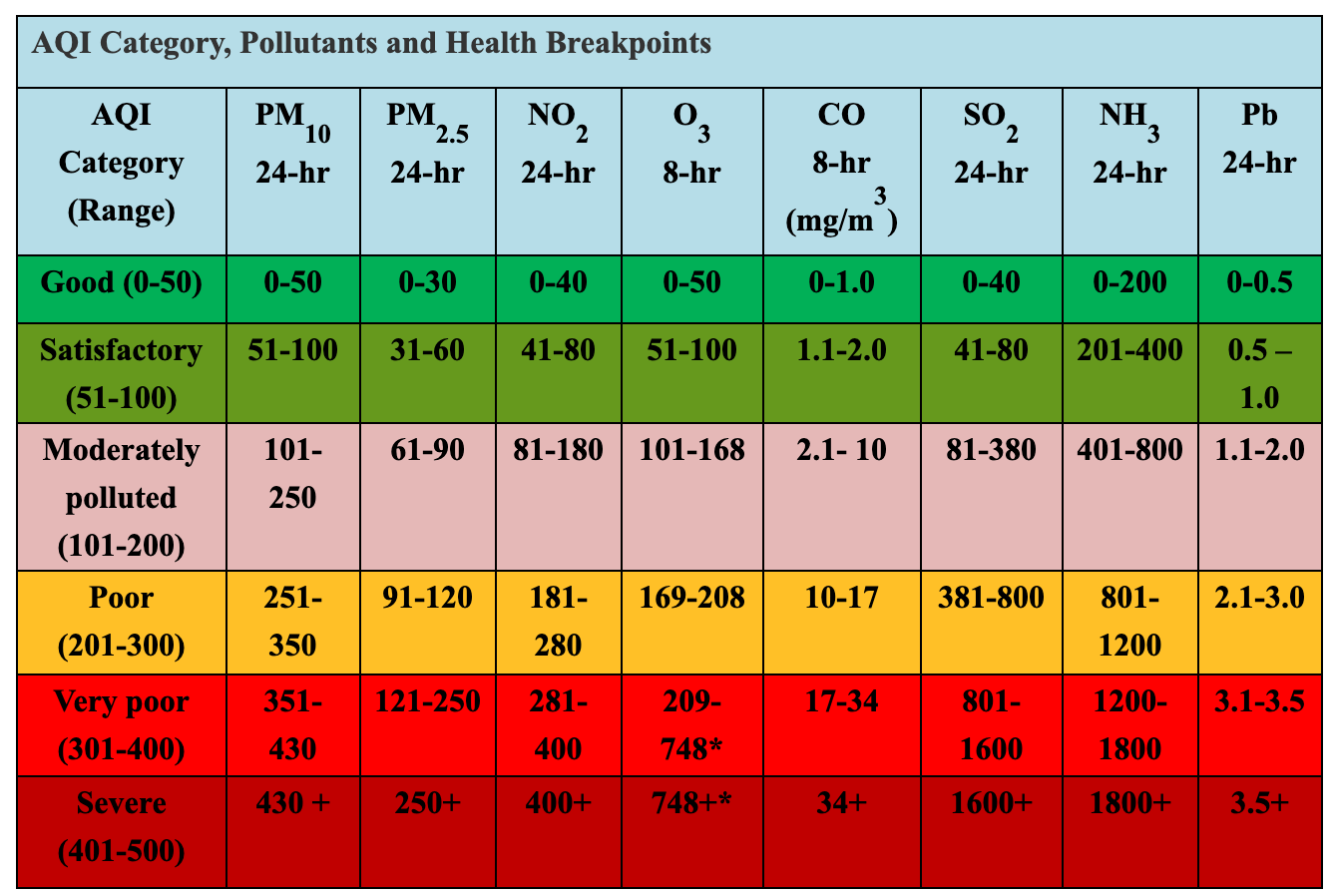
要让分类范围再有更多的意义,可以将它们和常用范围联系起来。
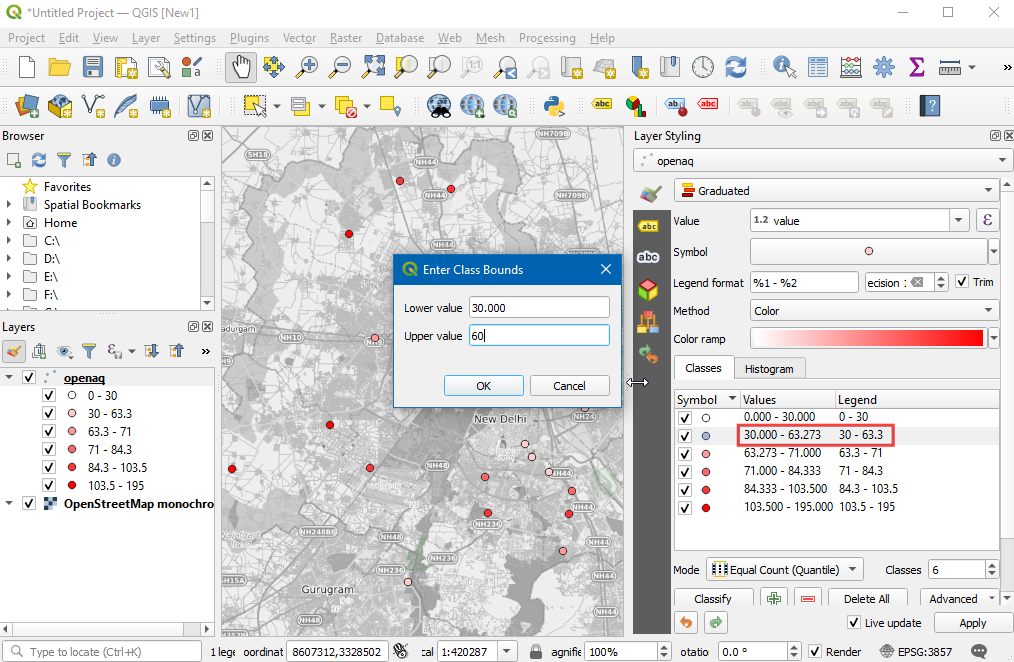
- 接下来调整,将图例Legend 调整成人类可读性更好的分类名称,可以双击每一个类别的范围然后来修改。
注意:这里的区间包含上界,不包含下界。所以如果一个区间是 30-60,包含的就是所有 >30 而<=60的值。具体的细节可以参考QGIS的这个Issue 。
- 由于你修改了分类那对应的可视化方案也要调整了。正好把空气质量调整成对应的模式。
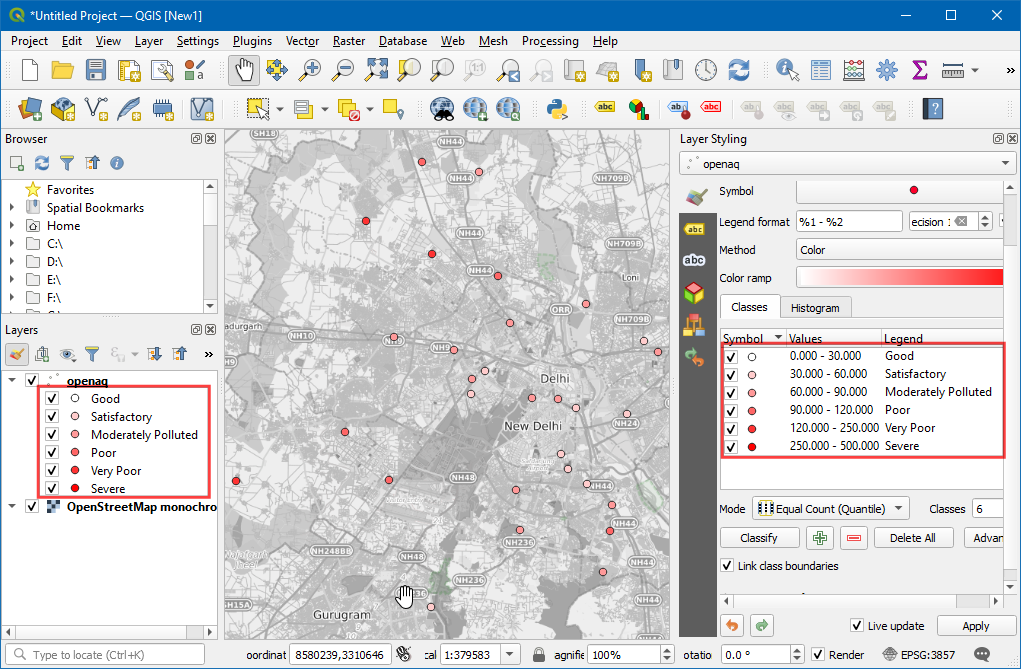
- 另外还可以调整一下配色,这里就将原来的单色调成红黄绿三色
RdYlGn(Red-Yellow-Green) 。
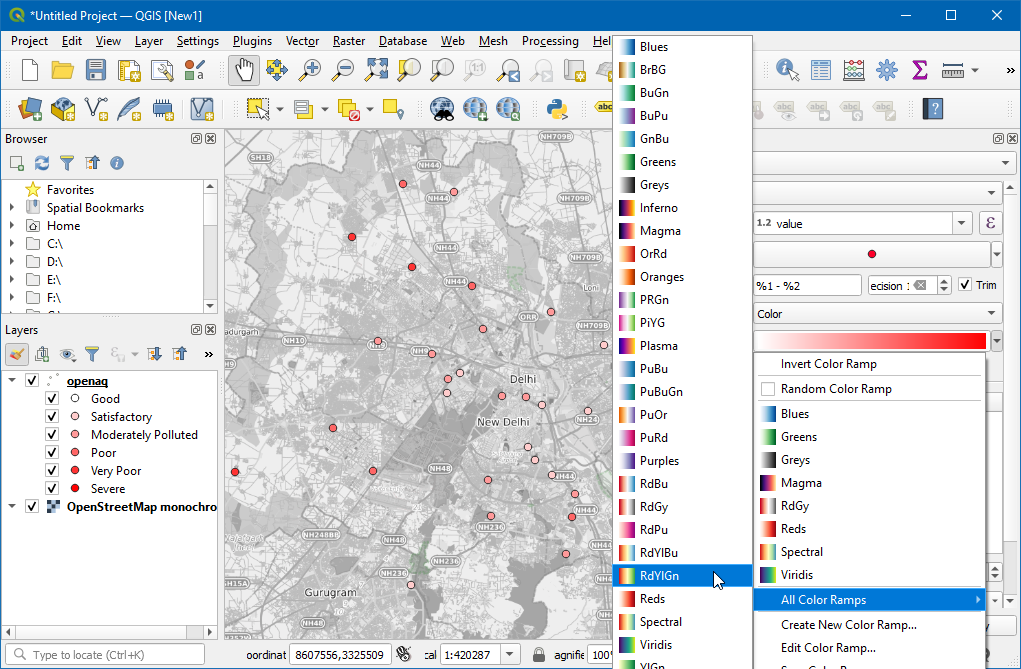
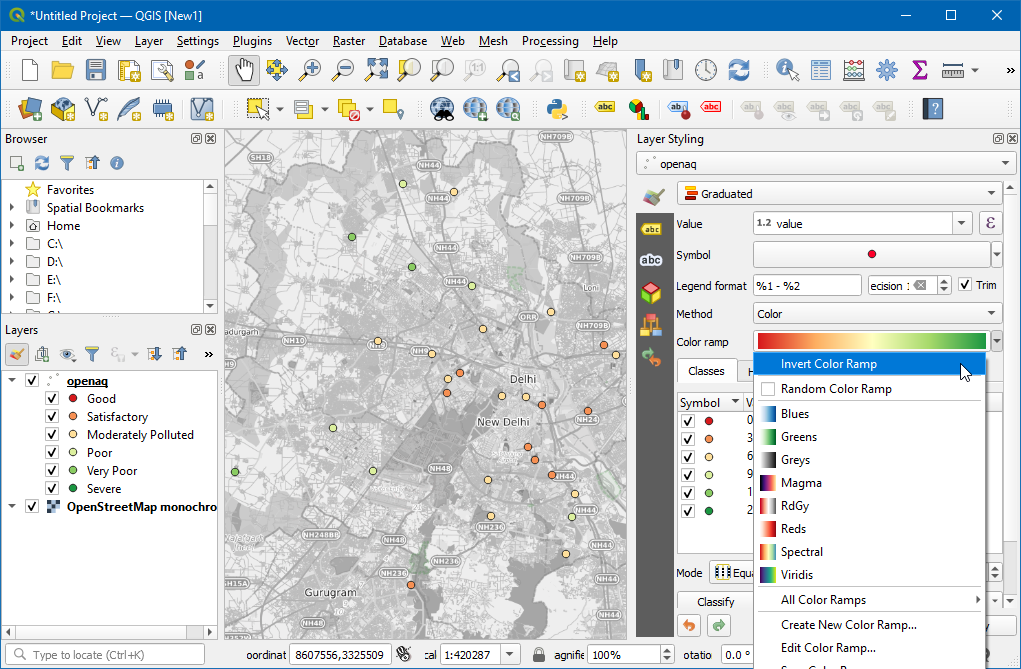
- 这里就发现有问题了,默认的是高值变成绿,低值是红了。我们希望的正好是反过来,所以点击刚才的下来菜单,然后选择Invert Color Ramp来反转配色。
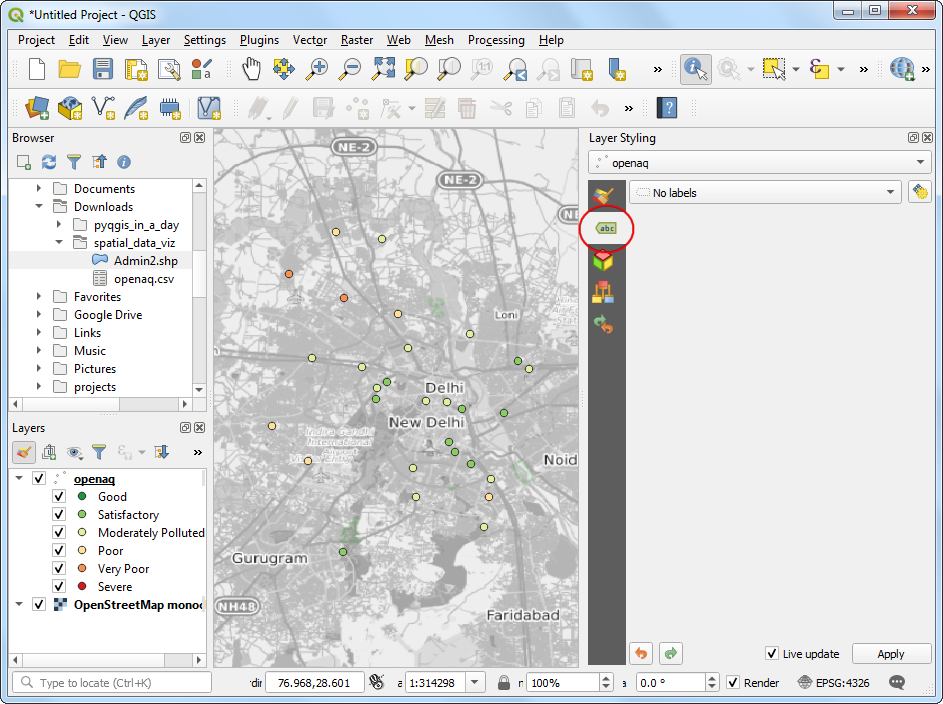
- 解下来就是要在点上添加字符标签来。切换到Labels 标签,如下图所示。
- 选择
Single labels然后设置value为 Value,下拉,再选择格式化树枝 Formatted numbers ,将小数点 Decimal places 设置为0。
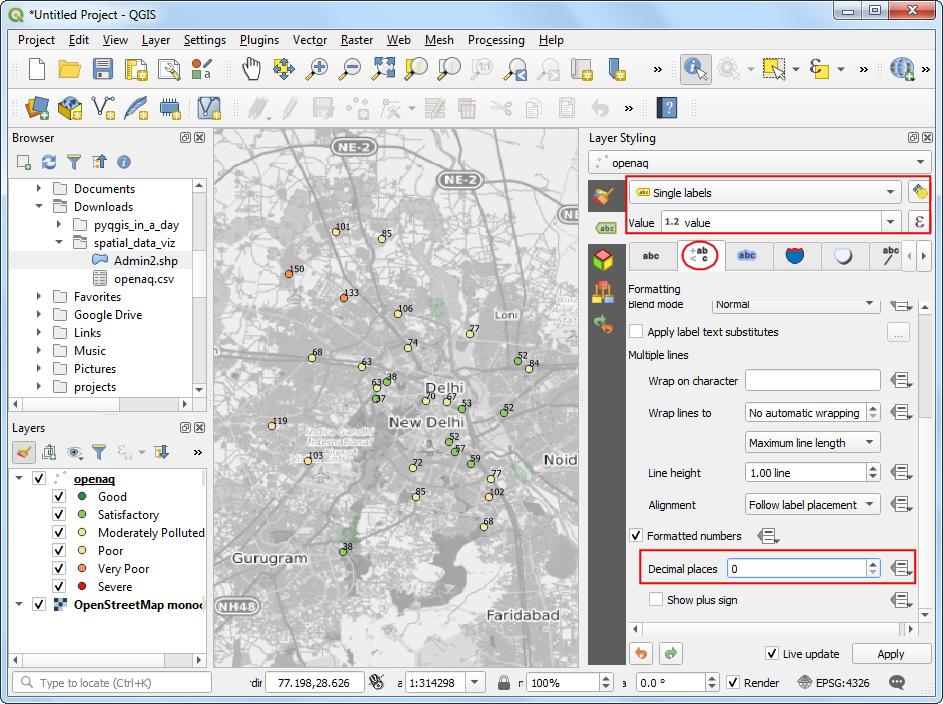
- 然后写换到Background 标签页,选中 Draw background 后调整 Size X 和 Size Y。
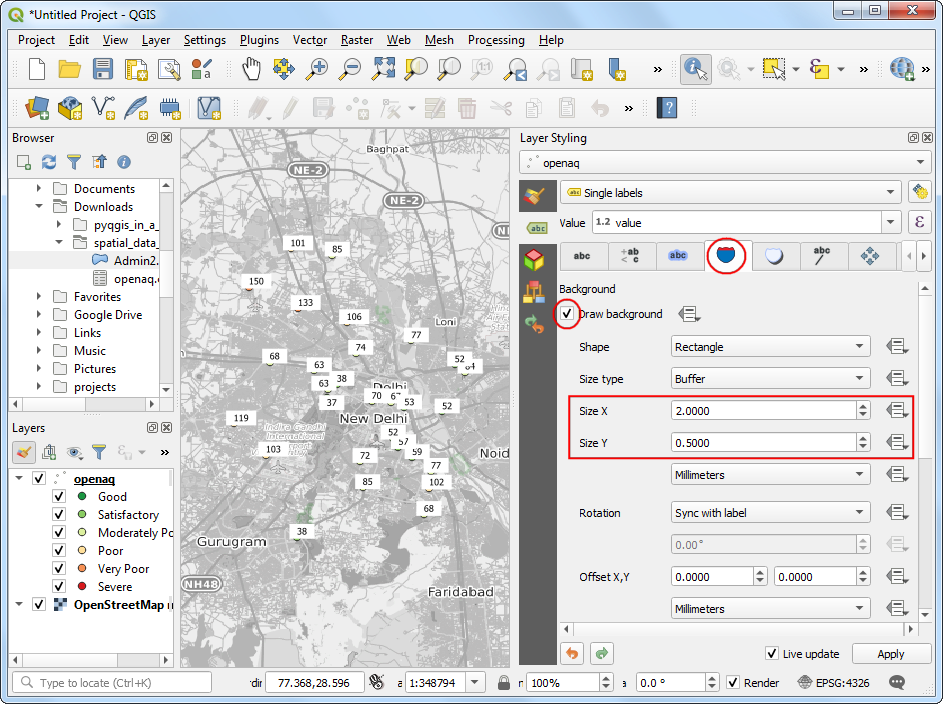
- 在下面找到 Fill color 部分,我们希望将每处填充上和圆点一样的颜色。点击 Data defined override 按钮然后选择 Edit。
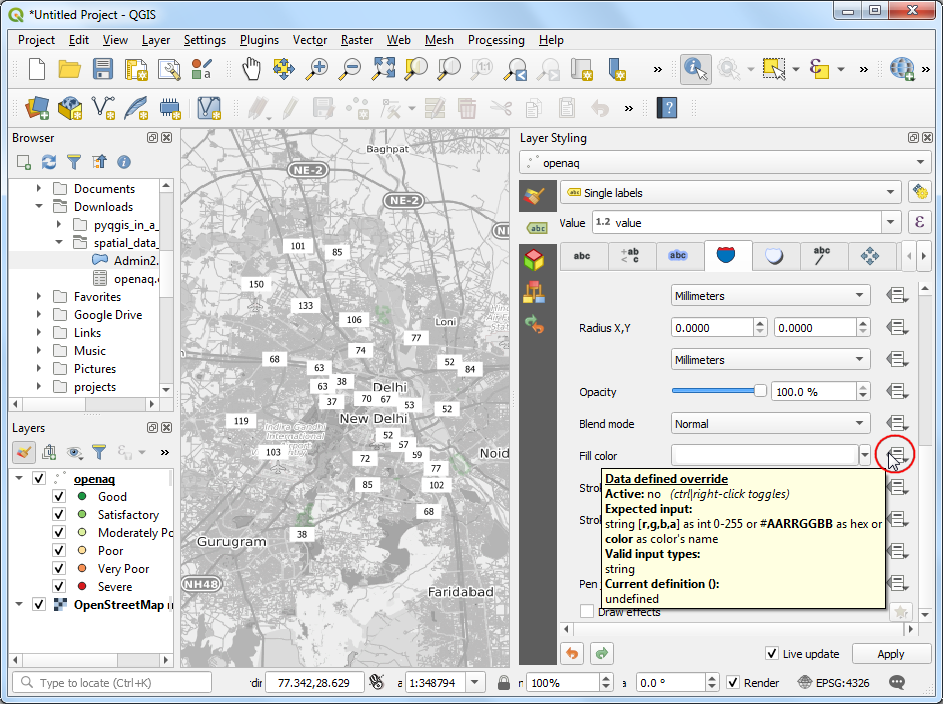
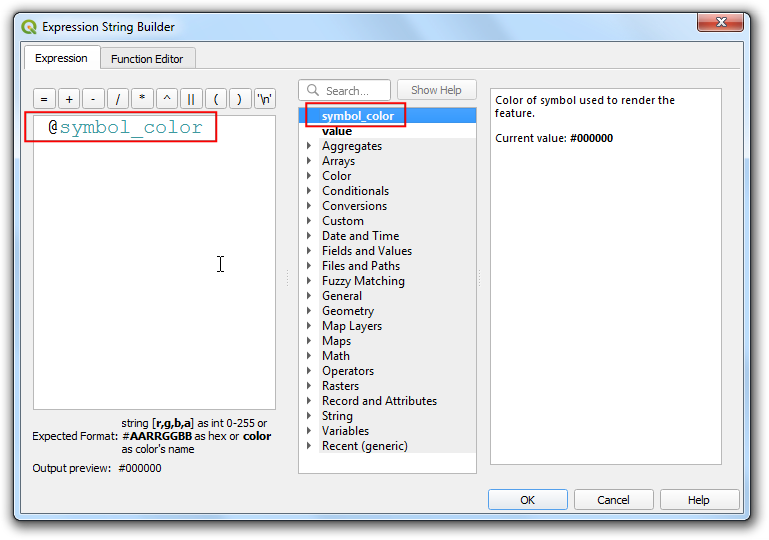
- 双击
@symbol_color变量,加入到表达式中,然后点击OK按钮确认。
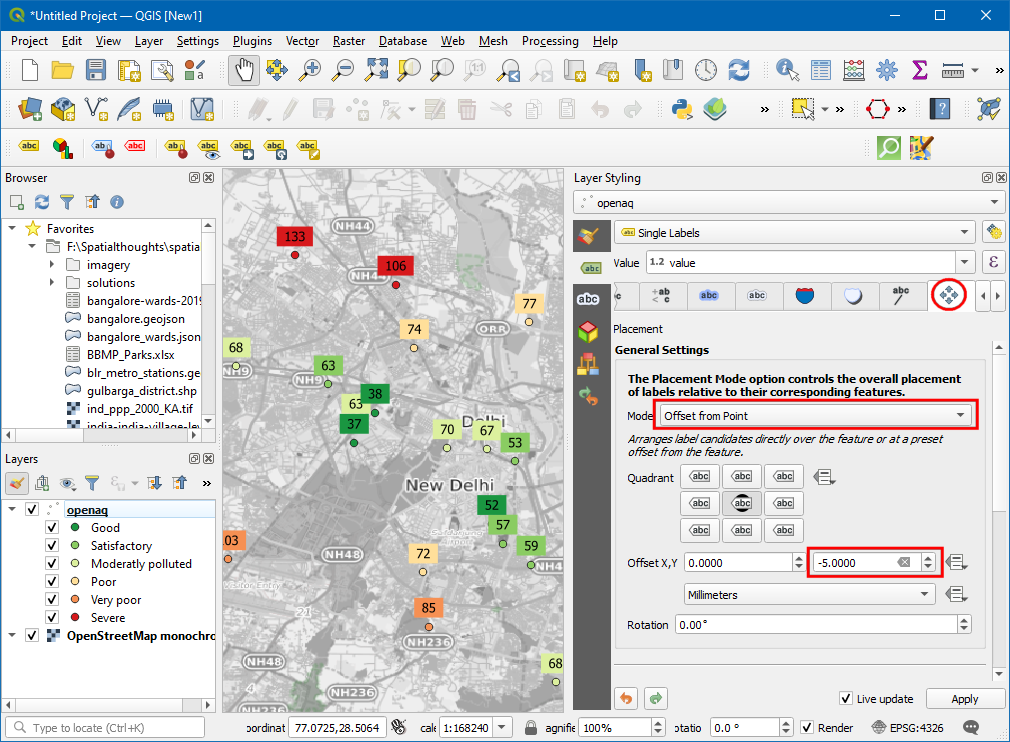
- 现在就会发现两者颜色匹配了,然后切换到 Placement 选项卡,选择Offset from point,设置 Offset Y 为
-5。
- 最后,点击进入 Callouts 标签页,然后选中 Draw callouts 使得所选的方块标签与对应的数据点之间连起来以便于区分。
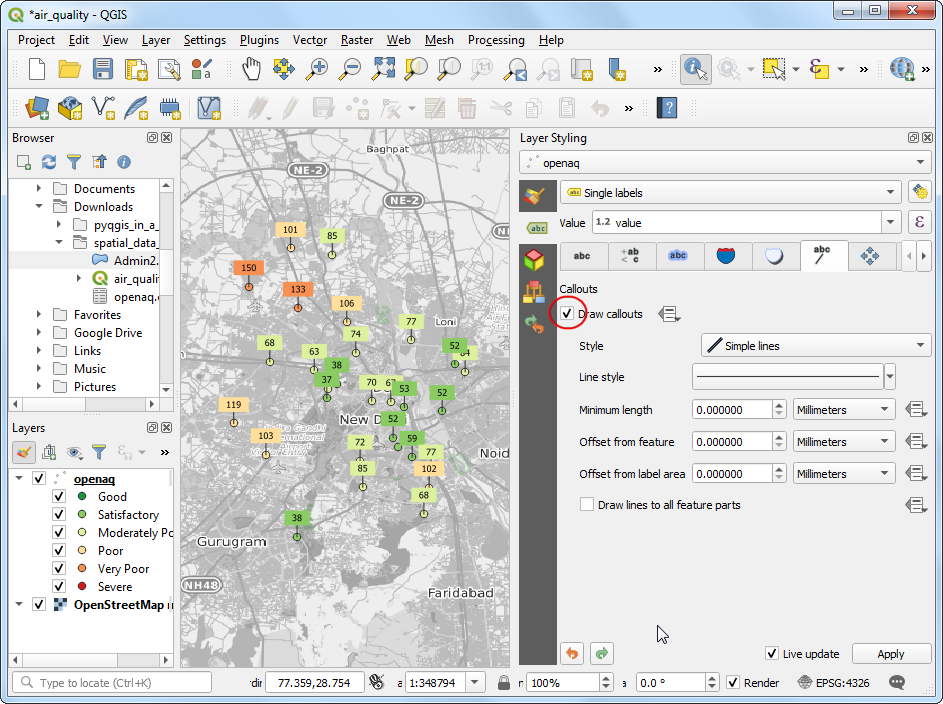
- 现在就点击Save Project 按钮来把这个项目保存成
air_quality.qgz。
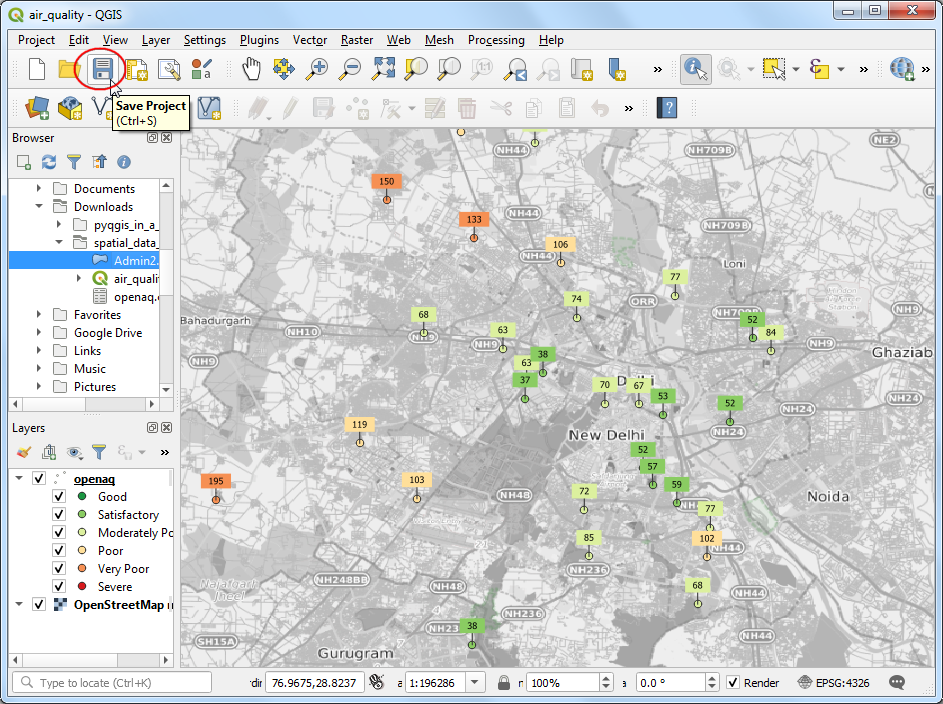
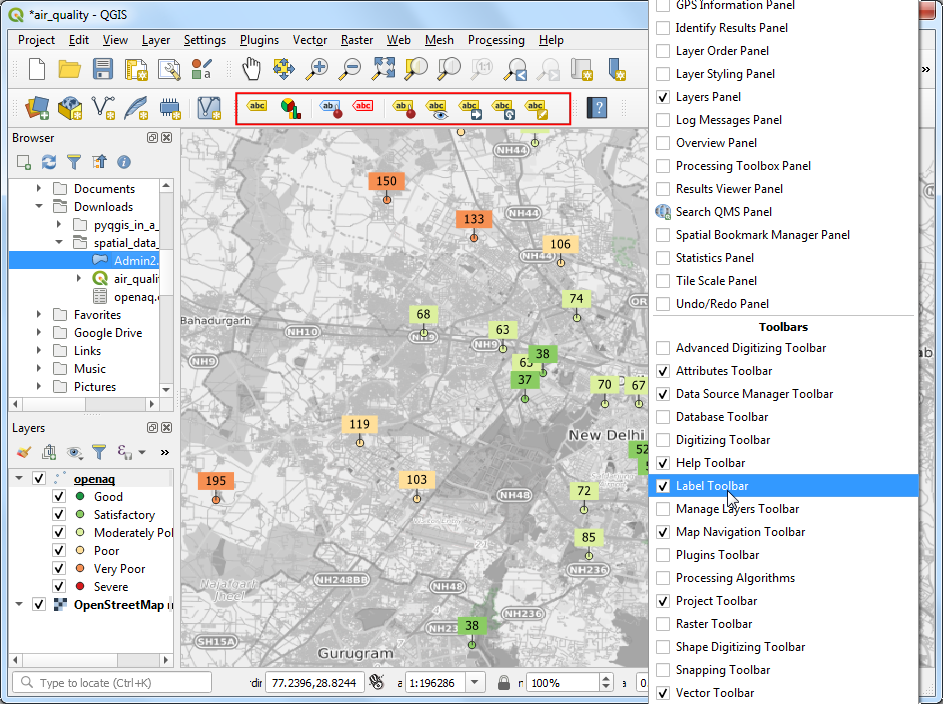
- 现在标签看着都还挺清晰,但有的太近了,很拥挤。可以手动调整标签位置来解决这个问题。在工具栏区域右键任意位置打开Label Toolbar,如下图所示。
- 点击Move a Label 按钮,然后在出现的 Auxiliary Storage 提示界面上点击OK。
- 由于上面激活了 Move a Label 按钮,现在可以点击任意一个标签来选中。然后想把它挪到哪里就点到那里即可。弄完之后,再次保存项目。现在就可以导出做好的地图了,到菜单中的Project → New Print Layout…,名字留空,直接点击OK。
- 输出图幅可以将各种元素都放在一起成为一个静态地图,包括标签、图例、指北针、比例尺等等。可以在Add Item → Add Map中来添加地图。
- 如果你没看到完整地图扩展范围,可以点击 Set Map Extent to Match Main Canvas Extent 按钮,位置在工具栏中
Map 1的Item Properties的下面。
- 接下来,添加一个 Rectangle ,来存放地图切片、比例尺和属性信息等等。
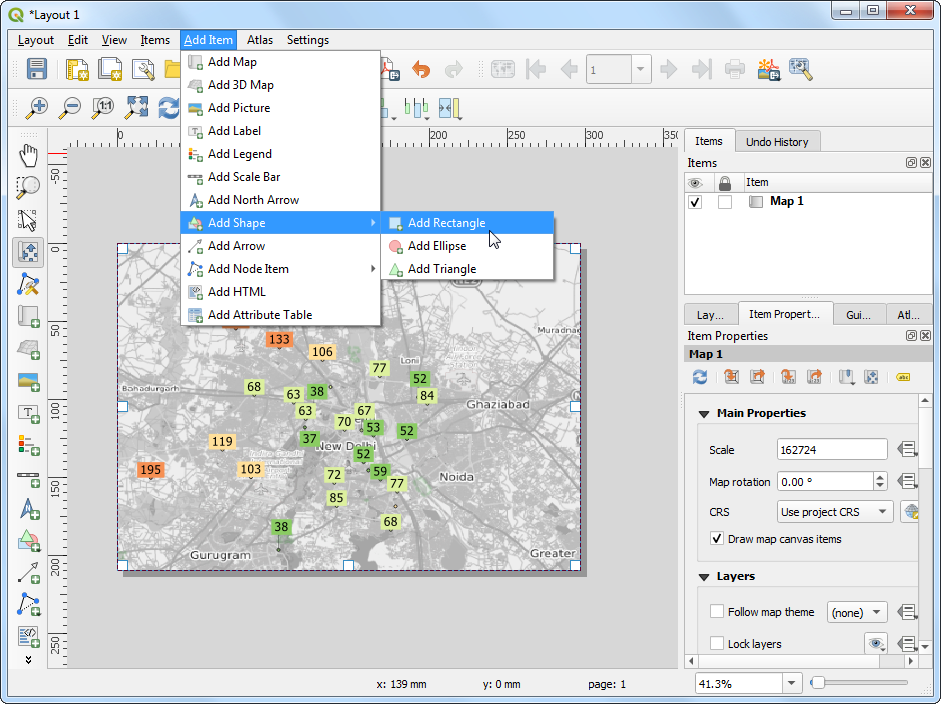
- 将这个小矩形放到图幅右上角,设置Corner radius 为
10。
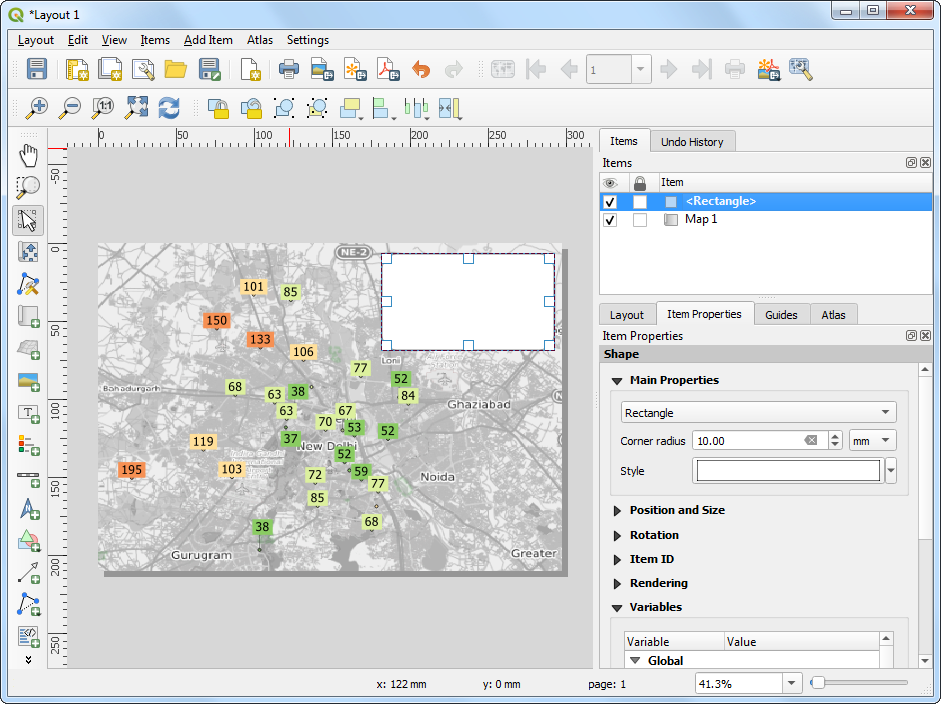
- 然后在这个小矩形中添加一个 Label 。输入你的地图名字
Average PM2.5 Concentration (µg/m3)以及日期15 February, 2022。
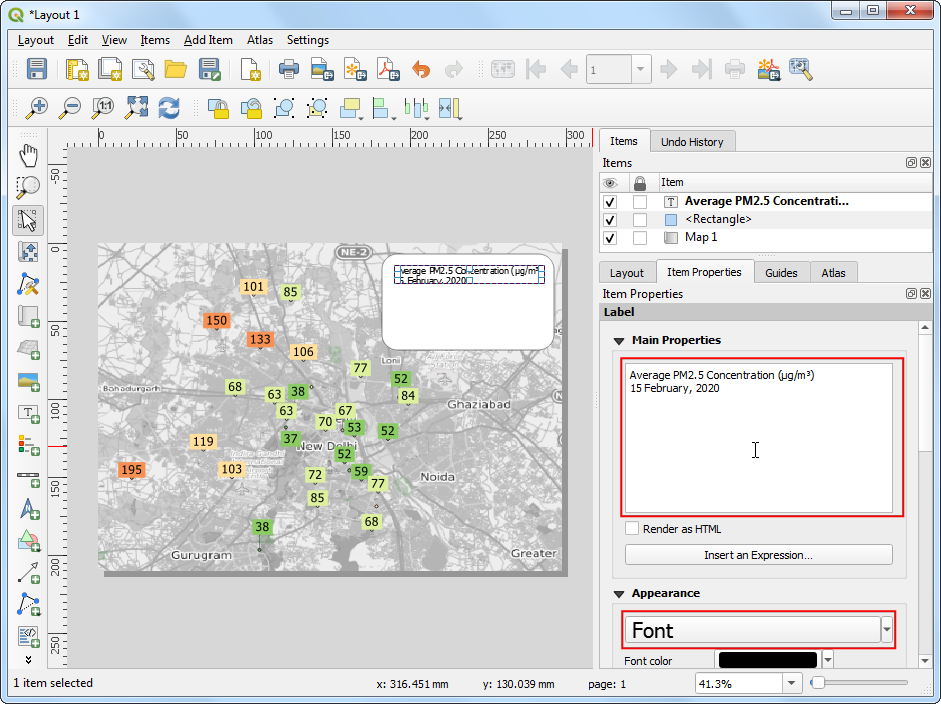
- 还是在这个矩形中,再添加一个标签Label ,设置文本为
Data Source: Central Pollution Control Board, EPA AirNow DOS. Downloaded from OpenAQ.org。然后还要添加图例来解释图上的符号和颜色等等。到菜单栏中,找到Add Item → Add Legend。
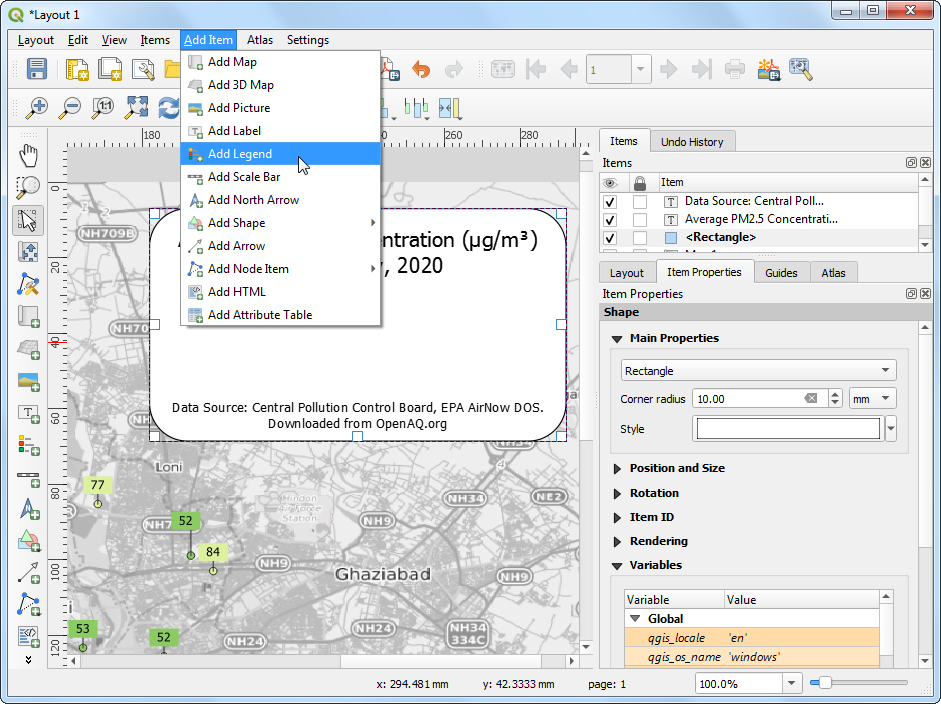
- 拖动方框来插入图例到白色矩形中。然后再找到Item Properties 标签页来关闭 Auto update,移除
OpenStreetMap monochrome图层,然后设置openaq群标签为隐藏Hidden。
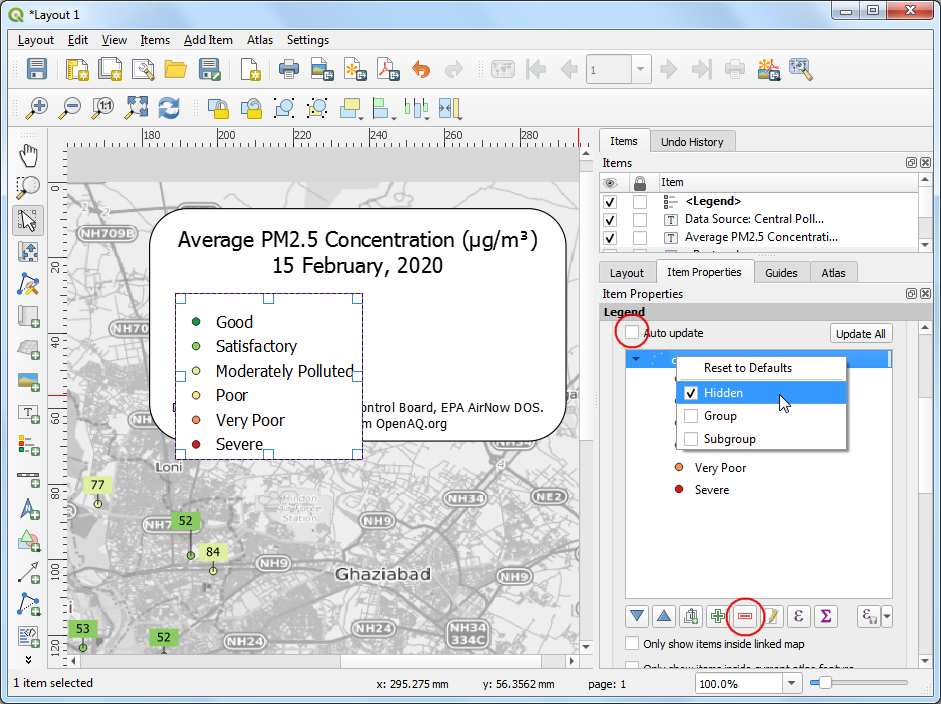
- 图例默认位置是淑芝的,单独一列。可以将其改成多列,弄成水平。滚轮找到Columns区域,然后设置Count 为
2,再选中 Split layers。
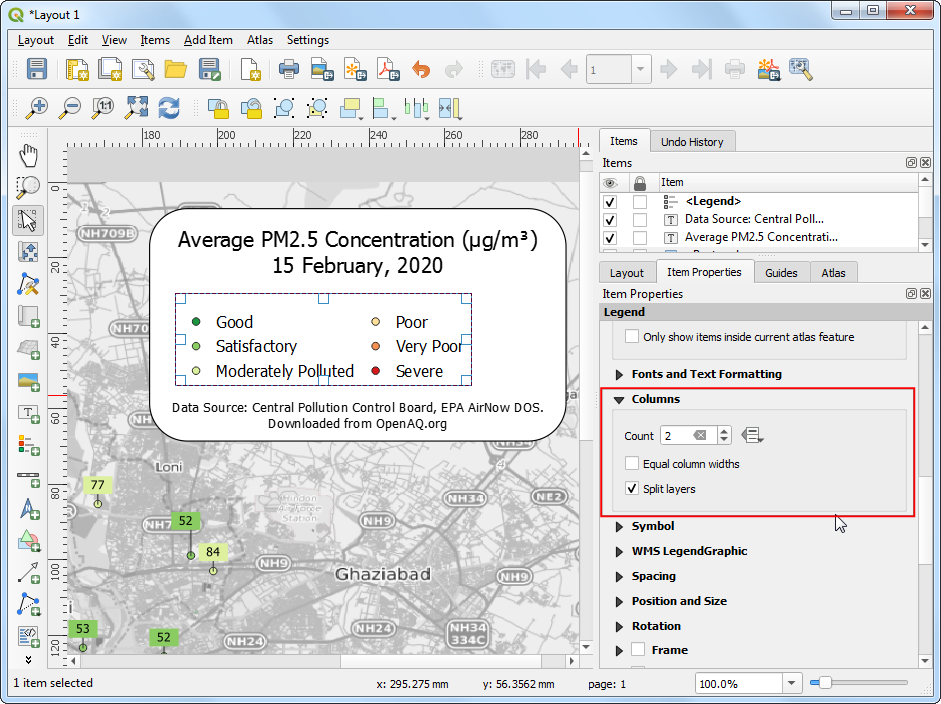
- 在Main Properties部分,输入一个比例尺的标题Title ,比如
Air Quality Index Category。
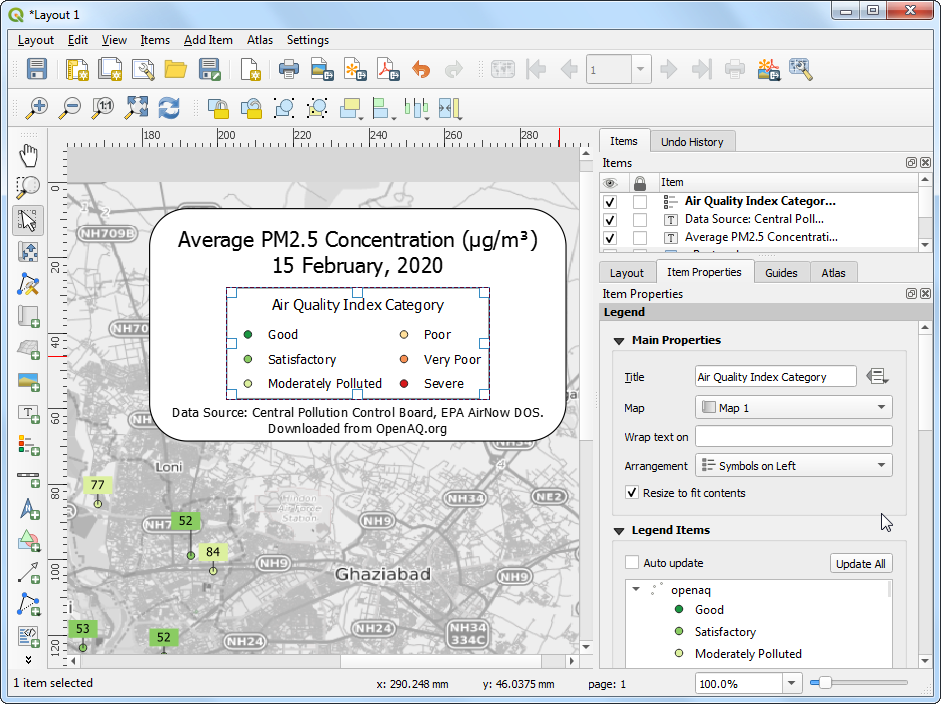
彻底设置满意了,就可以将地图输出了。如果你想放在网站上,就可以用图像Image 来导出。如果你以后可能要用矢量图编辑软件来修改,就可以考虑存成 SVG 格式,这样你就可以使用 InkScape来编辑了。不过一般更通用的可能还是PDF格式。

Credit: Atanas Entchev
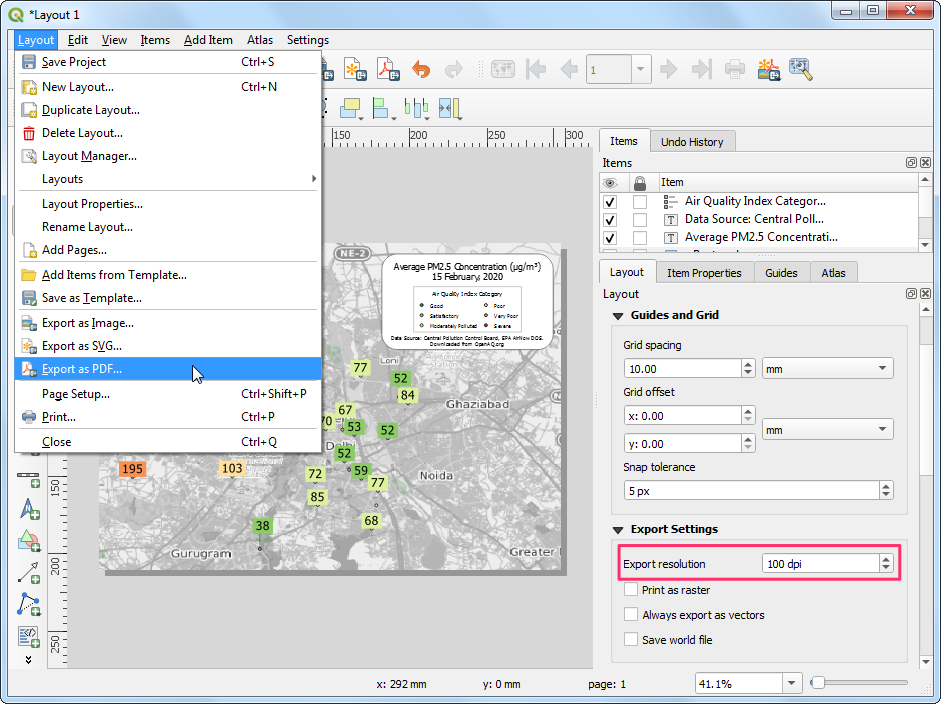
- 所以接下来就用PDF格式来导出吧。导出之前,切换到布局Layout标签页。我们使用的是OpenStreetMap 的位图地图作为底层。这是使用对缩放有依赖的切片地图绘制的。所以有必要设置一个较高的导出分辨率,以便获得更清晰的更高分辨率的切片地图。另外导出的分辨率Export resolution 可以设置到
100dpi,更高当然也行。菜单栏中找到 Layout → Export as PDF然后试试吧。
- 在导出选项PDF Export Options 中选中 Create Geospatial PDF (GeoPDF),这个GeoPDF 是一种增强的PDF格式,具有空间感知,并且保留了图层和属性信息。点击Save 将该文件保存为
air_quality.pdf.
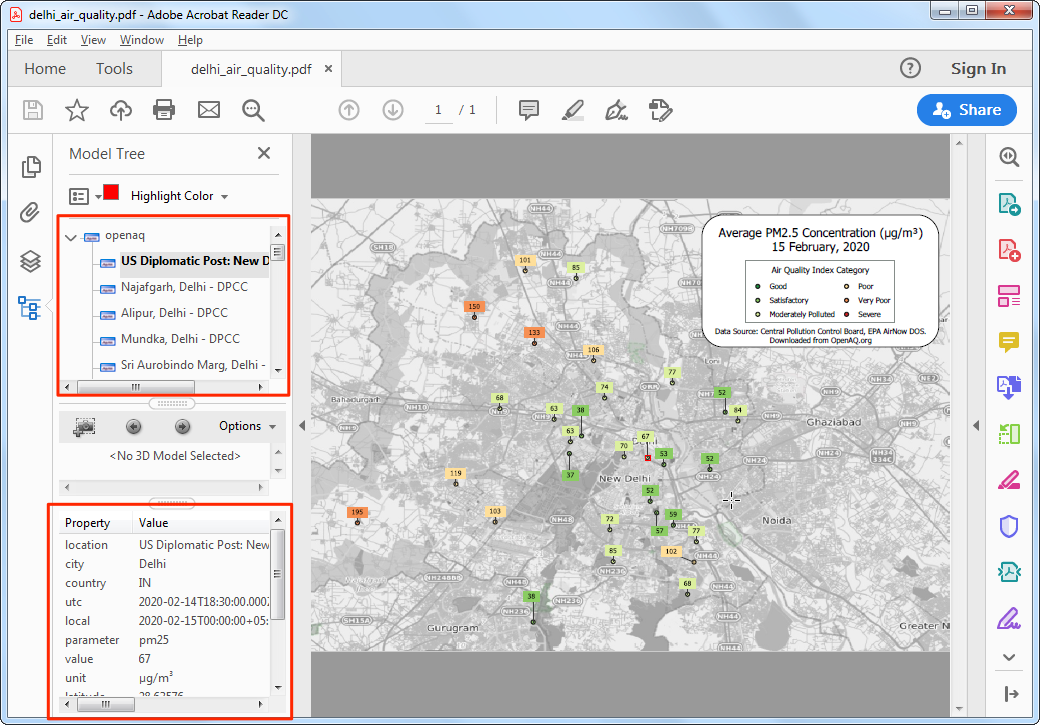
- 如果你在兼容的阅读其中打开对应的这个新生成的PDF文件,比如使用Adobe Acrobat,你就能看到各个图层的元素,还可以读取特征属性,计算距离等等。
在 Adobe Reader 中,针对 GeoPDF 可以在工具-测量Tools → Measure中启用测量工具。更多信息参考Adobe 官方网站。
线条 Lines
路、桥、铁轨等很多交通设施,以及河流、溪水等自然景物,都可以用线条来建模。其它一些抽象概念,比如轮廓、轨迹等等也可以使用线性特征来建模。用于存储线条数据集的一般有Shapefiles、GeoJSON、GPX等文件格式。
练习:GPS轨迹可视化
如今生活里,GPS轨迹随处可见。大多数智能手机都内置了GPS系统,人们普遍用GPS来记录跑步或者骑行等户外活动。网约车公司也在乘客乘坐期间记录里程来计费。快递和物流公司从他们的快件中存储并分析了大规模的GPS数据来推导出位置智能(location intelligence)。
这个练习中,我们使用的是一个开源的GPS位置记录APP ,可以运行在Android设备上。如果你用的是iOS设备,推荐你可以试试另一个开源应用Open GPX Tracker。存储GPS轨迹的默认格式是GPS Exchange Format (GPX)。这实际上是一种基于XML的文本格式,允许在一个文件中存储点、轨迹和路径。本次练习使用的是sample_gps_track.gpx 文件,目的是要创建一个动态的GIF图来展示整个行程。
- 将
sample_gps_track.gpx文件拖动添加到QGIS的画布上。
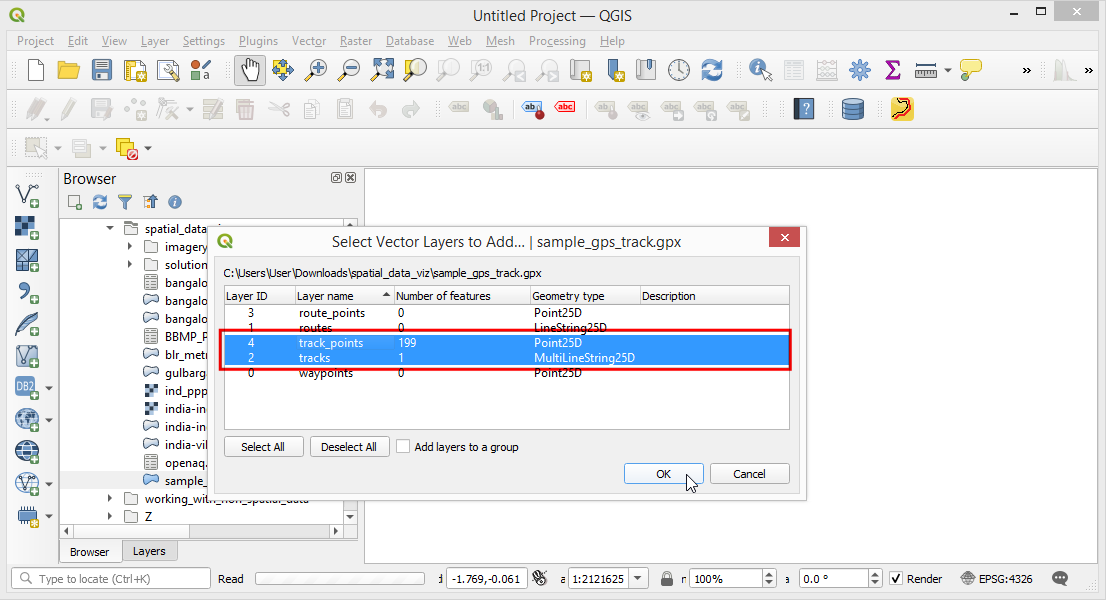
- 由于文件中有多条数据类型,程序会弹出一个窗口询问你选择要添加的图层(layers)。这时先按住 Shift 键不放,然后同时选中
track_points和tracks这两项,然后点击OK。
- 然后要添加地图,对这种情况来说,暗一点的背景地图视觉效果比较好。在菜单栏中找到Web → QuickMapServices → CartoDB → Dark Matter,点击后就在画布上添加了地图了。
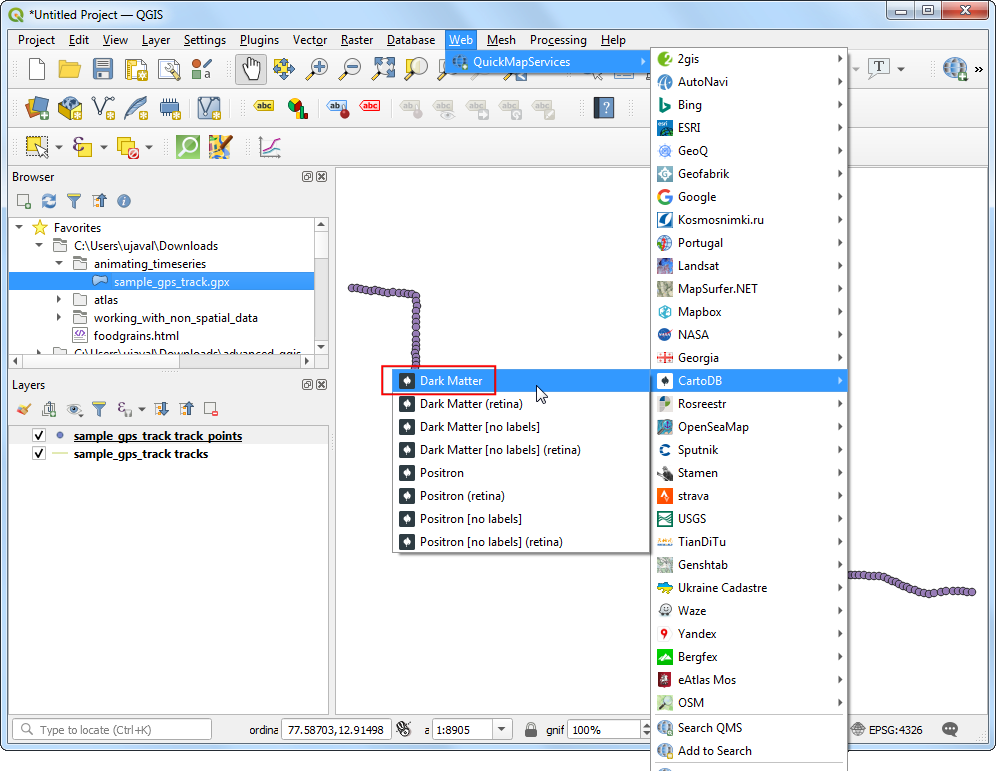
- 点击
sample_gps_track points图层旁边的小方块,去掉勾选,在画布中就看不到这些点了。选中sample_gps_track tracks图层,然后点击 Open the Layer Styling Panel。将颜色Color 改成蓝色Blue,然后设置线宽度Width 为0.5。
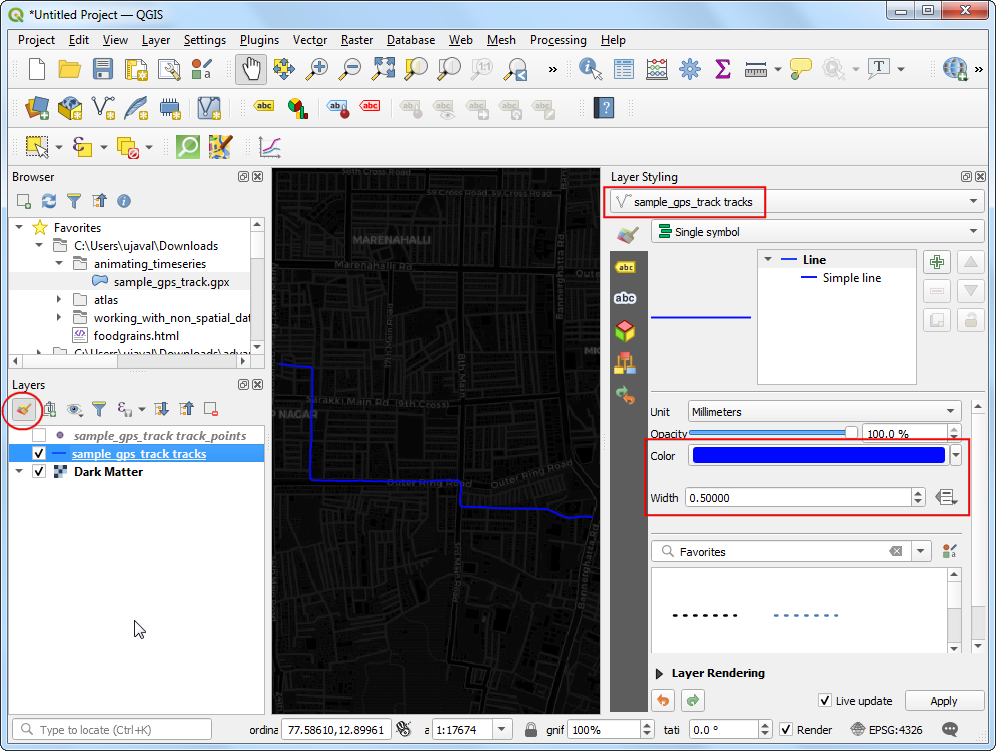
- 再选中
sample_gps_track points图层使之可见。在Layer Styling Panel中,选择简单符号Simple marker 。把点的大小Size 设为1。选择一个浅蓝色作为填充色Fill color,然手设置轮廓颜色Stroke color为透明Transparent Stroke。
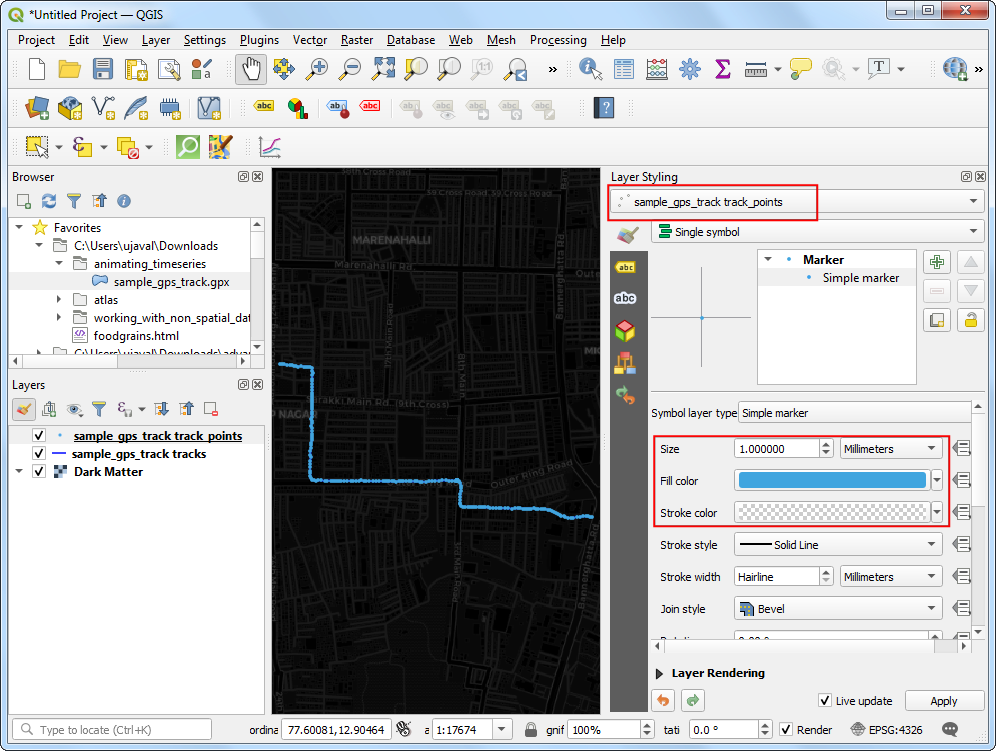
- 我们希望点动起来,所以要给他加一个辉光效果(glow effect)。右键
gps_points图层,然后选择复制图层Duplicate Layer。
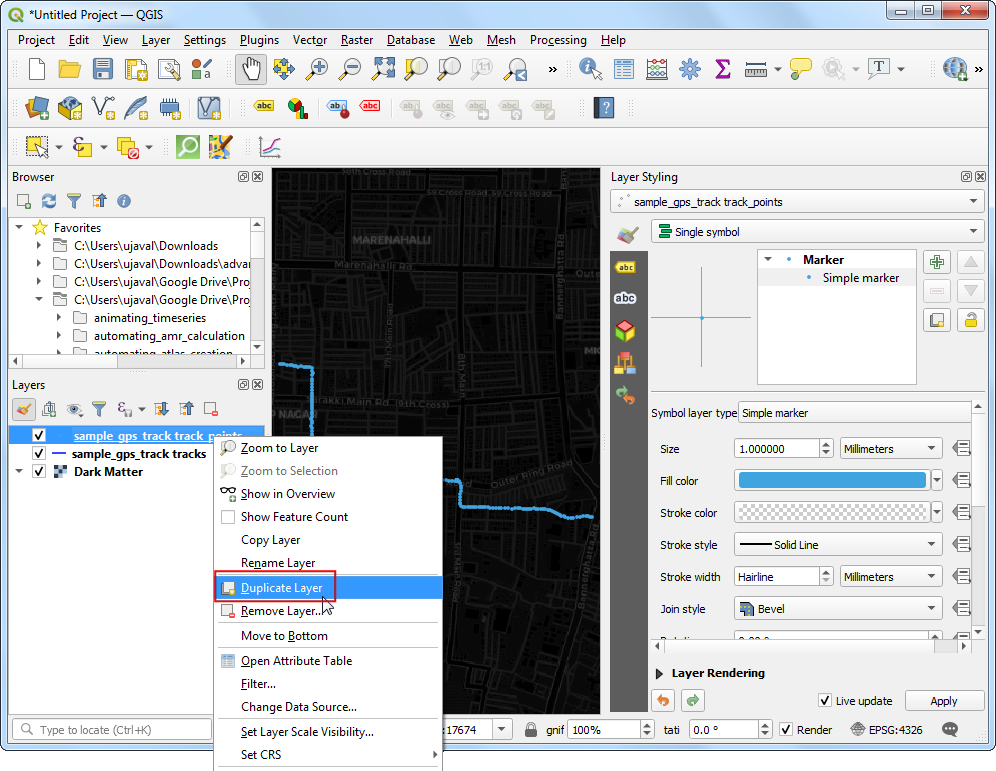
- 在图层面板Layers中将复制出来的图层拖动到图层栈的最顶层。在复制的
sample_gps_track points_copy的Layer Styling Panel,选择一种明亮色彩作为Color,然后增加尺寸到1.5,选中Draw Effects ,然后点击旁边小星星样子的 Effects 按钮。
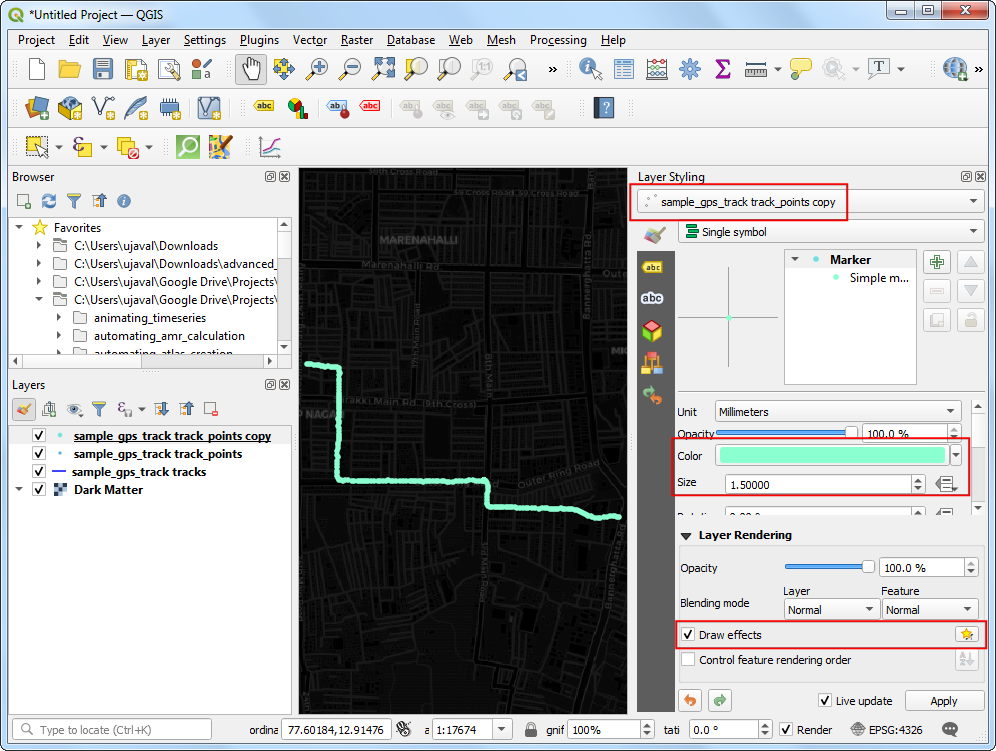
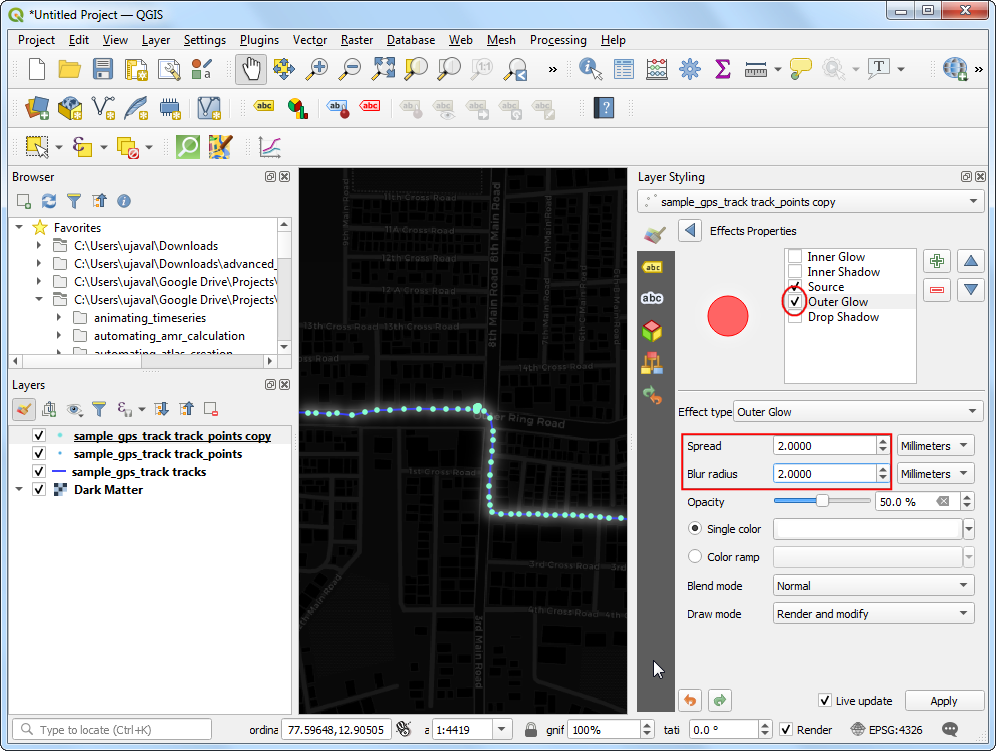
- 然后出现Effects Properties 面板,选中 Outer Glow,设置Spread 和Blue radius都为
2.0。
- 现在就可以让点动起来了。右键
sample_gps_track points_copy图层后选中属性Properties。
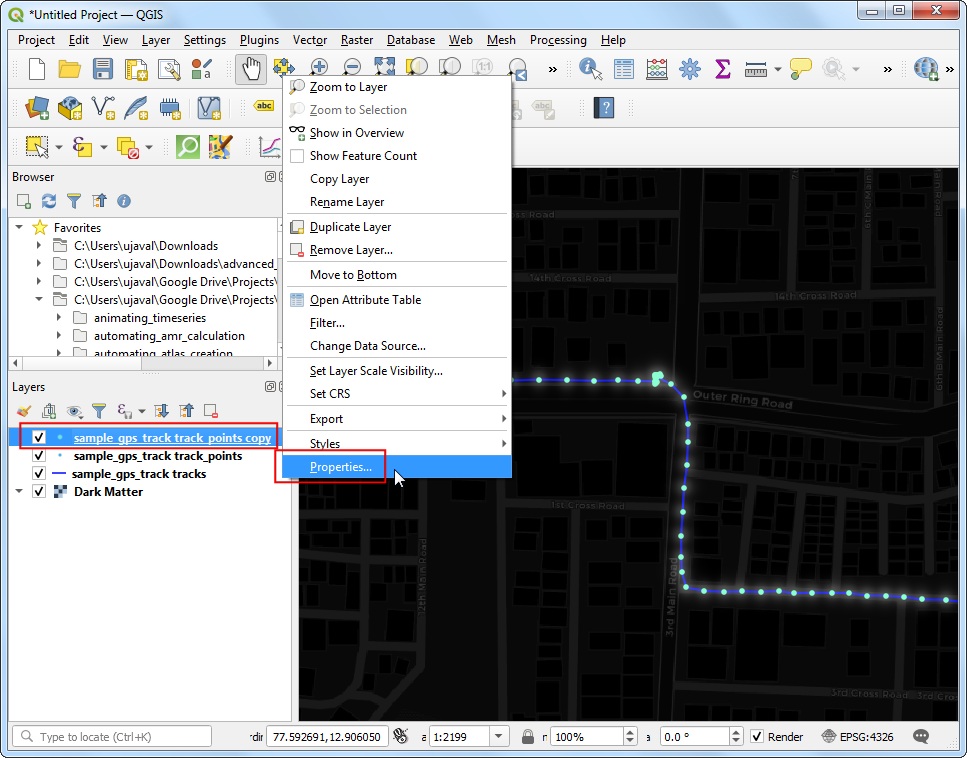
10.切换到Temportal 标签,勾选上Temportal 小方块。然后将设置Configuration调整为Single Field with Date/Time。设置Field为时间time ,然后点击OK。
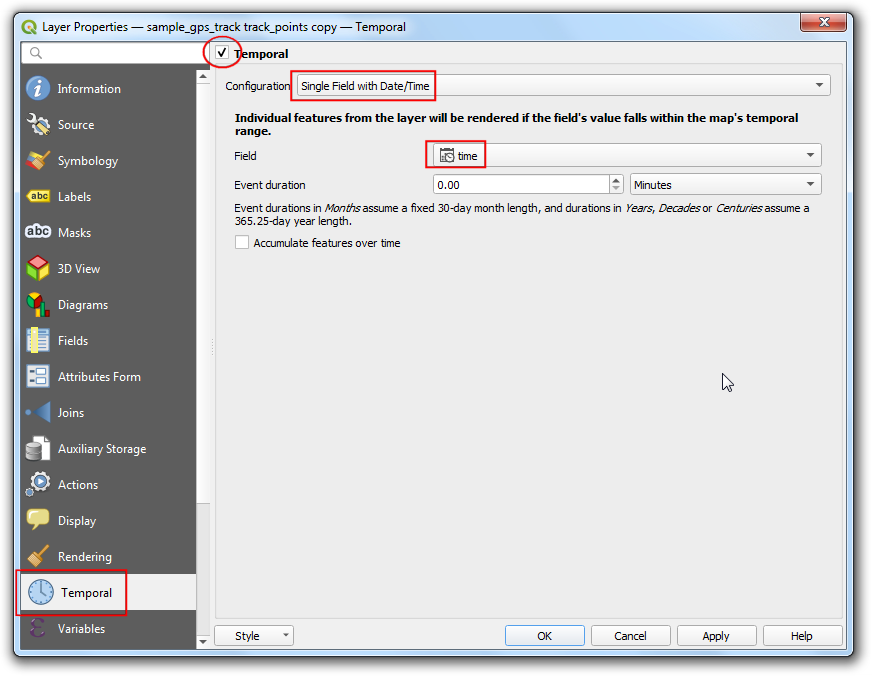
- 现在你会发现刚刚修改的图层旁边出现了一个小时钟图标,这就表示这个图层可以通过Temporal Controller来控制了。接下来,右键
sample_gps_track points图层点击Properties。
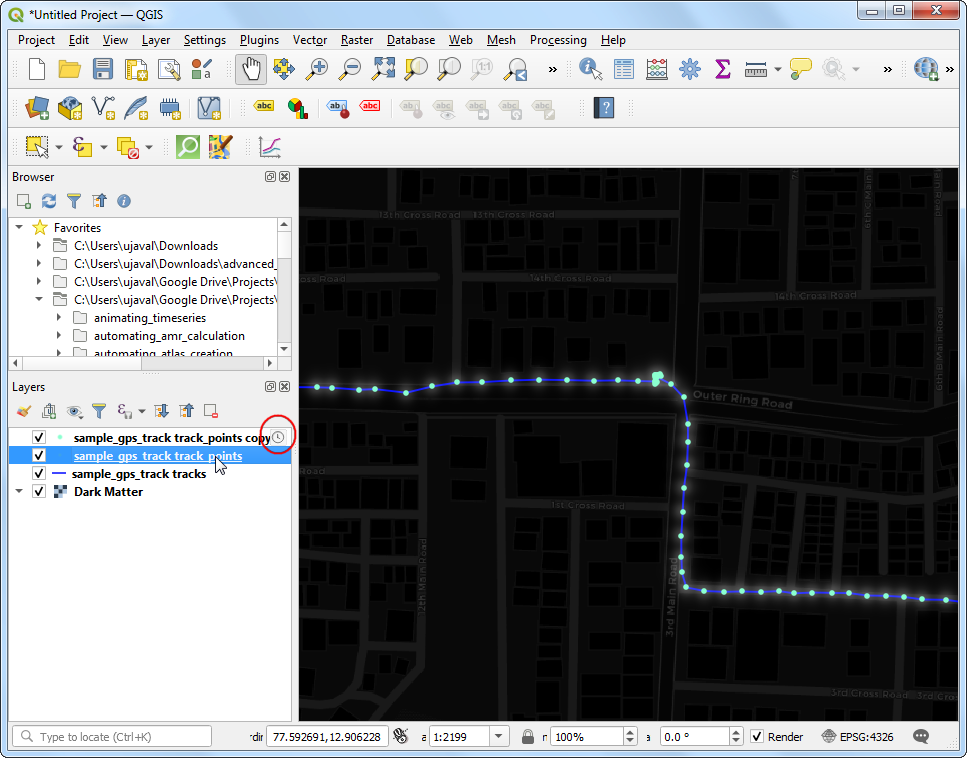
- 重复上一次的设置操作。不过这回将设置Configuration调整为Accumulate features over time。这样设置是要让已经过去的时间点依然在图层上能显示出来。
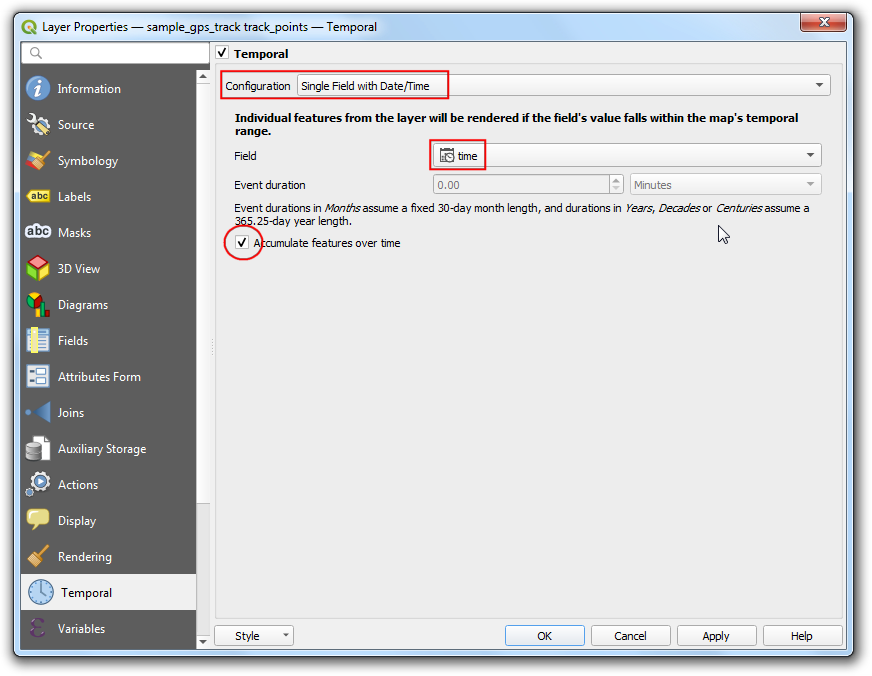
- 在主界面的Map Navigation Toolbar中找到Temporal Controller Panel 。
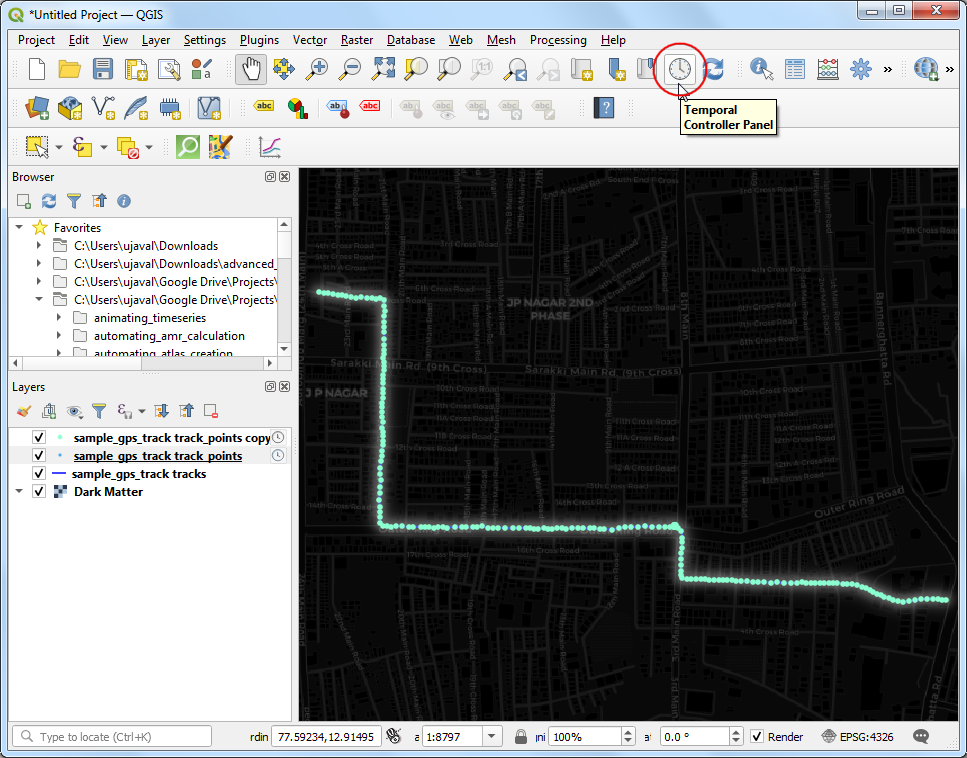
- 点击之后, Temporal Controller 面板就会出现在画布地图顶端了。点击像播放按钮一样的Animated temportal navigation 按钮。
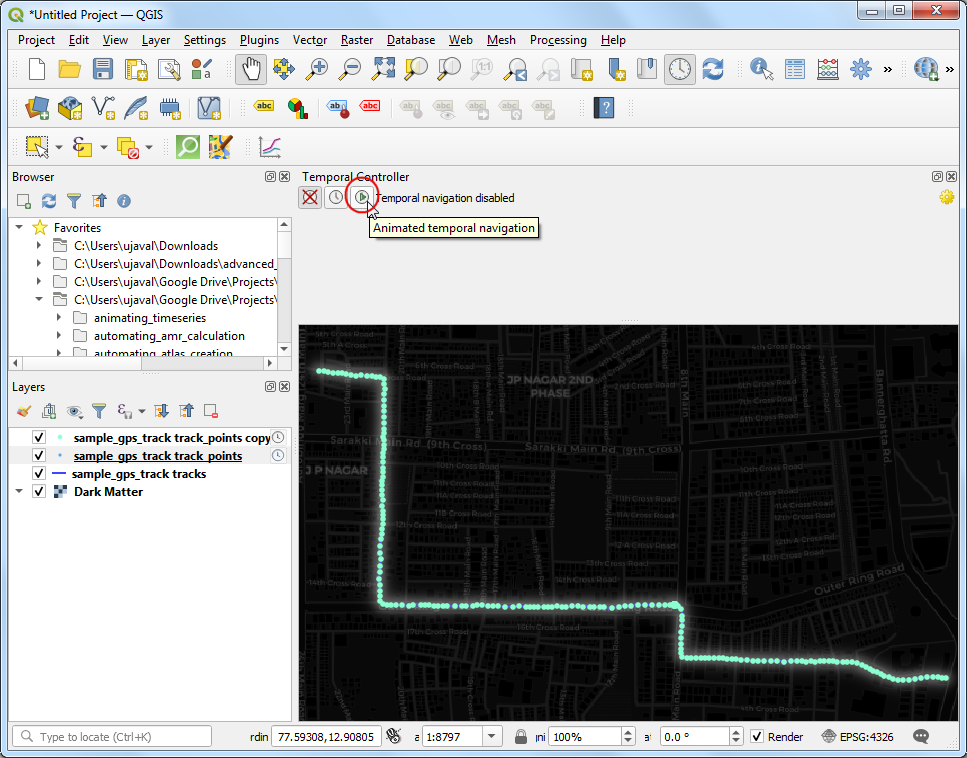
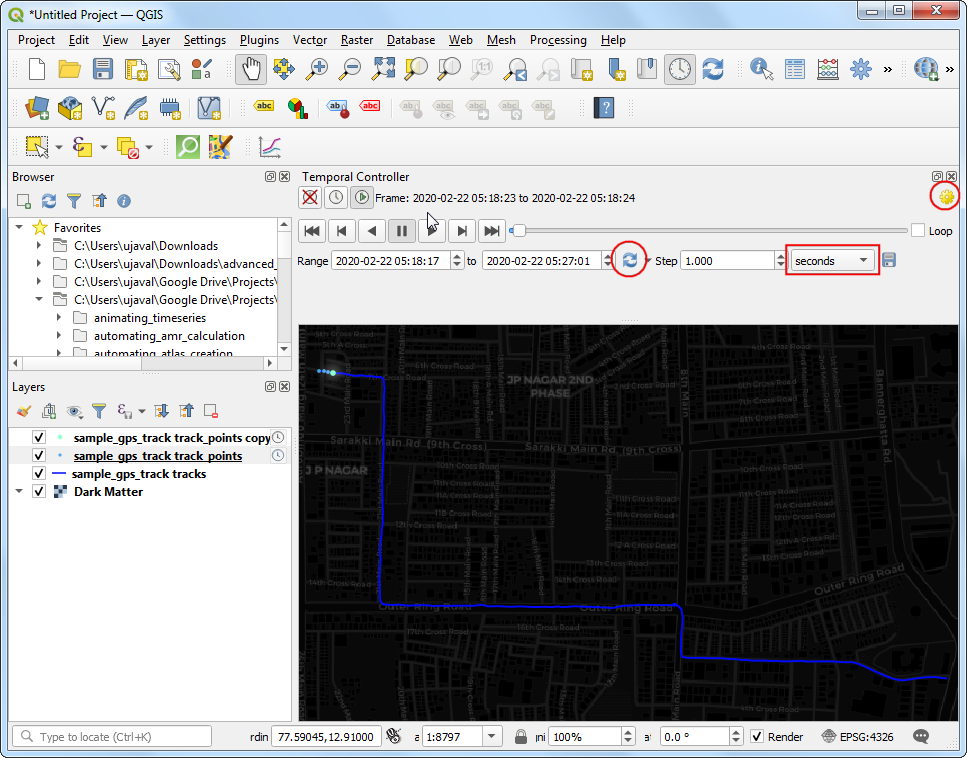
- 接下来,点击刷新形状的Set to Full Range按钮来自动加载起止时间。将步长 Step 设置为
1,然后单位选择成秒 seconds,点击右上角齿轮图标Temporal Settings 。
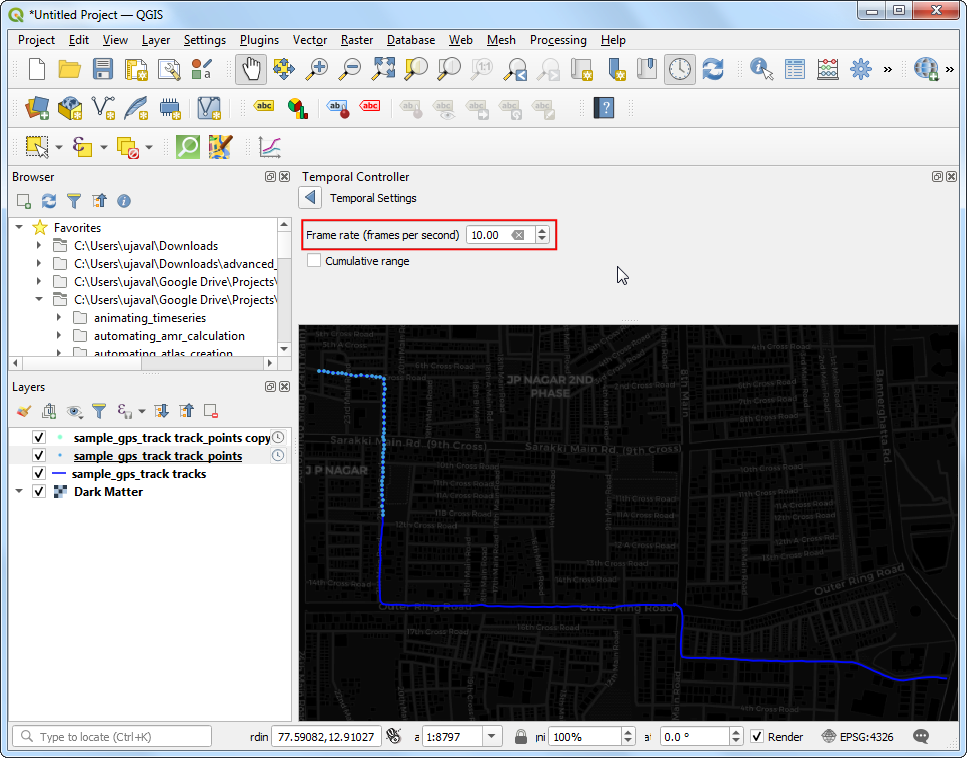
- 将帧率 Frame rate 设置为
10。
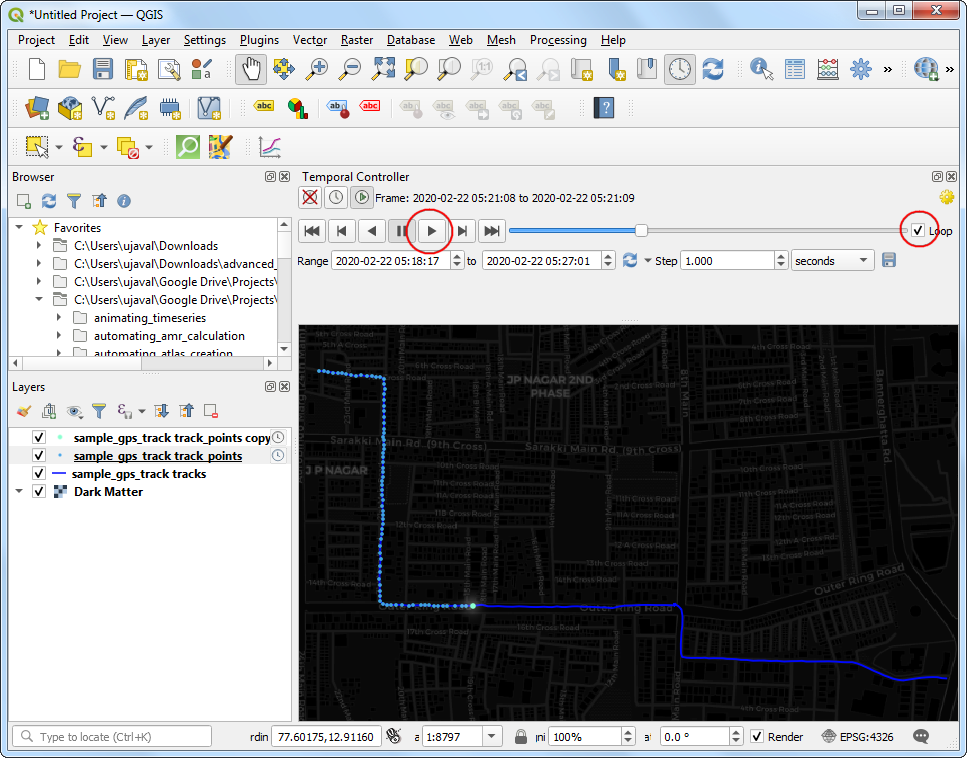
- 设置完后返回刚刚的界面,选中循环Loop,然后点击播放按钮 Play 。你就能看到画布上的地图现实旅行过程了。
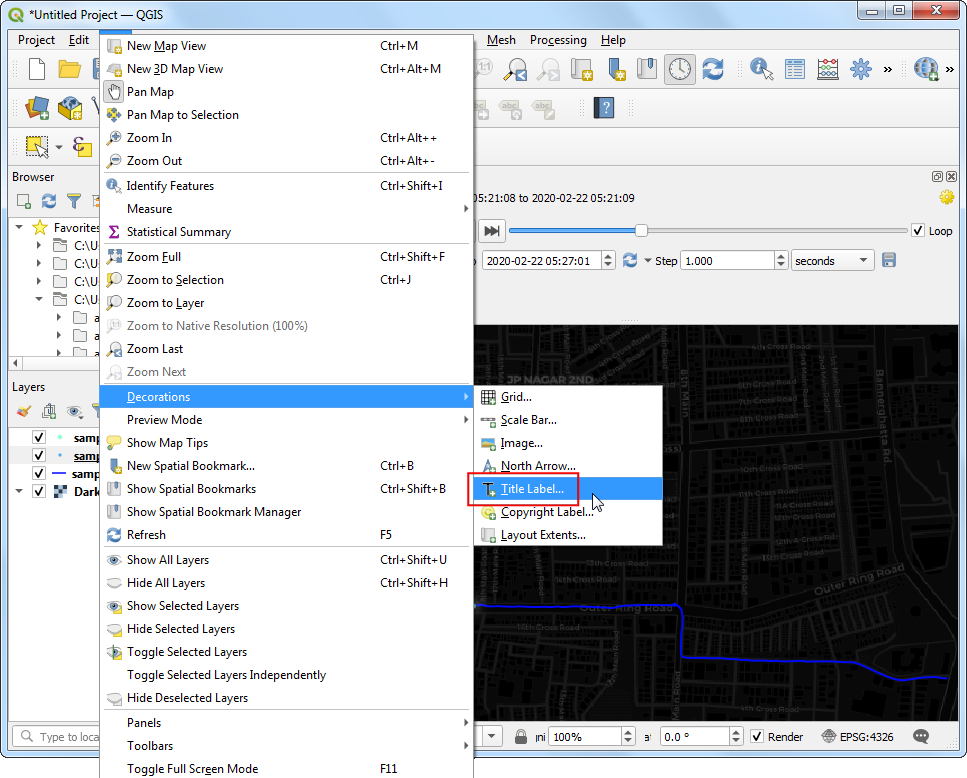
- 将每个点所对应的时间显示在地图上应该挺有用,到菜单栏中找到View → Decorations → Title Label…来设置。
- 在标题备注设置Title Label Decoration中,点击插入表达式按钮 Insert an Expression 。
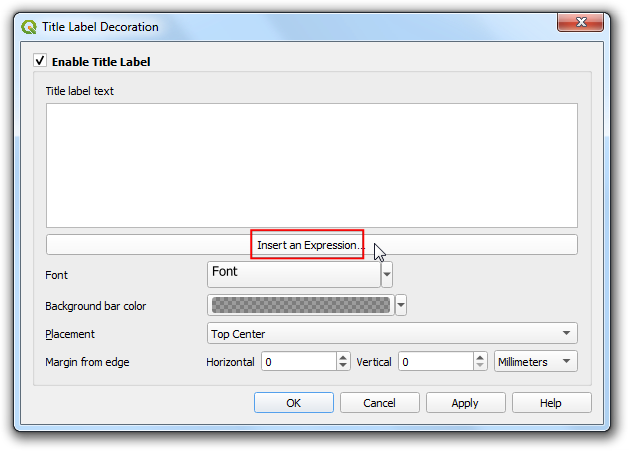
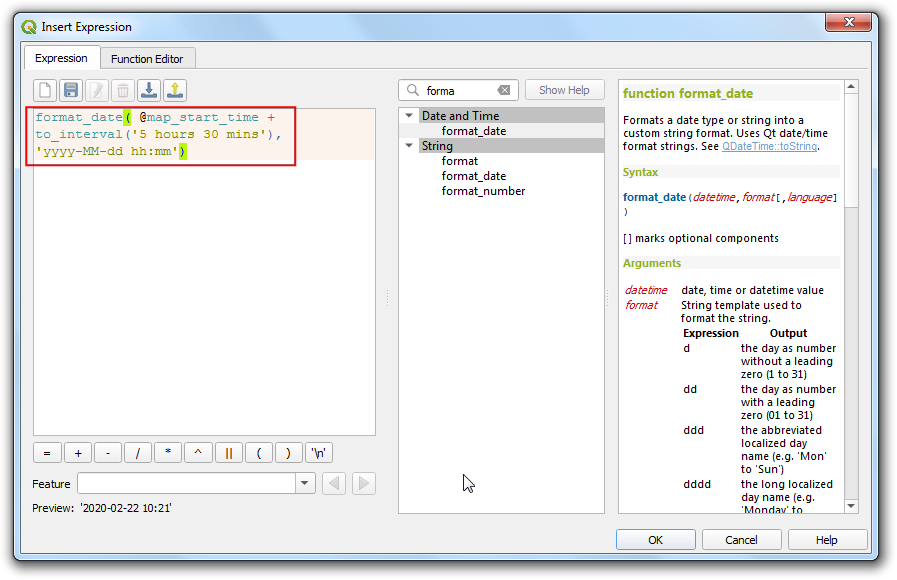
- 地图的当前时间存储在
@map_start_time这个变量中,可以使用format_date()函数将其转换成更可读的时间戳。但要注意 GPS系统的时间使用的是世界时(universal time,UTC),所以要用to_interval()函数将其转换到 UTC+8:00 才对应了北京地区的时区,输入下面的表达式:
format_date( @map_start_time + to_interval('8 hours'), 'yyyy-MM-dd hh:mm')
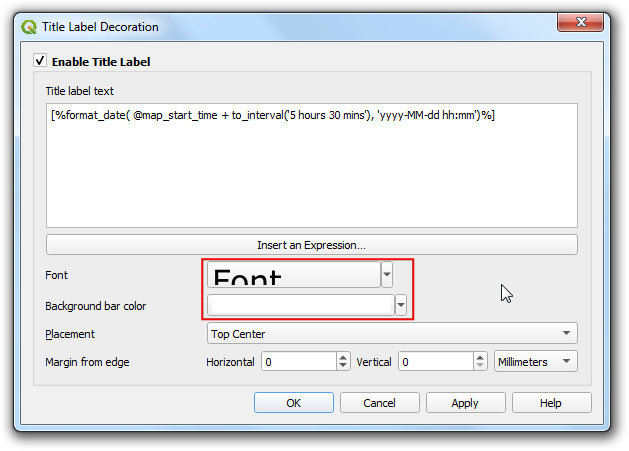
- 点击字体选项Font ,把字号调整到
24,设置背景色Background bar color 为白色White,点击OK。
- 现在你再播放动画,时间戳就会随着动画中对应点的行进更新了。点击导出动画Export Animation 按钮可以将动画逐帧保存。
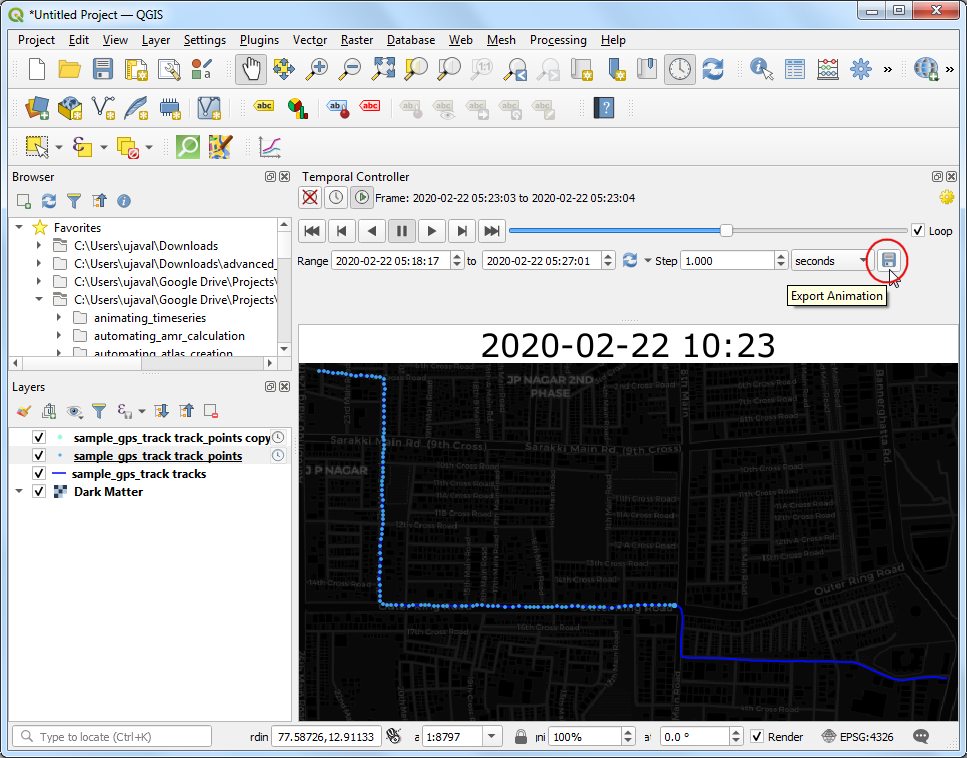
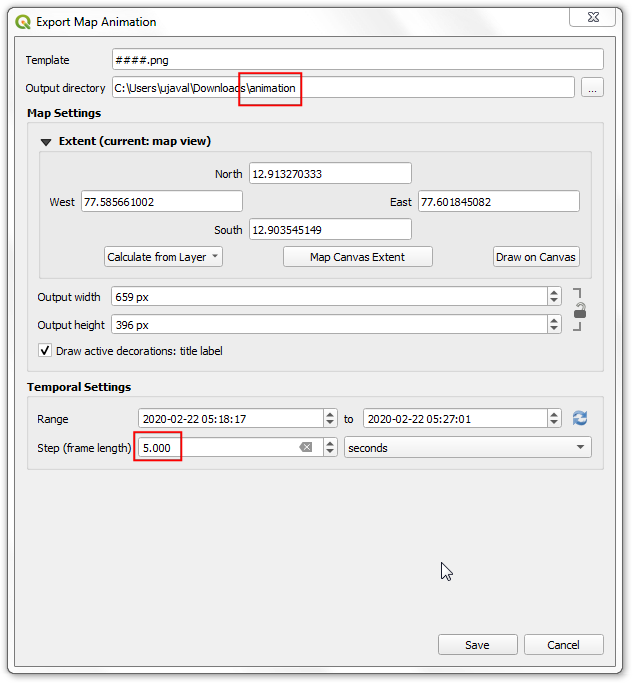
- 在弹出的Export Map Animation 对话框中,选择输出目录Output directory。这个文静可能有超过500秒的长度,所以可以降低帧数,将步长Step 设置为
5。然后点击保存Save ,QGIS就会在你选的文件夹中输出一系列图片了。
- 有了多张的逐帧图片后,就可以使用一些类似 ezgif.com 的工具来创建GIF动图了。
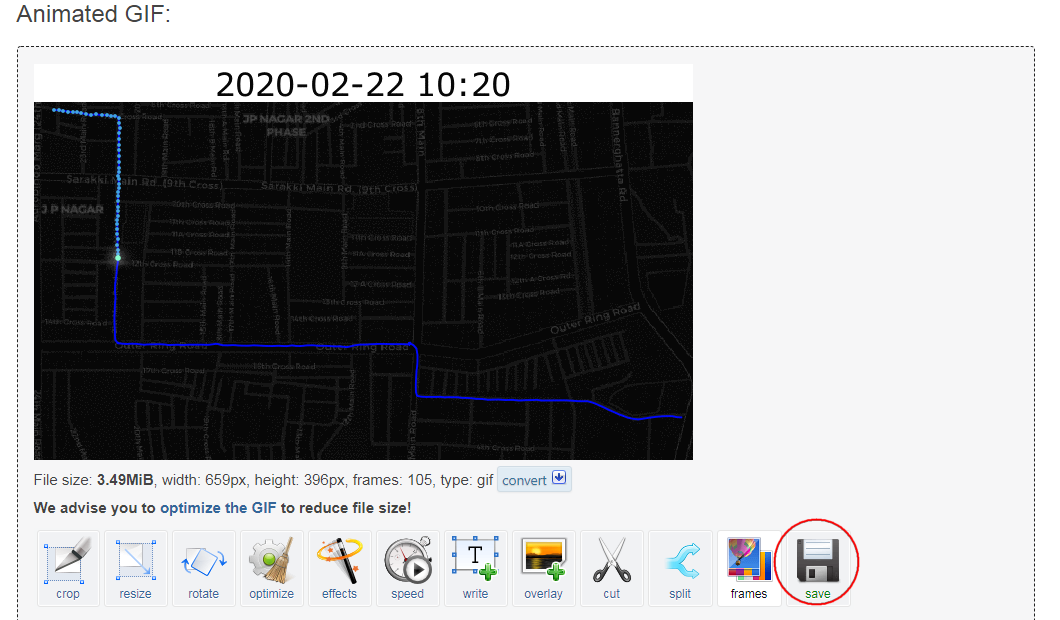
多边形
区域就用多边形来建模。一般用来表示行政区划、建筑物、地块等等。多边形在几何上就是用一系列的坐标来表示的。由于形状可能会非常复杂,多边形要有更加繁琐的几何解释,所以很少使用简单的CSV文件格式。GeoJSON和 ShapeFiles 是存储多边形数据集的常用文件格式。
练习:人口普查数据可视化
人口普查数据是一个国家二级数据的一个主要来源。很多空间分析都需要人口普查数据中的详细人口学信息。
Census data is usually published as tables by aggregating the raw numbers to an administrative region - typically a census block. To map these tables, one needs to know the geometry of these regions - which are supplied separately as boundary files. Both of these can be joined to create a polygon layer that can be visualized and mapped. See on how this process is carried out in QGIS.
人口普查数据一般都是按照行政区发布成一个个表格,表格里是对原始数据的汇总,这样一个行政区就成了一个人口区census block。要将这样的表格可视化成地图,就需要知道这些区域的几何形态,也就是边界文件。人口数据和行政区划结合到一起就可以制作出一个多边形图层,这个图层就能放到地图上进行可视化了。这个过程在QGIS中的操作可以参考这个教程 。
这个练习使用的是India Village-Level Geospatial Socio-Economic Data Set 这一数据集,由美国航天局社会经济数据和应用中心(NASA Socioeconomic Data and Applications Center,SEDAC)出版公布。此数据集中结合了村/镇一级的边界与印度人口普查的初级人口普查摘要(PCA)和村庄目录(VD)数据系列,使用 ShapeFiles 格式发布。
这个练习中使用的是印度Karnataka州的ShapeFile数据,将Gulbarga地区的识字率投在地图上。
- 将
india-village-census-2001-KA.shp文件拖动到QGIS画布上。
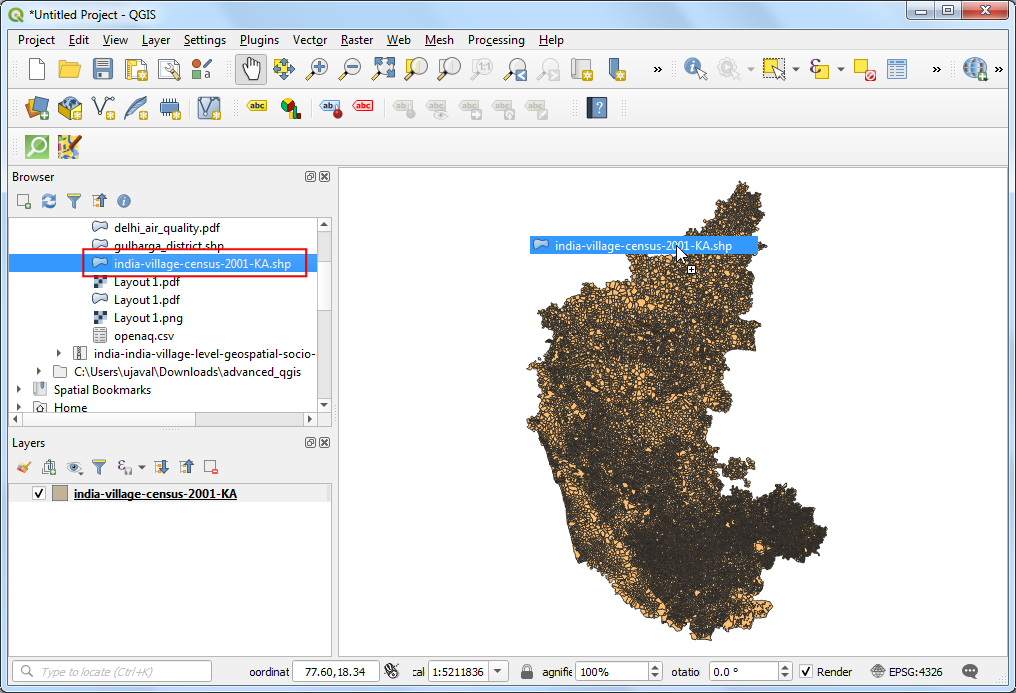
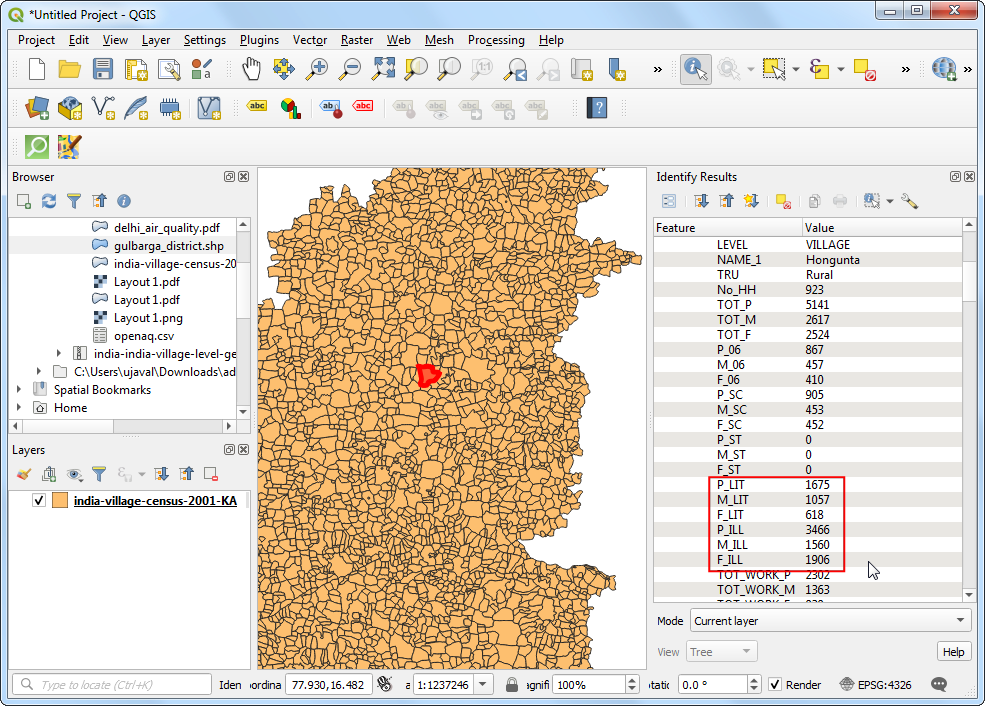
- 这样在图层面板Layers中就加入了新图层
india-village-census-2001-KA。使用Identify工具来点击任意一个多边形来查看属性值。每一列的定义都在数据的附加文档中有解释。我们要找的是识字率,对应的后缀_LIT就很有用。P_LIT这列表示的是识字人口,而TOT_P表示的是总人口Total Population,借助这两样我们接下来就要计算识字率。
- 接下来要从这个图层的众多多边形中选中属于Gulbarga 地区的子集。家在
gulbarga_district.shp。数据中DT_CEN_CD这一列包含的就是对应区域的ID。可以用这个 ID来过滤多边形区域,Gulbarga 地区的这个ID是4。
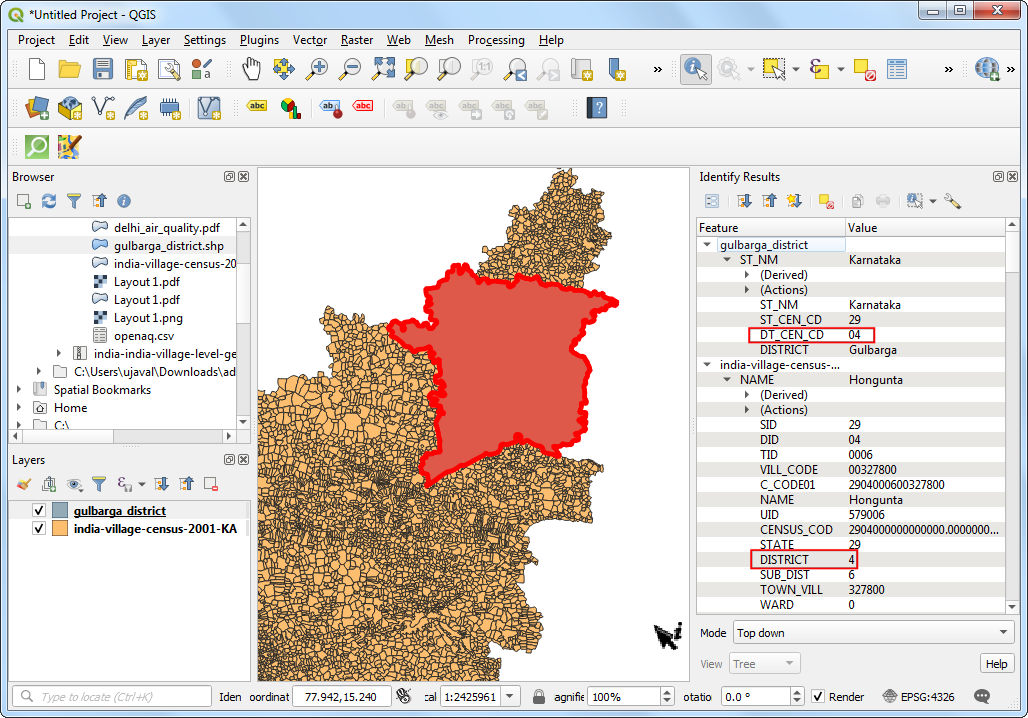
- 在图层Layers面板中,拖拽
gulbarga_district图层到india-village-census-2001-KA图层下面。右键india-village-census-2001-KA图层然后选中Filter进行筛选。
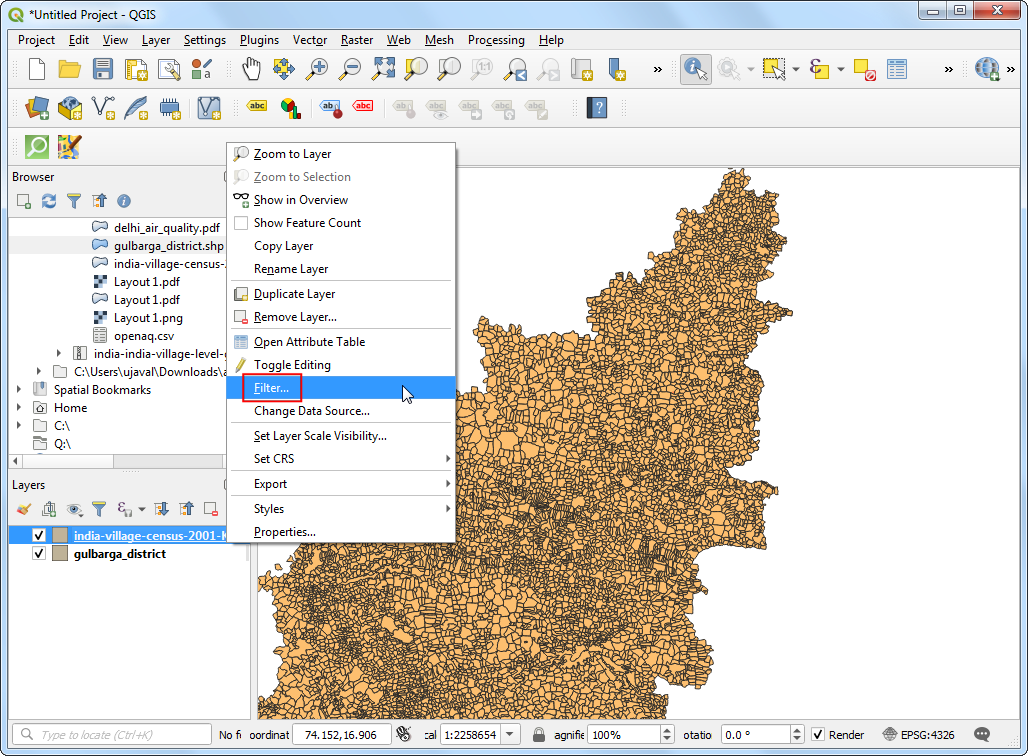
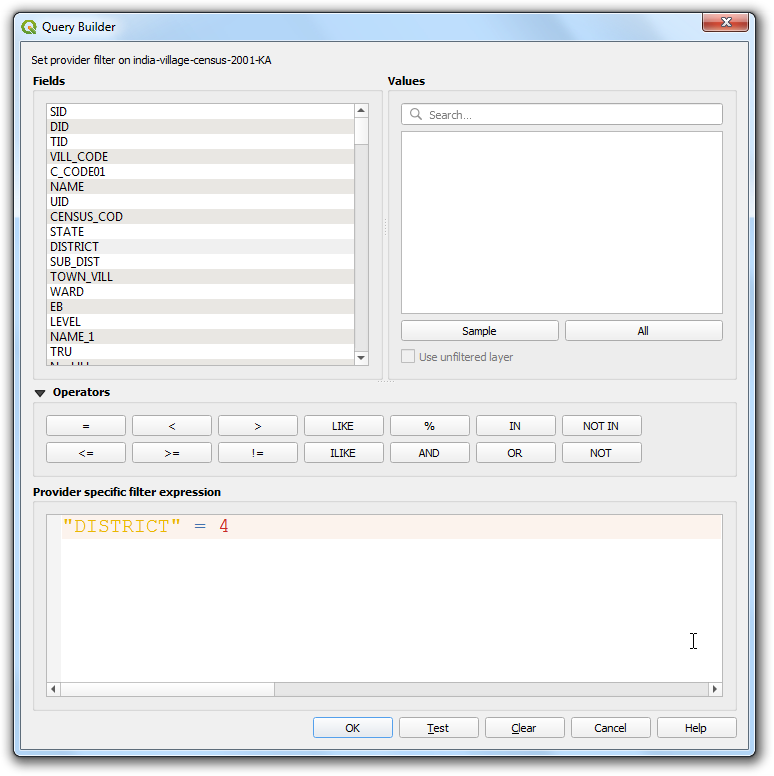
- 输入表达式
DISTRICT = 4来选择Gulbarga 地区对应的部分,点击 OK。
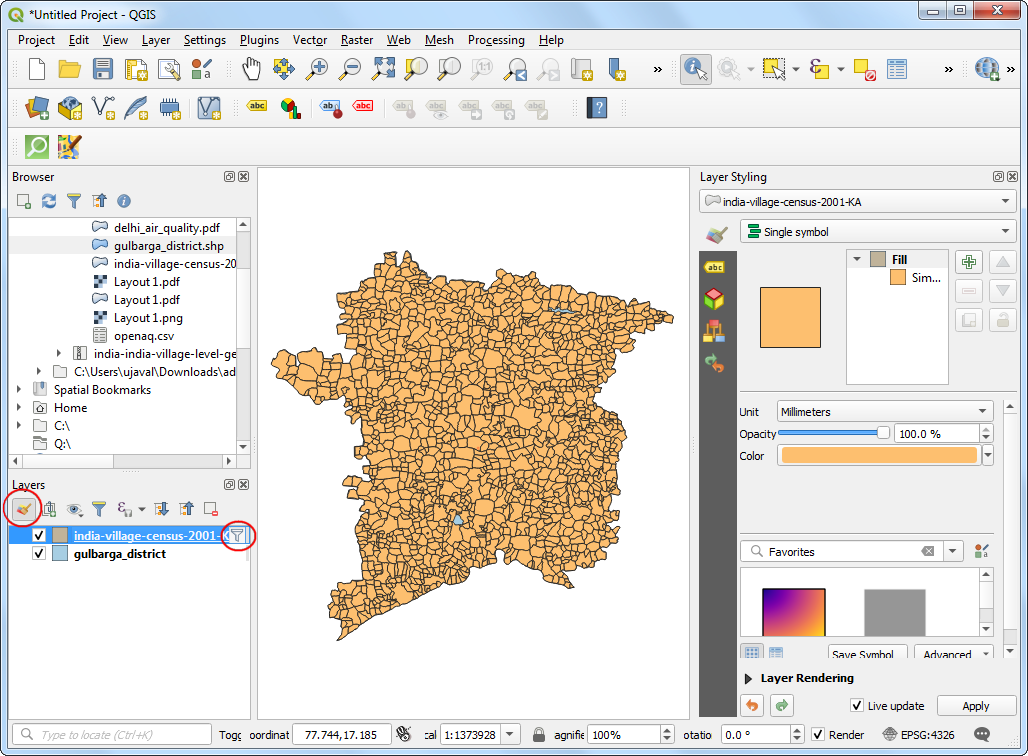
- 这时候在
india-village-census-2001-KA图层旁边就能看到一个小漏斗图标,表示有一个筛选被施加在该图层上。同时地图画布上也会更新,只显示所筛选区域的多边形。
- 接下来我们要创建一个热力图thematic 来展示该区域的识字率。这种场景下创建热力图(thematic (choropleth) map),需要对要投图的值进行标准化(normalize)。常见的错误是在这种地图上使用总数而非比率。
点击Open the Layer Styling Panel,选中Graduated 着色器。在Value列中点击表达式按钮 Expression。
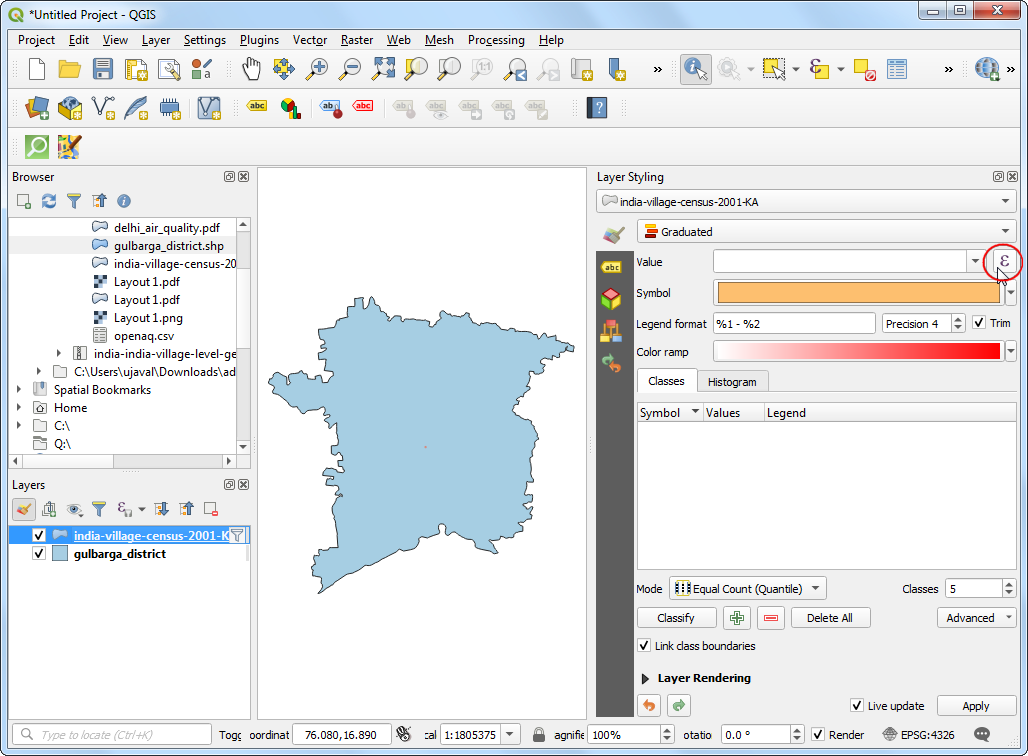
- 输入下面的表达式,由于我们要投图的是识字率,就可以通过识字人口除以总人口来实现标准化。
100*("P_LIT"/"TOT_P")
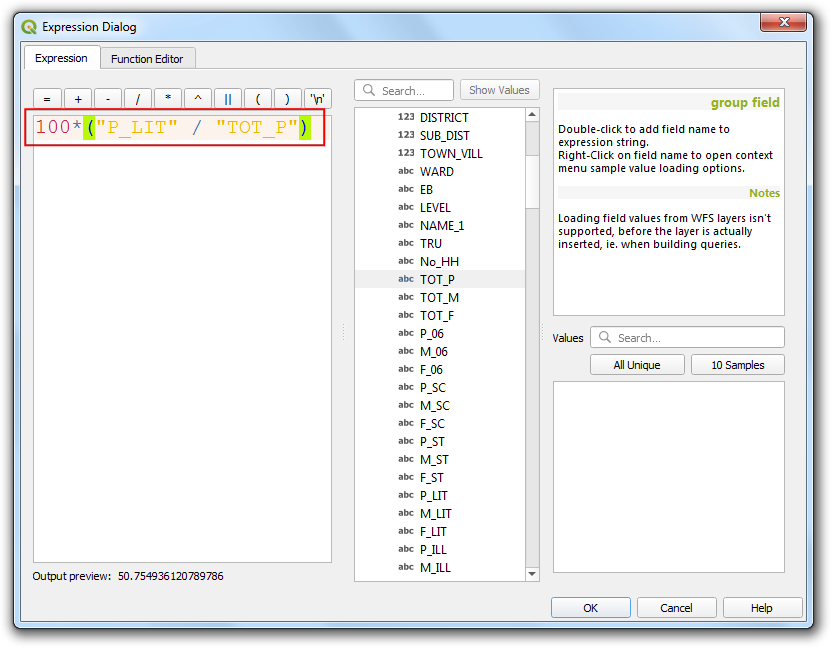
- 选中一个配色方案和分类模式Mode,然后点击分类按钮Classify。这里可以选择下拉Color ramp然后选中Invert color ramp 使得高值深色低值浅色。点击Apply应用后,就能看到多边形已经根据识字率着色了。这样就很明显能看出各地区的识字率差异。
将数据分类的方案有很多种,具体可以参考这篇文章 ,文中对各种分类模式的优劣进行了点评。
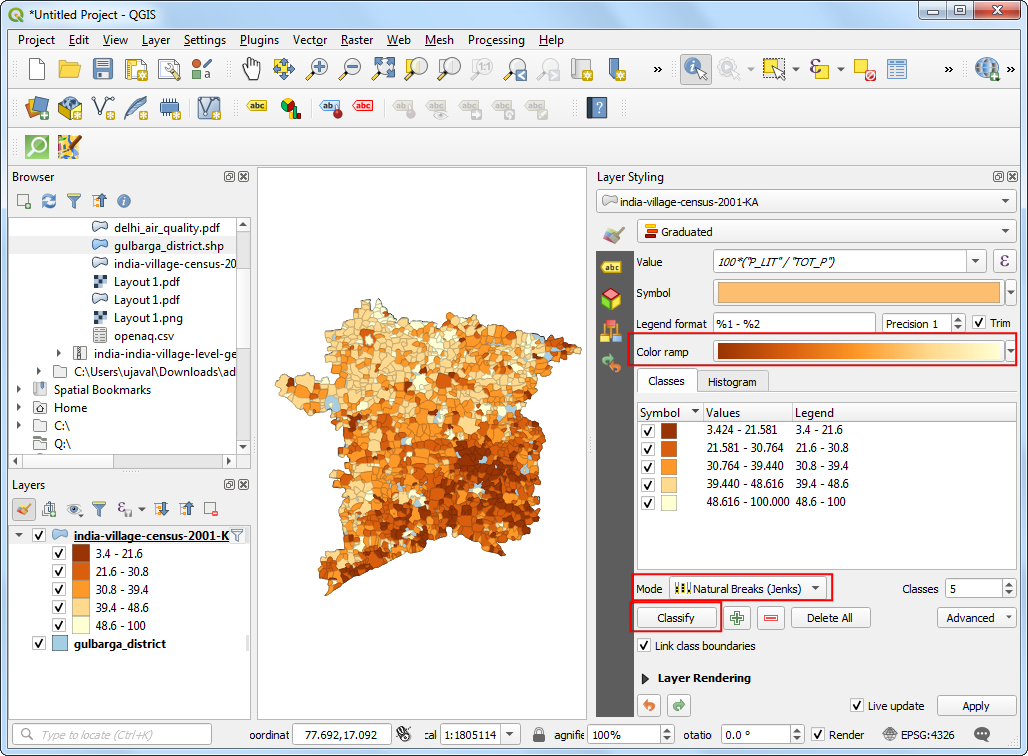
- 不过,如果你放大,就会发现多边形图层中间有空缺的地方。这是因为 you的城市没有对应的数据表格,因此就被排除在图层之外了。有这样的孔洞看着不太好,可以设计一种办法来插值推测这些缺少数据的值。选中
gulbarga_district图层,将 Symbol layer type设置为Line pattern fill,其他参数随便设置就好。
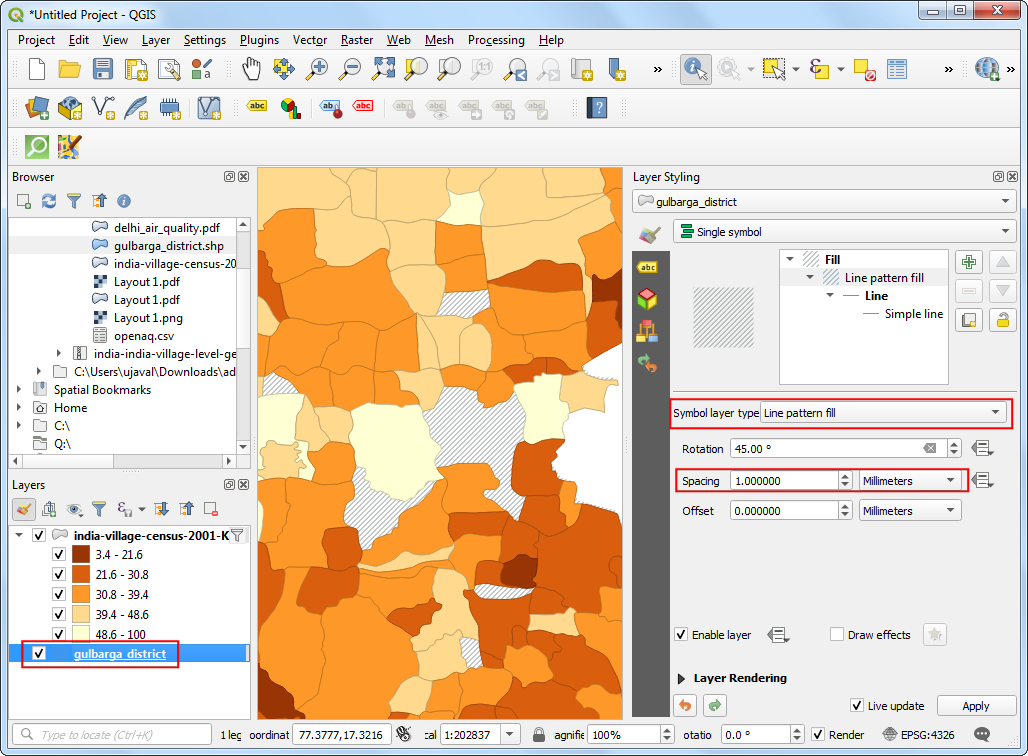
- 然后你会发现这里面没有交叉的填充样式。这很好办,只要用两个相互垂直的线条填充就可以实现了。在刚才的Layer Styling Panel标签页中点击 Duplicate the current layer 按钮。
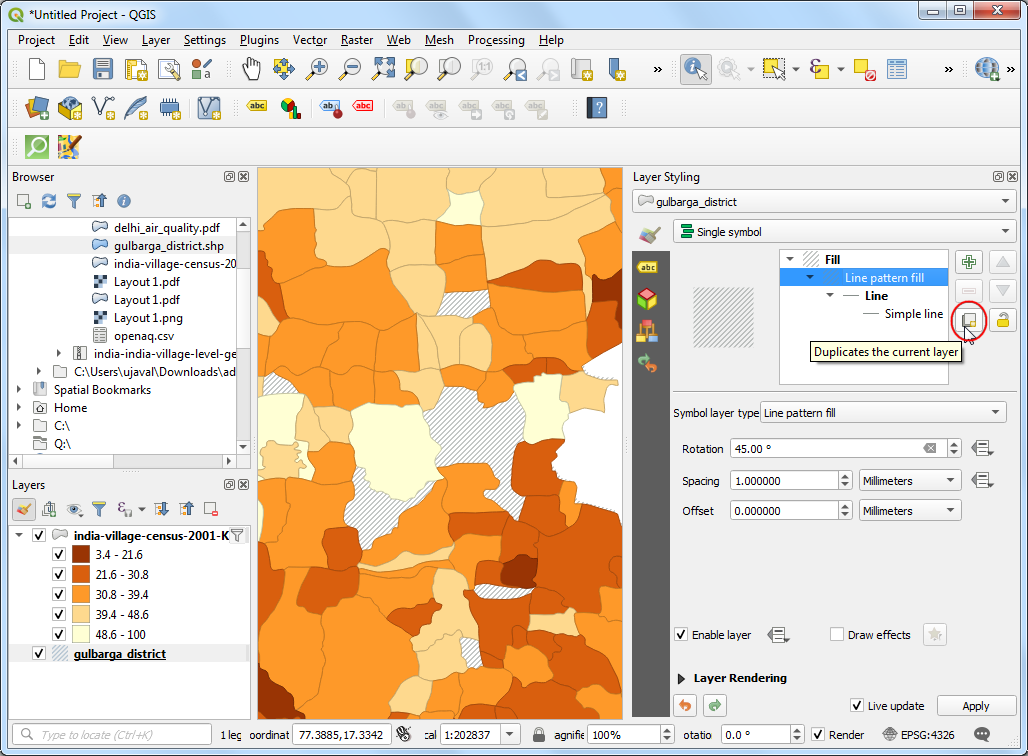
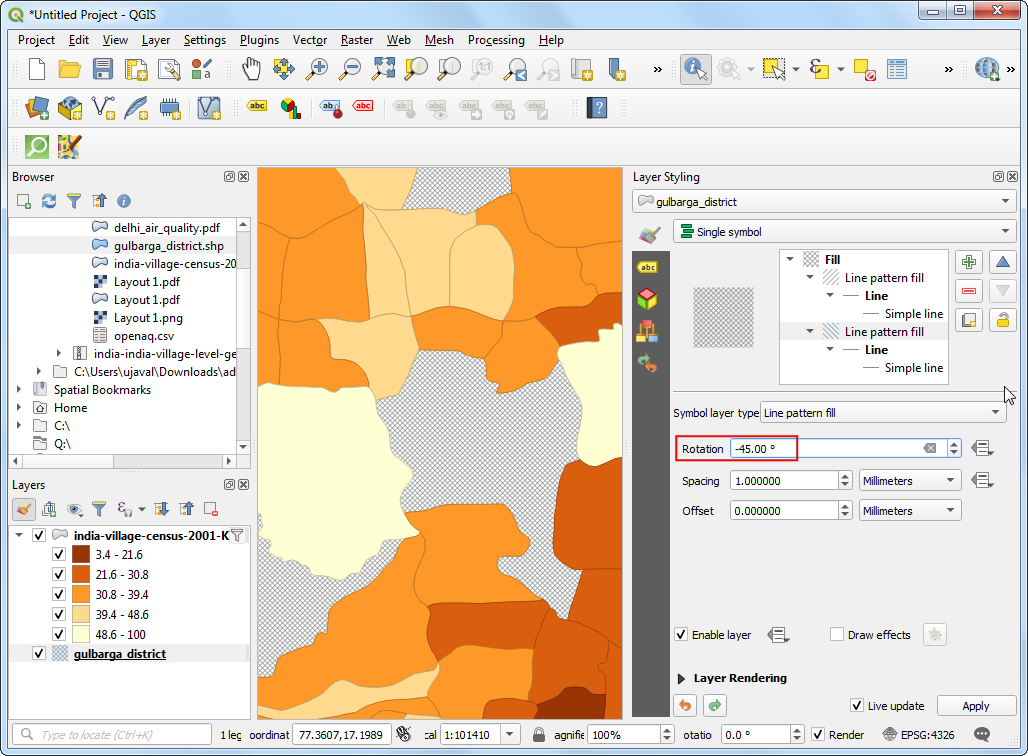
- 在新添加的线条填充上设置旋转角度Rotation 值为
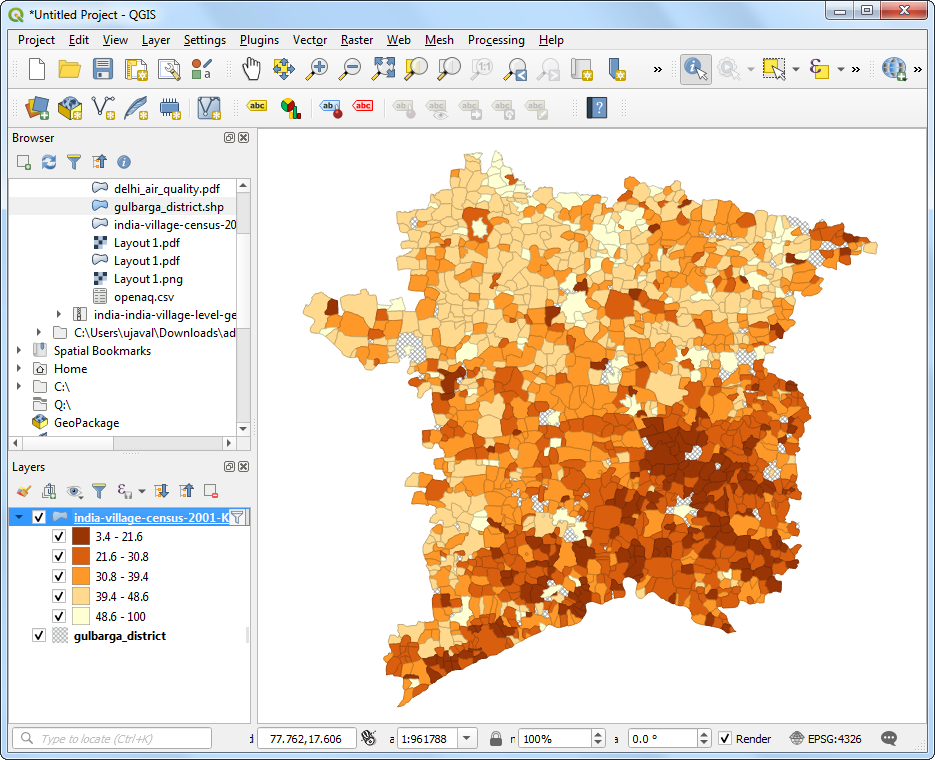
-45.00或者135.00,然后就会发现图中空白的位置已经被十字交叉填充了。
- 现在你就有了一个对该区域的识字率的可视化地图了。
栅格数据(Raster)-照片(Photos)
风筝、热气球、飞机、直升机以及无人机等等空中设备的传感器获取的图像,是绘制地图的重要信息来源。这些图像通常都是位图(basemap),为其他空间数据提供了基础。从这些位图中也可以提取特征信息,再建立模型成为矢量数据。
最常用的图像格式是 GeoTiff。一个 GeoTiff 文件包含了附加的元数据(metadata),允许用户将像素的行列位置与现实世界的经纬度位置进行对应。常规的照片也可以转换成这样带有空间感知的山歌数据,这种过程就叫做地理配准 GeoReferencing。
练习:查看无人机图像
OpenAerialMap 是一个提供无人机图像的分享和下载服务的开放网站。本次练习使用的是 WeRobotics 提供的加德满都大学操场(Kathmandu University Grounds)的照片。
- 将
kathmandu_drone_imagery.tif文件拖动到 QGIS 地图画布中,使用缩放和平移来查看这张图。
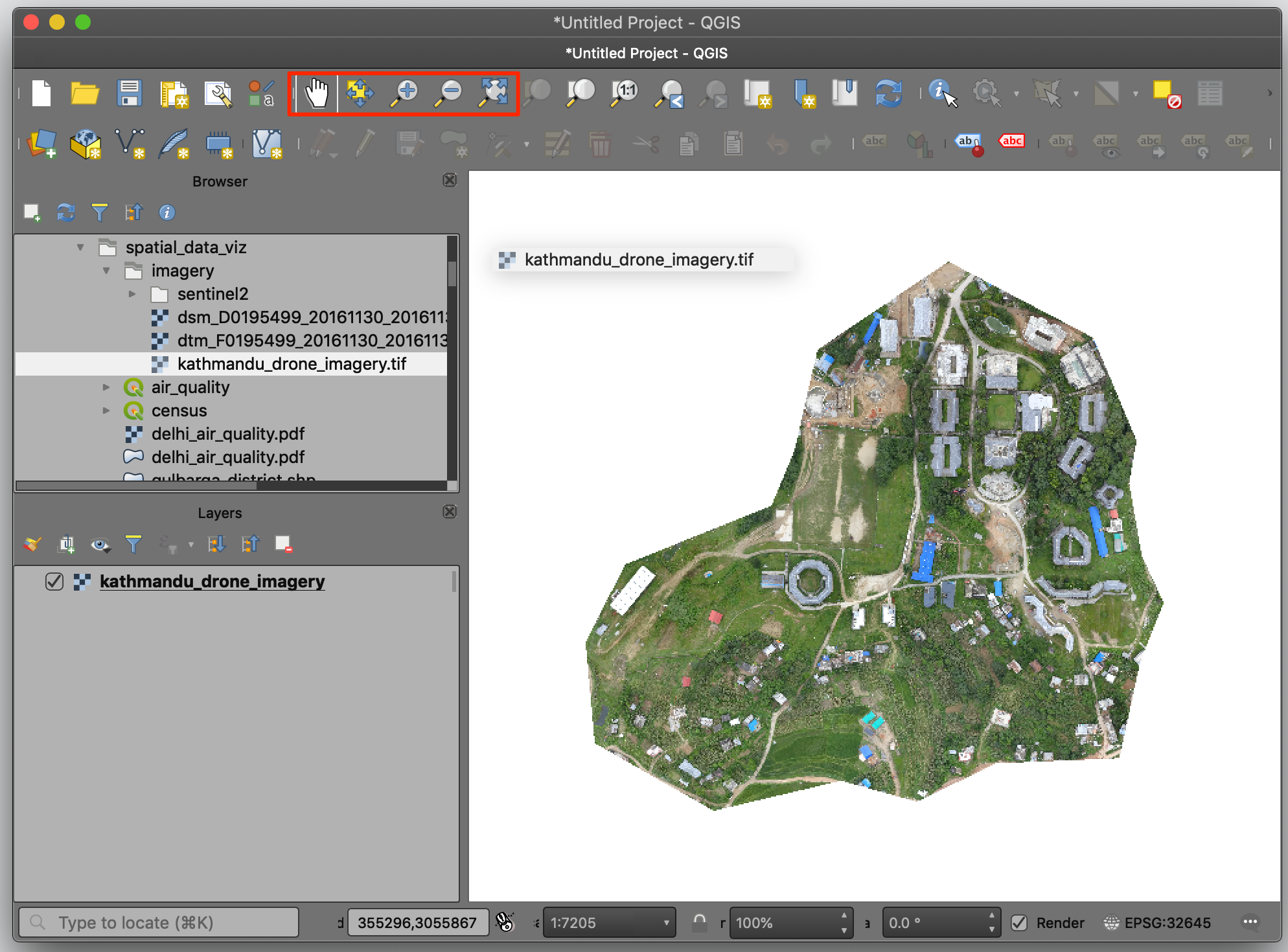
- 在图像右下角,会发现坐标参考系(CRS)是 EPSG:32645,表示的是UTM分区45N。选中Identify 工具然后在图片中四处点击。你会发现这个图像包含红绿蓝三色通道。坐标系是投影坐标(projected coordinates0而非地理坐标(geographic coordinates)。也就是公里网格模式,横轴X (Easting)向东,纵轴Y (Northing)向北。
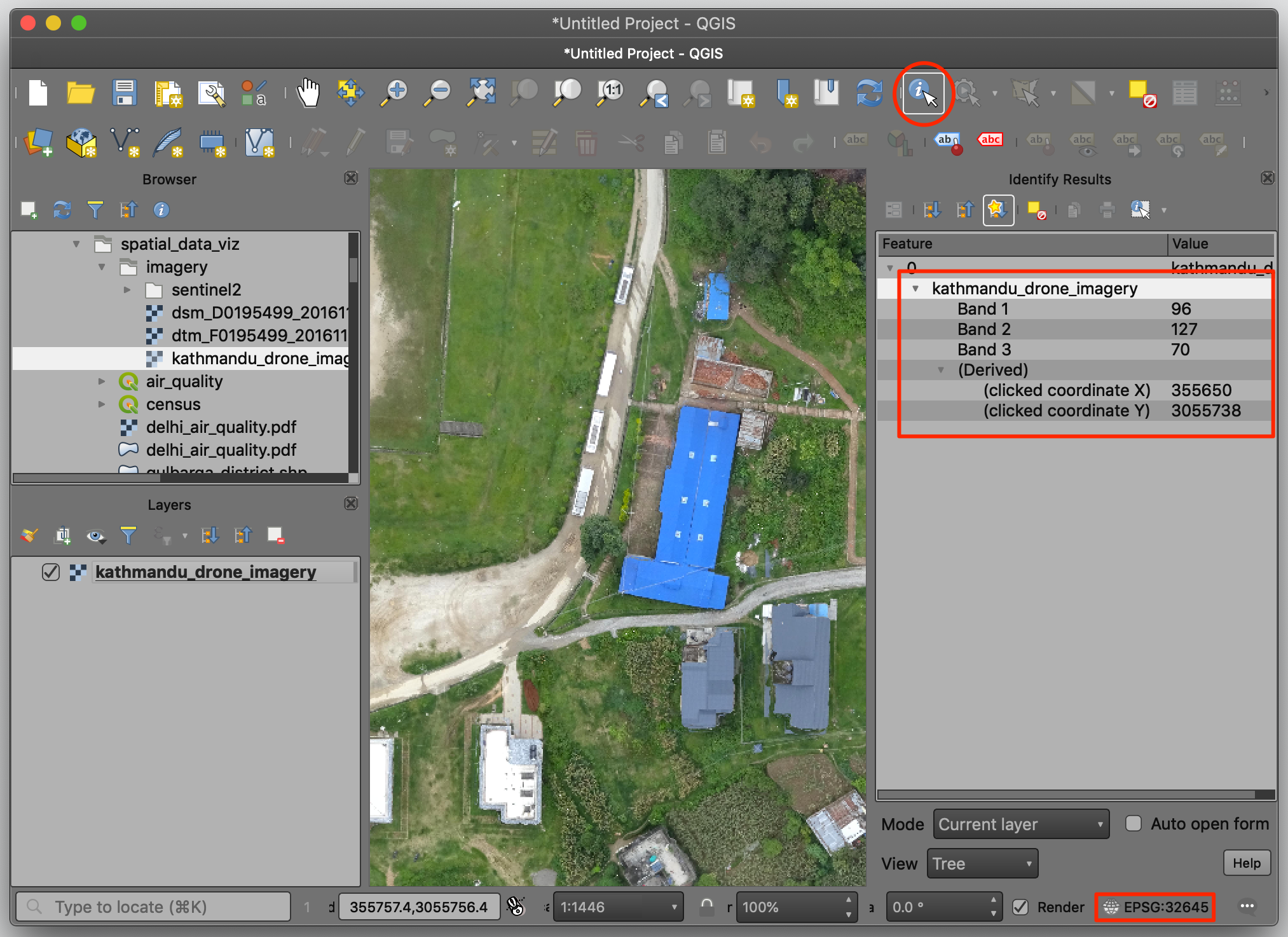
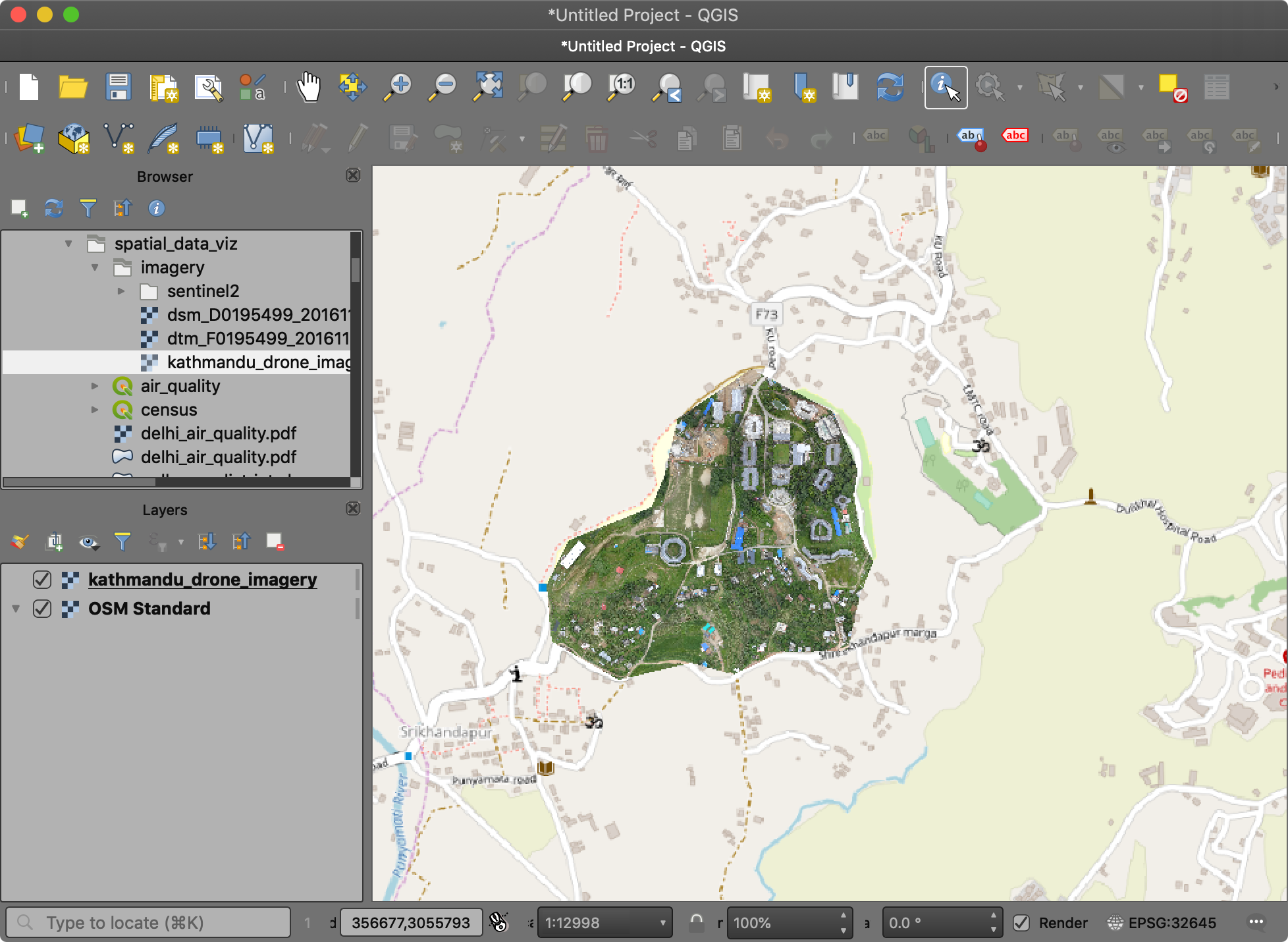
- 这张图经过了地理坐标配准,所以可以配合其他空间图层一起查看。菜单栏中选中 Web → QuickMapServices → OSM → OSM Standard,就将叠瓦地图切片添加到图层面板Layers ,你就能发现这两者之间位置是匹配的,因为原图已经进行过对准。
栅格数据(Raster)-卫星图像(Satellite Images)
地球外面有几百颗观测卫星在持续捕获地球表面的图像。全球很多航空机构都将这些数据公开分享了出来。这些数据集对科学家、研究人员、政府和商业机构等等来说都是无比珍贵的。
和常规照片不同,卫星图像往往包含很多的波段信息,而常规照片往往只有红绿蓝三通道的信息。卫星图像的信息丰富就为利用机器学习模型来辨别不同物体提供了便利。例如,人工草坪和真正的草坪可能看着都是绿色的,但二者对红外光的反射差距非常显著。所以使用多光谱(multi-spectral)图像所提供的附加信息就能轻松分别出来。
练习:观看和使用哨兵2(Sentinel-2)卫星影像并建立拼接
哨兵2 Sentinel-2 是欧洲航天局(European Space Agency, ESA)发射的两颗卫星。所提供图像的像素分辨率是 10米。这个分辨率不如无人机和航拍的图像分辨率,但在城市和地区层次的分析上还是足够好了。更重要的是,这个系列的数据是用12个不同的波段拍摄的,这对于科学目的但应用来说非常重要。对每个地理位置,这套数据每隔5天采集一次,因此可以对全球进行连续观测。而且欧洲航天局将所有相关数据都公开了。
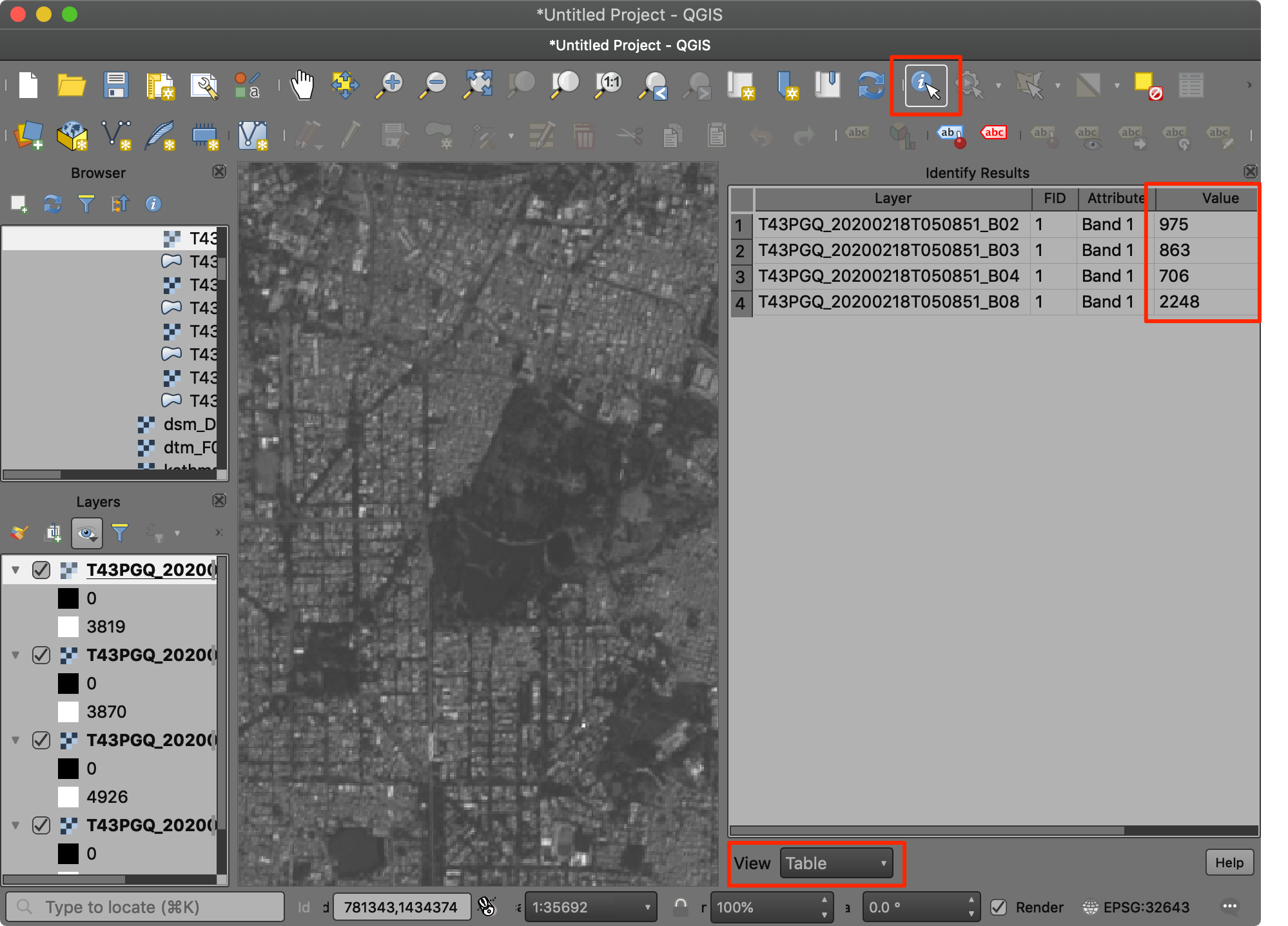
此次练习中加载的是2020年2月18日班加罗尔(Bangalore)的数据。sentinel-2文件夹下面有四个JPEG2000格式的文件,分别是红(B4)、绿(B3)、蓝(B2)和近红外(B8)四个波段。
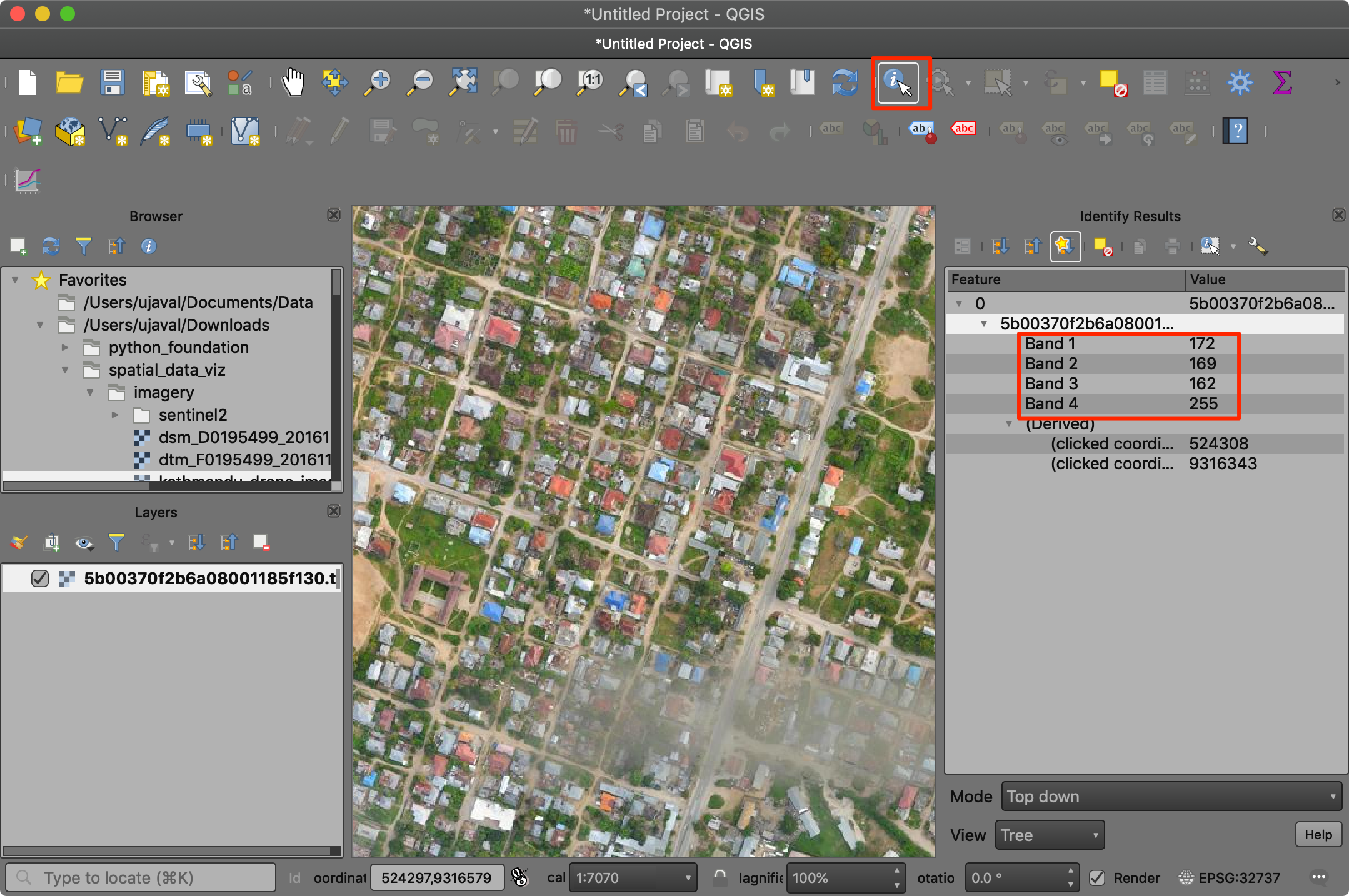
- 将4个图像文件拖拽到QGIS地图画布上。放大到任意区域,在Attributes Toolbar中选择Identify 工具,然后点击图像。在Identify Results 窗口中,设置View为
Table,然后对比同一对象在不同波段下的反射率差别。
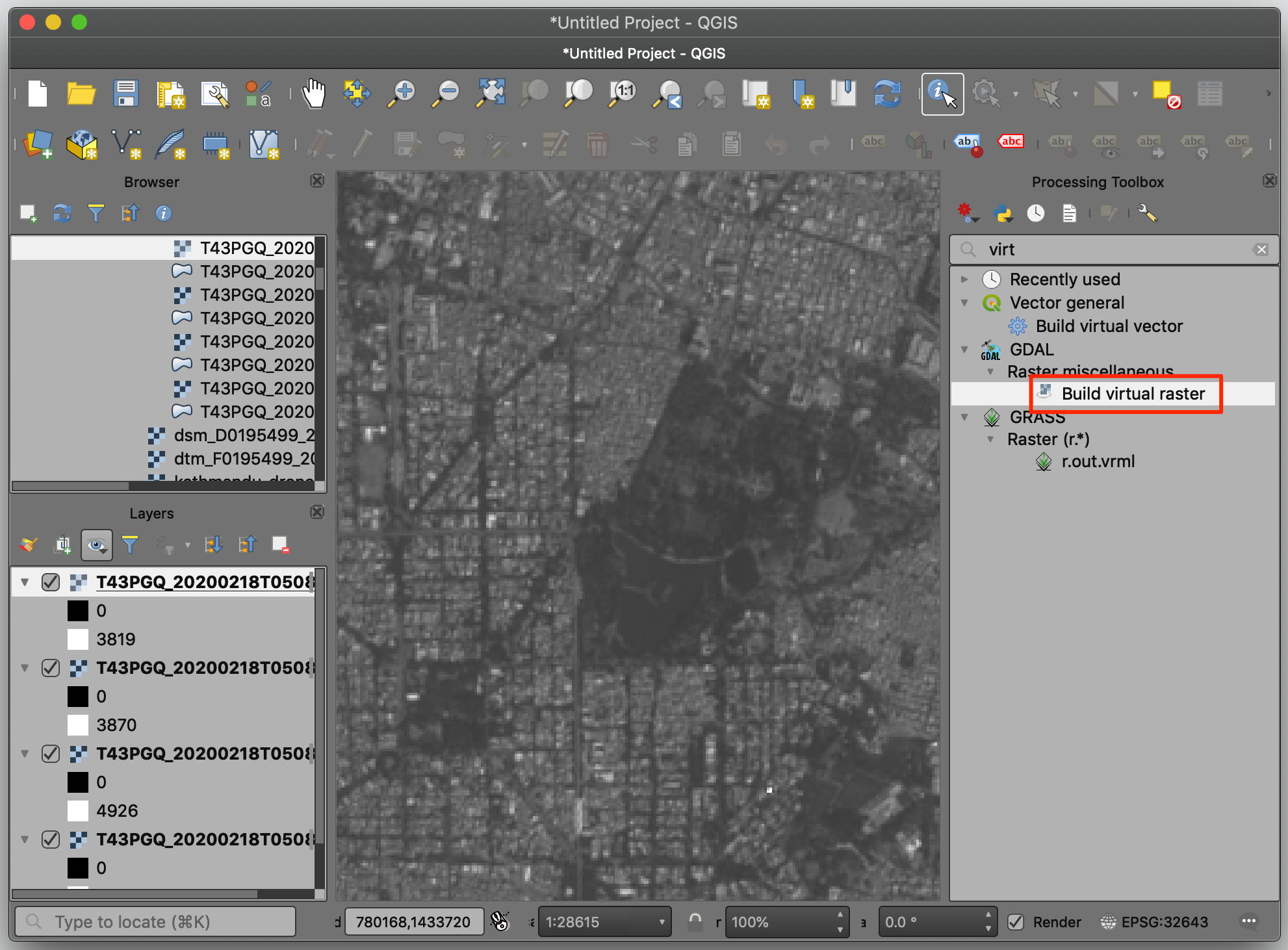
- 接下来可以将多个波段结合起来成为一个图像然后一起来进行可视化。这就叫「彩色合成 Color Composites」。要将多个图像合并到一处,找到Processing → Toolbox然后选中GDAL → Raster miscellaneous → Build virtual raster。双击启动拼接工具。
- 选中全部的4个图层作为输入层Input layers ,然后选中 Place each input file into a separate band(将每个输入文件作为单独波段)。接下来点击运行Run。
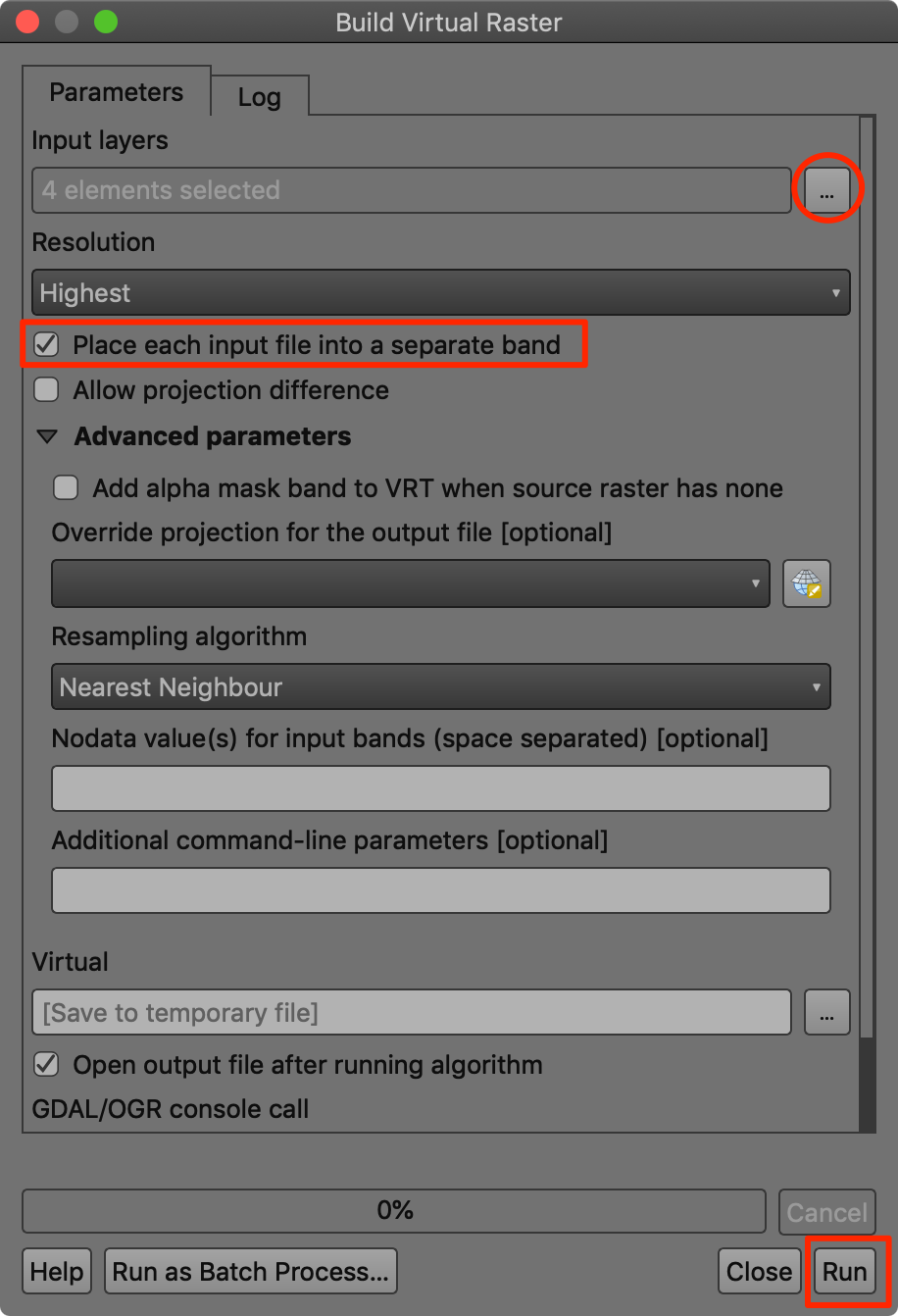
- 这样,在图层Layers中,就出现了拼合出来的新图层
Virtual。这一图层包含有四个不同波段,要注意其中的波段排列顺序是字母顺序的,所以获得的图片当中的四个通道(Band)与原图的对应关系如下所示:
| Virtual Raster Band | Image |
|---|---|
| Band 1 | B02 (Blue) |
| Band 2 | B03 (Green) |
| Band 3 | B04 (Red) |
| Band 4 | B08 (NIR) |
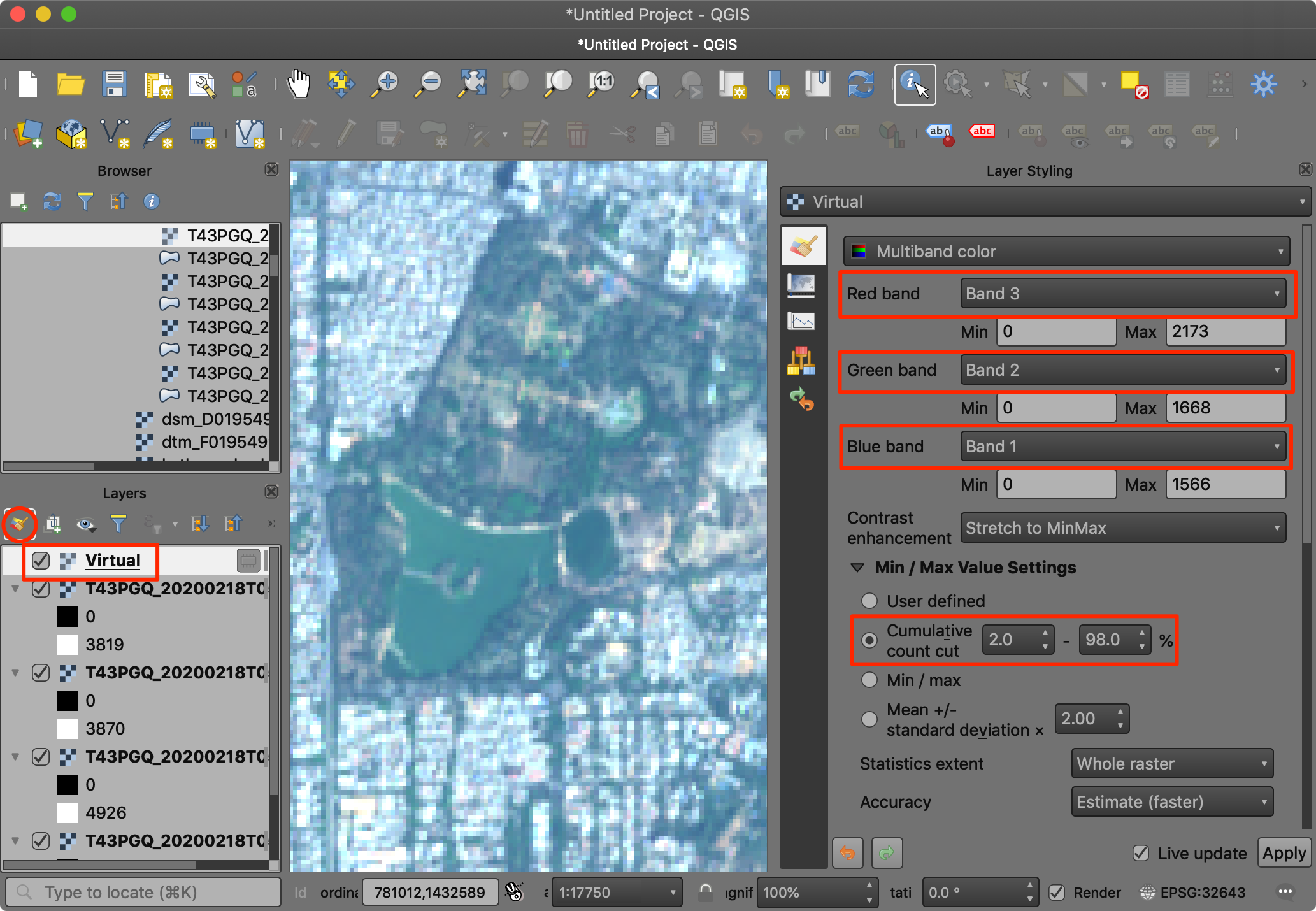
首先我们进行「真彩色合成RGB Color Composite」。这也常被称作「自然彩色合成Natural Color Composite」,因为这种图像和人在肉眼观看的效果是一样的。设置Band 3、 Band 2 、 Band 1 作为对应的 Red、Green 、Blue 三个通道。然后将Min/Max Value Settings设置为Cumulative count cut。然后就会发现画布上的图像呈现出自然的色彩。
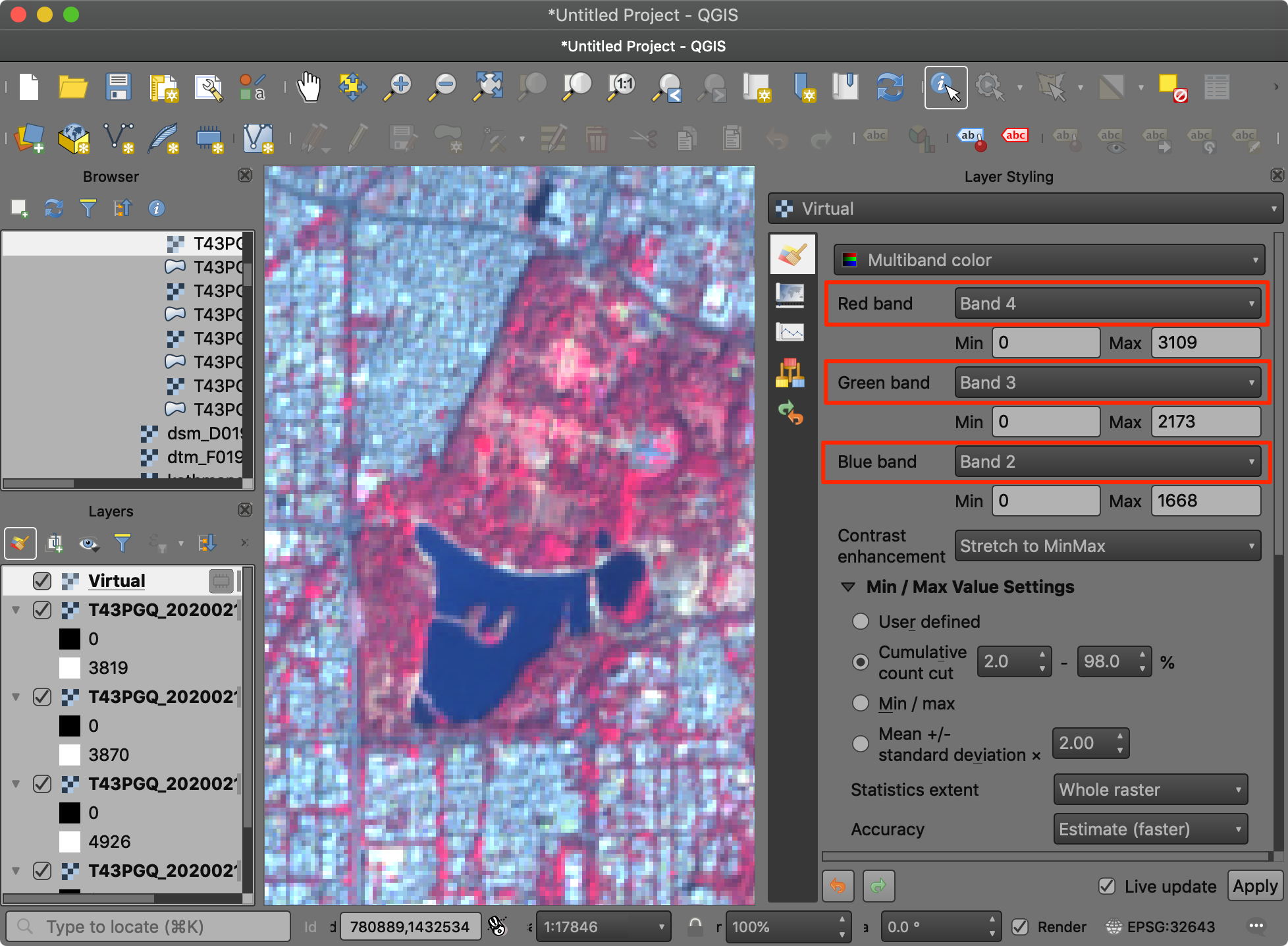
- 接下来要试试的是另一种可视化方案,也就是「假彩色合成False Color Composite」。这里我们创建一个近红外、红、绿的假彩色合成(NRG Color Composite )。也就是将近红外波段设置为R通道,红光波段设置为G通道,绿光波段设置为B通道。这种合成方式强调了红光下的植被,能够更容易地进行植被解译。注意,水体和植被在自然彩色合成下几乎是一样的颜色,而在NRG假彩色合成下就很好区分了。
点云(Point Clouds)
现代的地图绘制技术包括使用激光雷达传感器(LiDAR sensor)的各种航拍手段。LiDAR是“Light Detection and Ranging”的缩写。这种传感器使用激光脉冲来测量物体距离地面的距离。对每个发出的脉冲,系统都计算对象的X、Y、Z坐标。这个数据对空间数据来说并不新奇,但在一块小区域内使用这样的方法可以获得上百万的点,常规的观看和处理工具就不适用了。这样的点云(Point Cloud)一般使用的是LAS或者LAZ的文件格式进行存储的。

Credit: Cargyrak, Wikipedia
练习:观看航拍的点云
英国环境食品与农村事务部(UK’s Department of Environment Food & Rural Affairs (DEFRA) )提供了全国范围的LiDAR数据和产品,可以从Defra 数据服务平台 来获得。本次练习使用LAZ格式的牛津大学点云数据集。
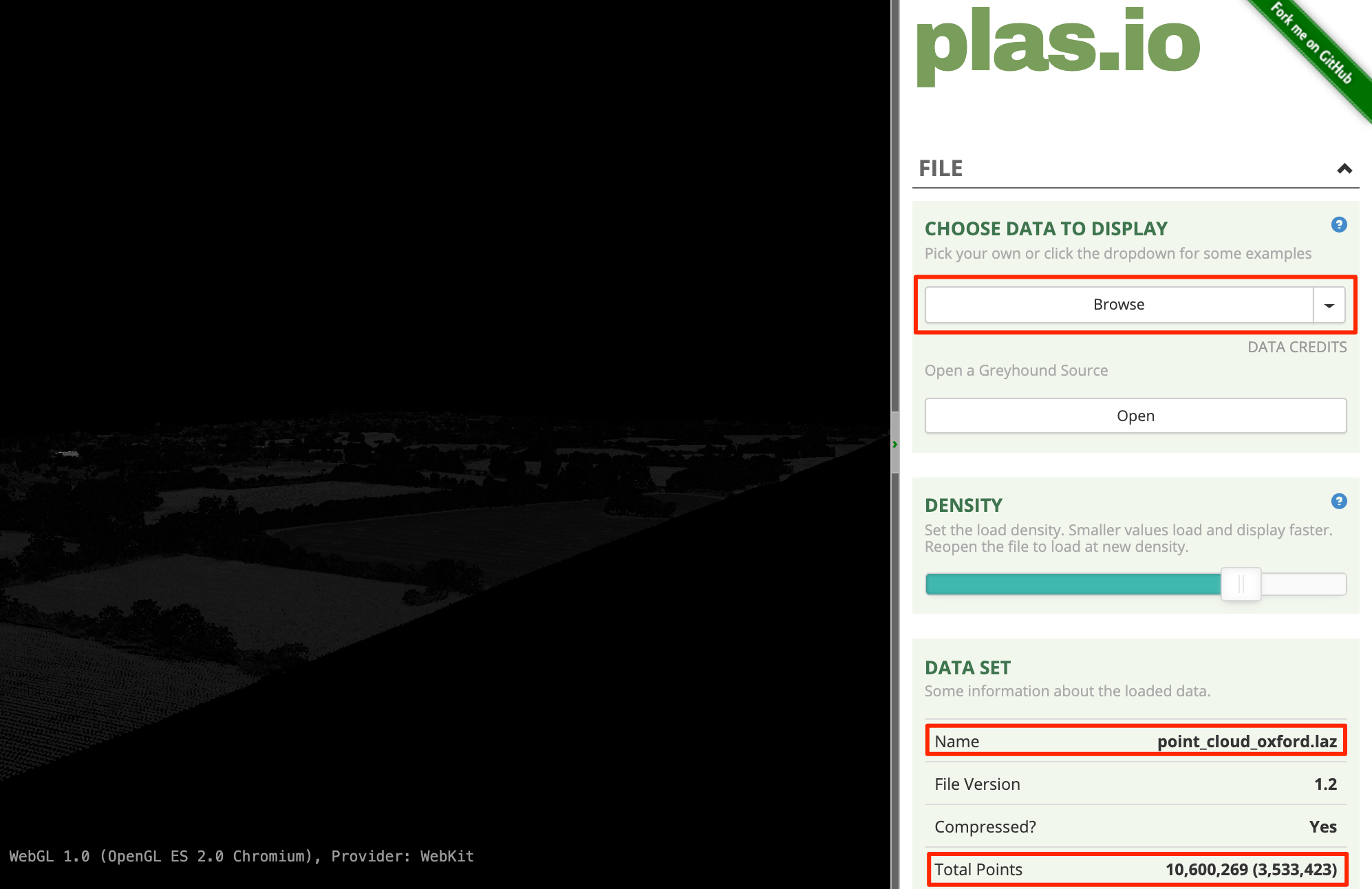
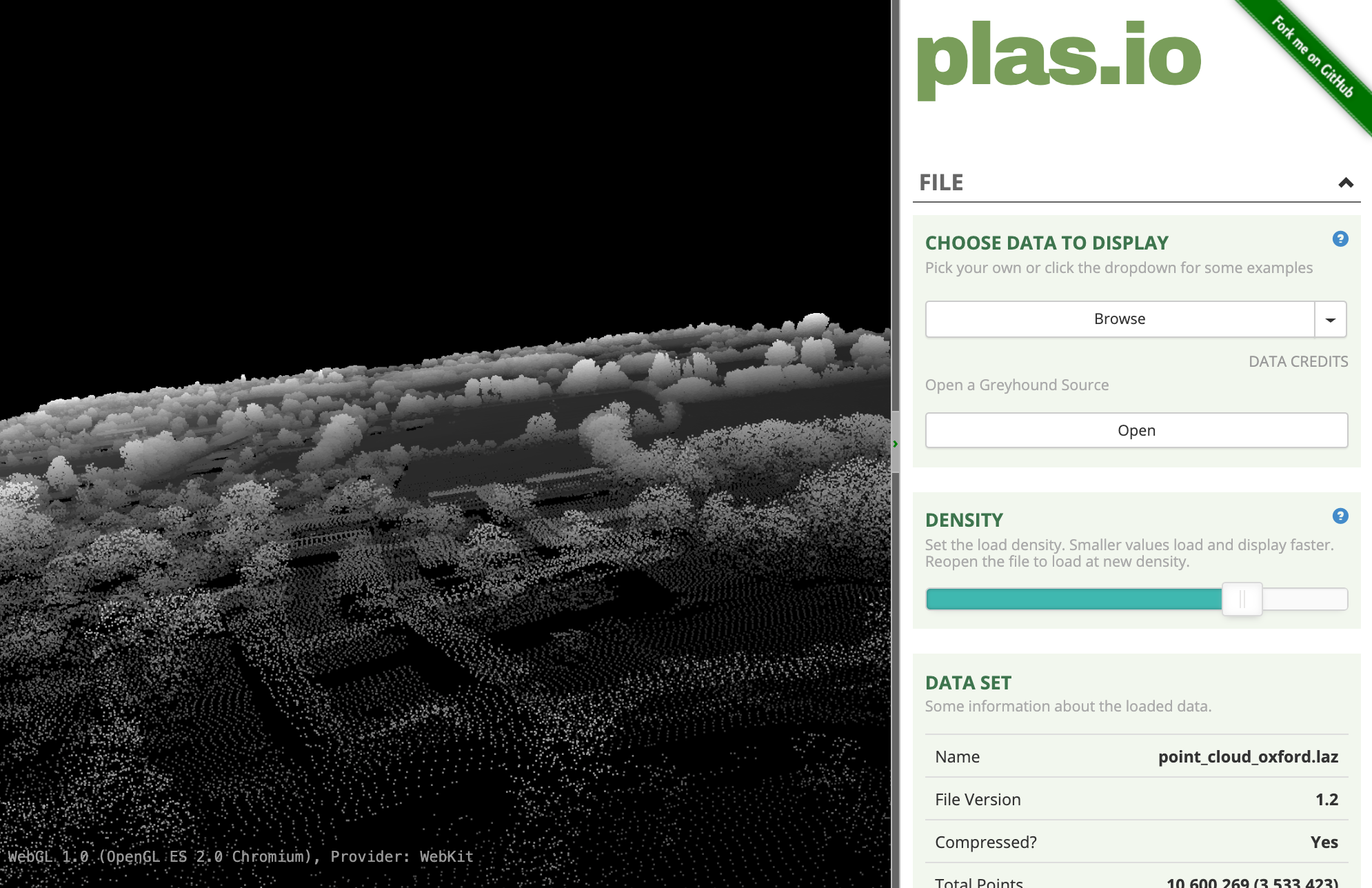
- Plasio 是一个基于浏览器的 LAS/LAZ 格式点云查看器,访问plas.io,点击Browse 然后定位到
SP5008_P_10967_20161130_20161130.laz文件,点击Open打开。要注意这么小的区域有超过三百五十万个数据点。
- 数据加载后,在右边的面板中滚动,找到Intensity Source 部分,下拉选项,选中
Heightmap Grayscale。
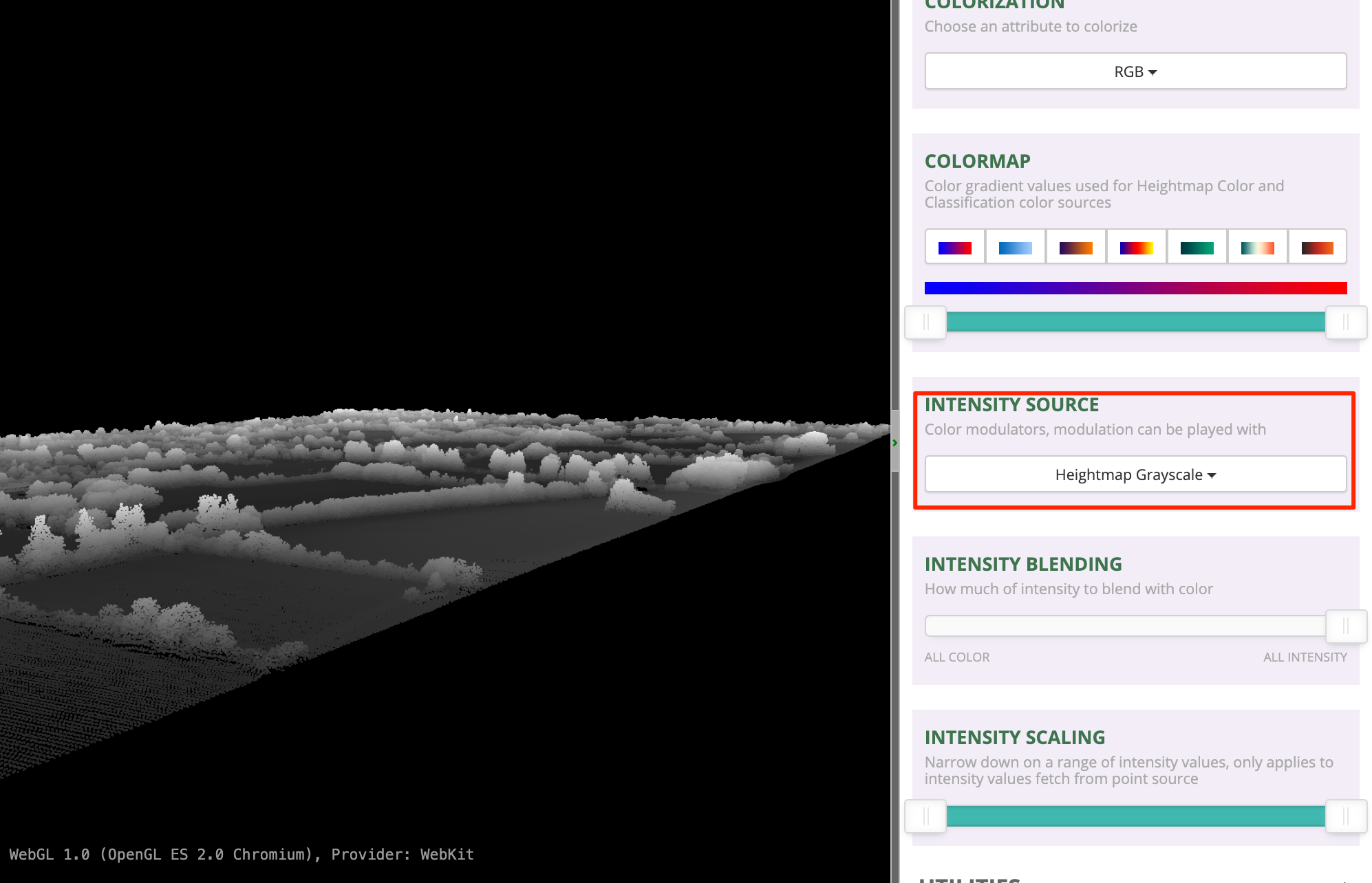
- 使用鼠标左键和滚轮来缩放与平移视图,探索一下数据集吧。
栅格数据(Raster) - 高程数据(Elevation Data)
栅格数据很适合对连续对象进行建模,比如高程。栅格中的每个像素的值就是该点的高程。这是一种对地标建模的简单高效的方法。这种栅格数据也就是数字高程模型(Digital Elevation Model,DEM)。
具体来说,数字高程模型还可以分为两个基本类别:
- 数字地表模型(Digital Surface Model,DSM):表示地球真实表面,包括植被覆盖和建筑物等等。
- 数字地形模型(Digital Terrain Model,DTM):表示裸地表和自然地形。DTM一般是基于DSM实用算法或人工处理而得到。
练习:查看和对比 DSM 与 DTM
英国环境食品与农村事务部(UK’s Department of Environment Food & Rural Affairs (DEFRA) )提供了全国范围的高程数据产品,可以从Defra 数据服务平台 来获得。本次练习使用ASC格式的牛津大学高程数据:dsm_F0195499_20161130_20161130_mm_units.asc 和dtm_F0195499_20161130_20161130_mm_units.asc。
.asc文件是一种基于文本的 ASCII 编码的栅格文件格式。这种文件的数据格式很简单,头部介绍栅格信息,像素值就是对应的行列值。如果你使用文字编辑器打开,可能就像下面的样子。
cols 2000
nrows 2000
xllcorner 450000
yllcorner 208000
cellsize 1
NODATA_value -9999
-9999 -9999 -9999 -9999 -9999 -9999 ...
...
...
头文件提供的信息中包含有左下角(11)的X、Y坐标。知道这个位置的坐标对,以及图像尺寸和坐标参考系(Coordinate Reference System,CRS),可以对整个图像进行地理配准了。关于坐标参考系的相关信息包含在元数据metadata ,设置为EPSG:27700 British National Grid。接下来就有足够的信息来查看这些栅格数据了。
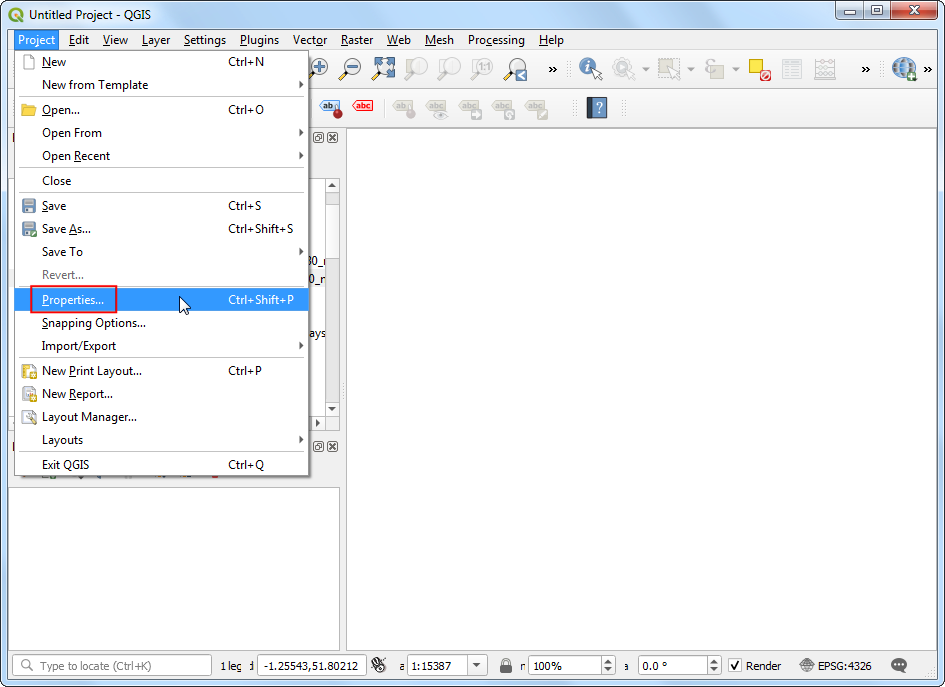
- 打开 QGIS,在加载数据之前,我们要先设置项目坐标参考系与栅格数据的坐标参考系一致。在菜单栏中找到Project → Properties进行设置。
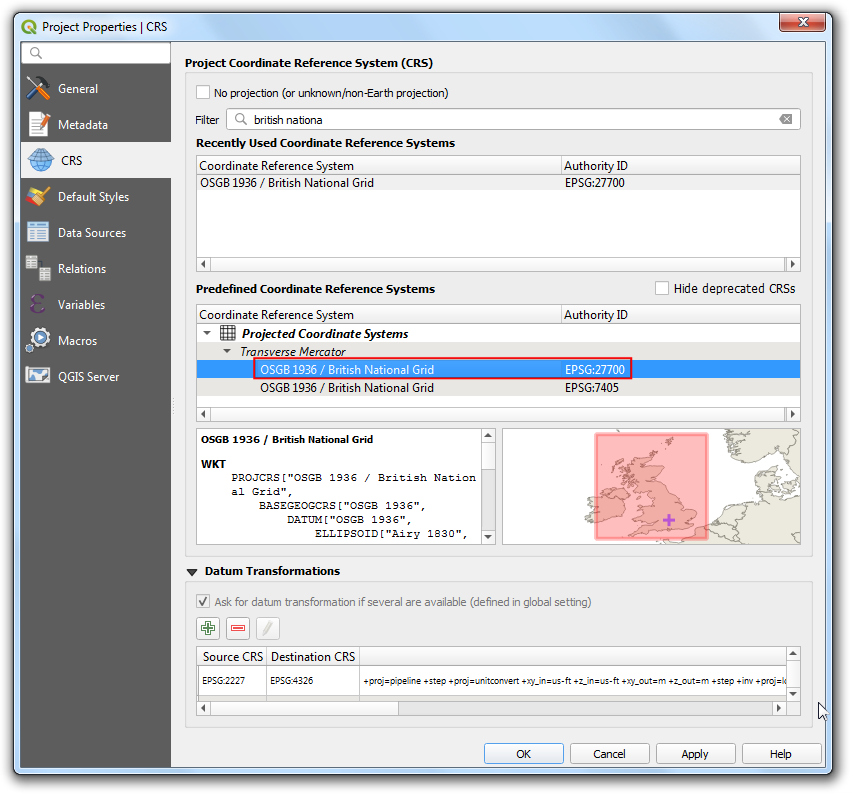
- 切换到CRS 标签页,然后搜索
EPSG:27700,选中后点击OK。
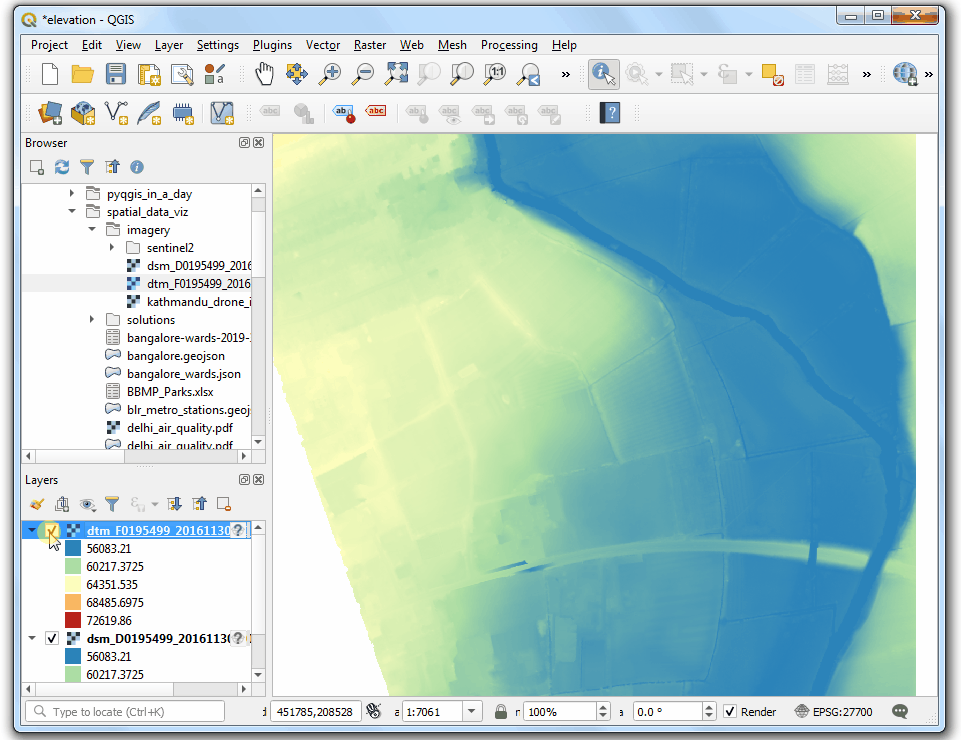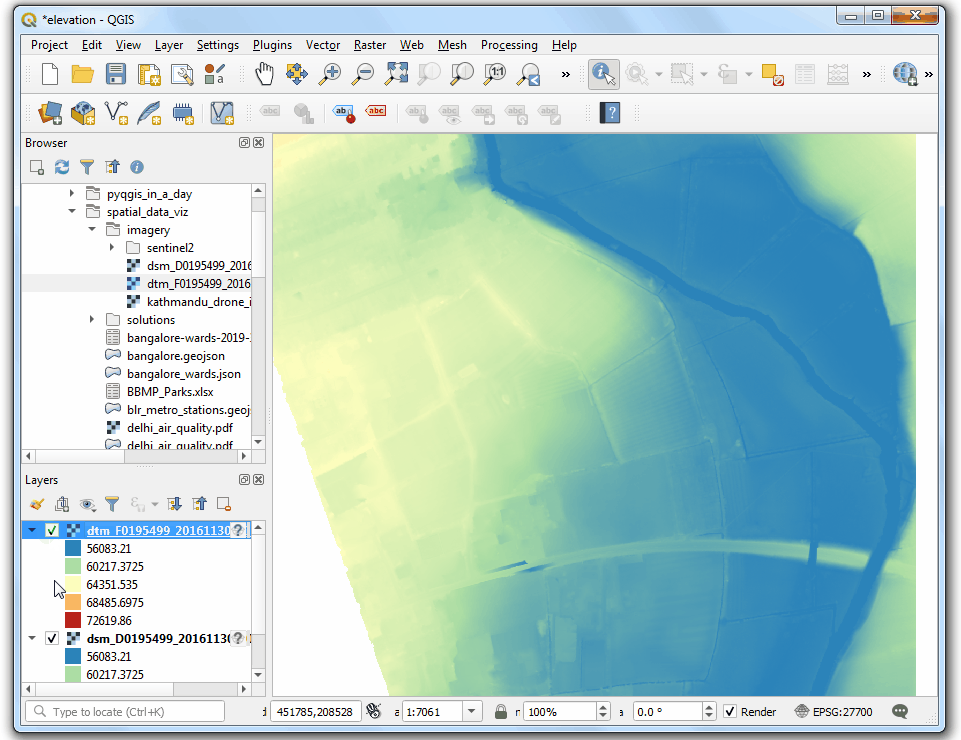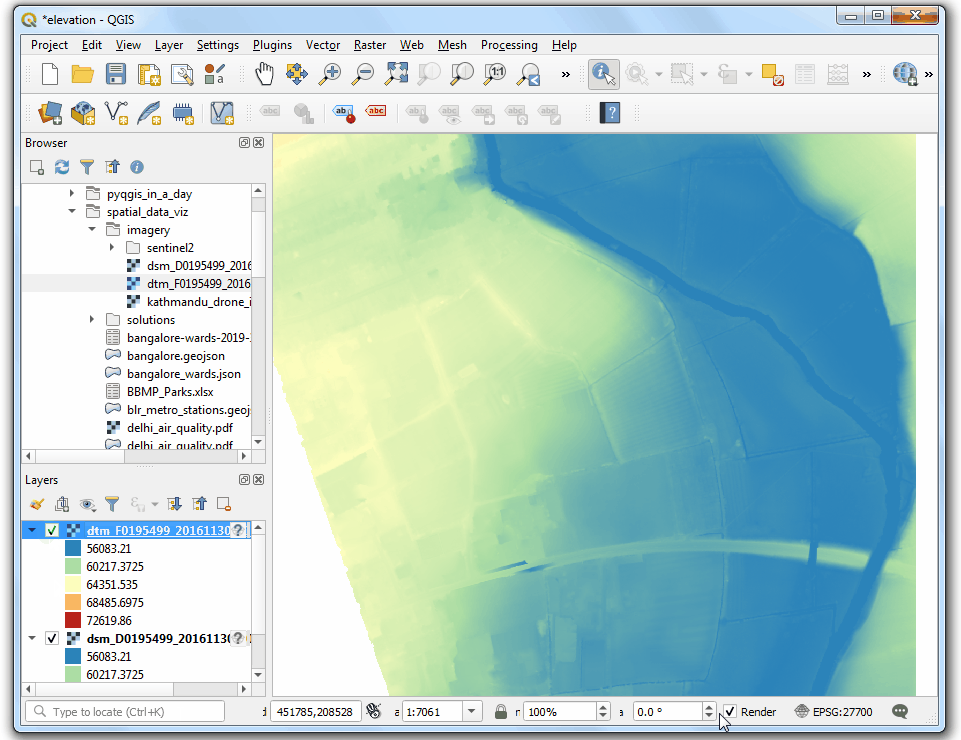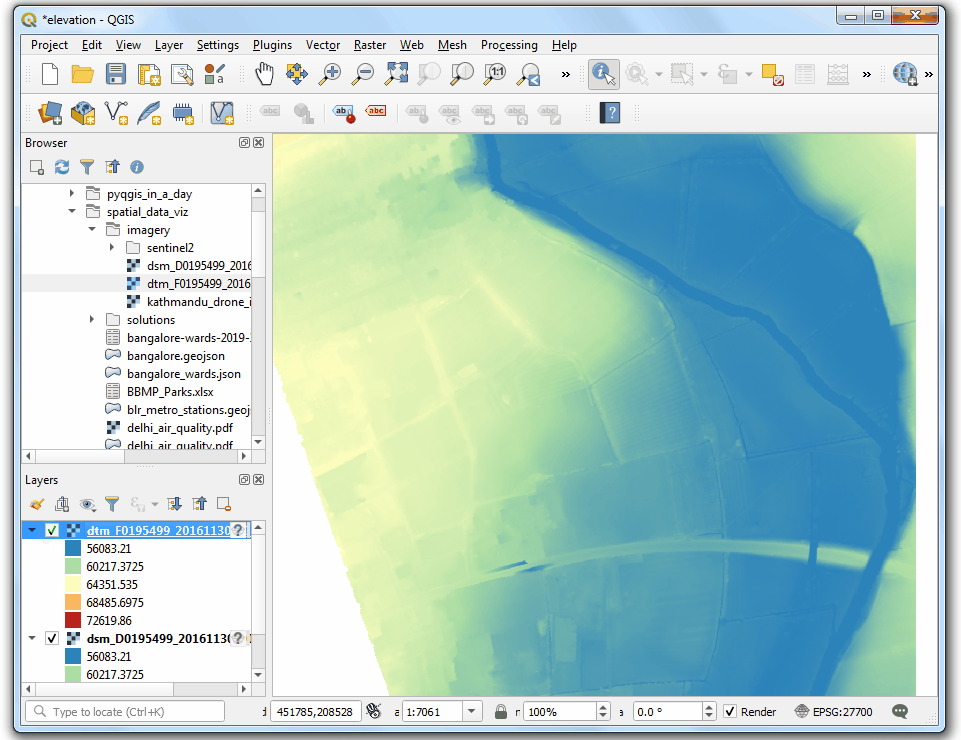
- 将
dsm_F0195499_20161130_20161130_mm_units.asc文件拖动到试图中。选中Identify 然后在图像上点击任意位置。就会看到对应的Band 1 就是对应像素位置的高程,单位是千米.
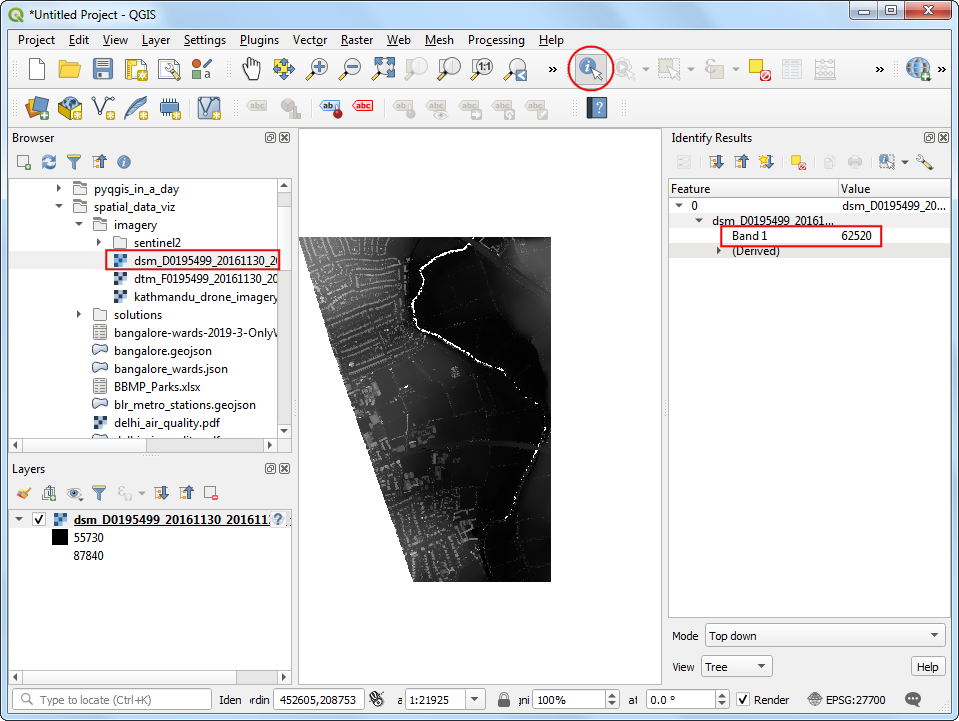
- 点击 Open the Layer Styling Panel,选中单波段假彩色
Singleband pseudocolor着色器。扩展到最小最大值设置Min / Max Value Settings部分,选择 Cumulative count cut。 Select a color ramp of your choice. Once the style is applied you will be able to see the building outlines, trees, riverbed etc clearly.
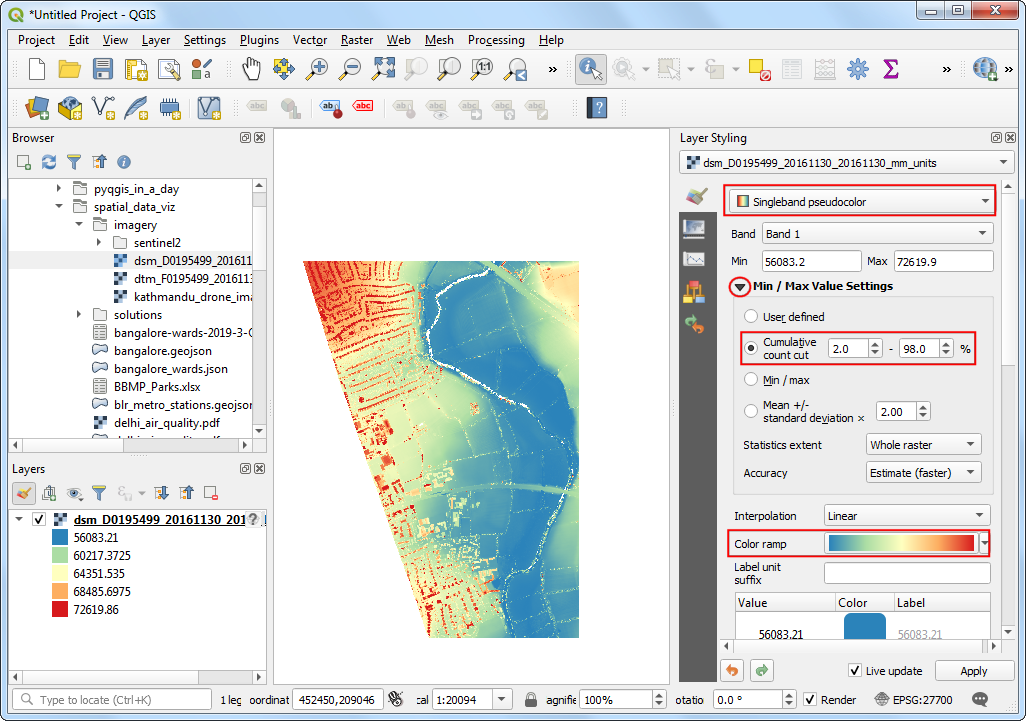
- 接下来将
dtm_F0195499_20161130_20161130_mm_units.asc也拖到视图里。要对这两者进行对比,可以考虑使用同样的参数进行可视化。好在QGIS提供了一种简单办法复用图层设置,右键要复制设置的源图层dsm_F0195499_20161130_20161130_mm_units后选中 Styles → Copy Style即可复制已经做好的图层设置。
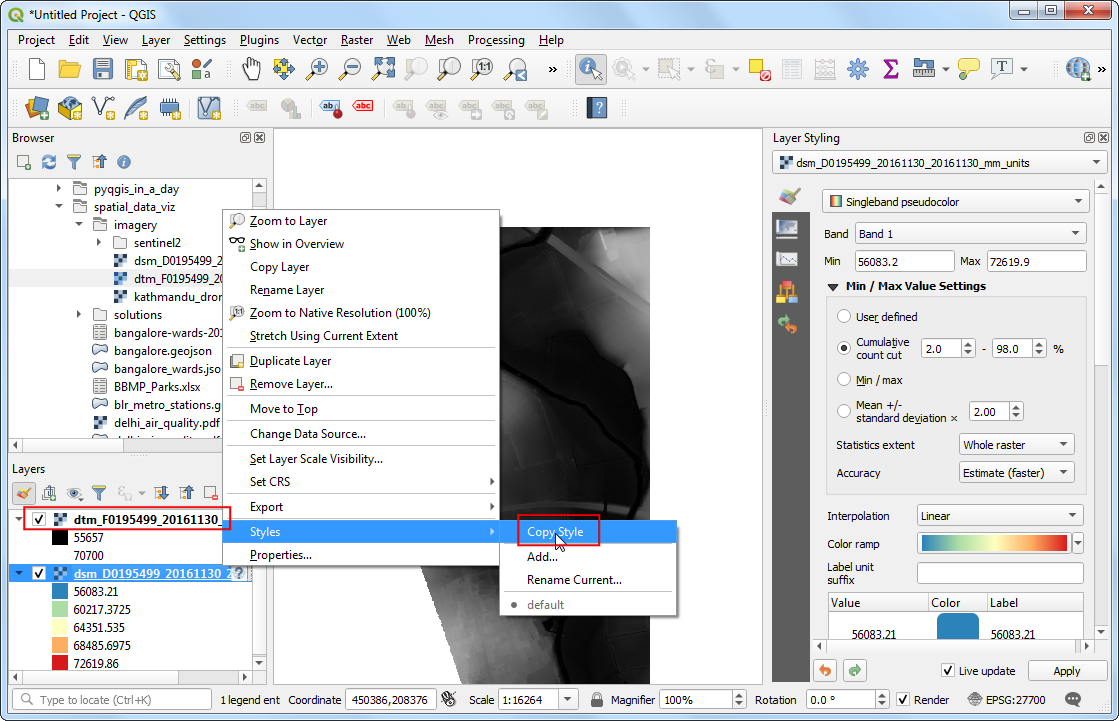
- 然后选中目标图层
dtm_F0195499_20161130_20161130_mm_units,右键,然后Styles → Paste Style,就可以把刚刚复制的图层粘贴上去了。
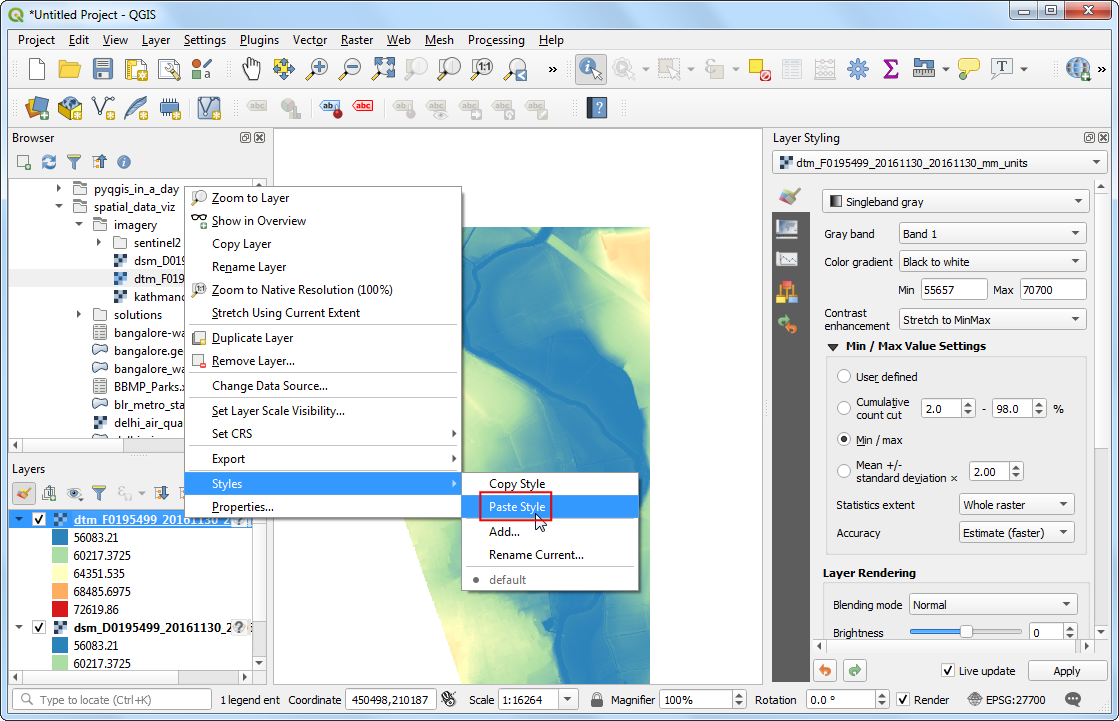
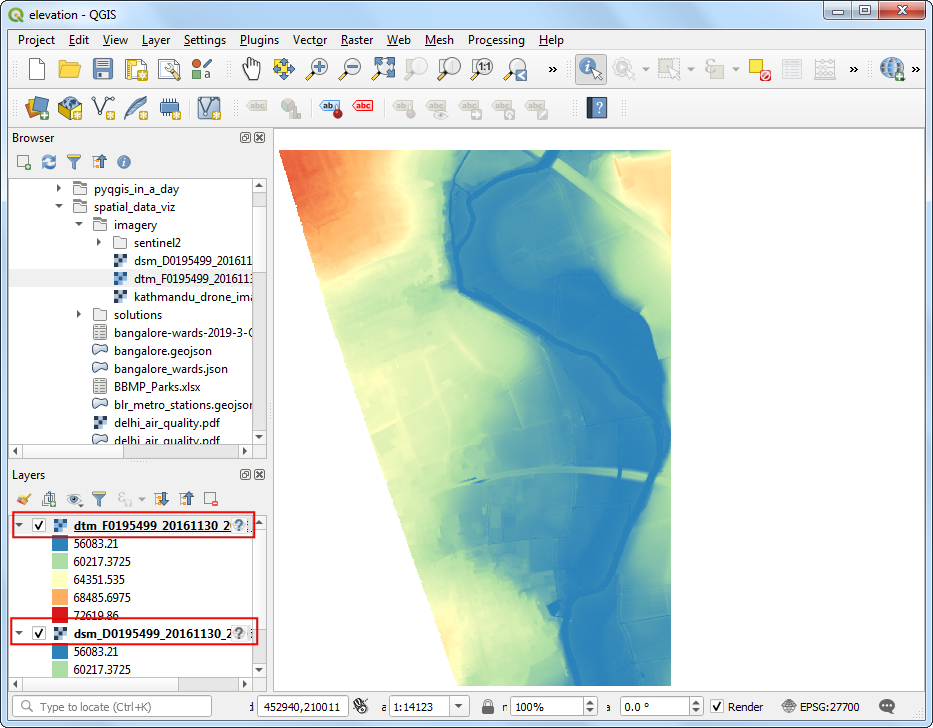
- 来回切换 DSM 和 DTM 的图层顺序就可以对比二者来。你会发现 DTM只包含了地表的高程,没有任何其他的自然或者人造物。View Animated GIF ↗
{kind=link}
分析
练习:Uber交通分析
Uber提供了超过一百亿次打车出行的匿名数据,旨在帮助全球的城市规划。这些数据都已经免费公开课下载。该数据集中包含了旅行时间和每段路上的速度等信息。
本次练习使用的是班加罗尔(Bangalore)的 旅行时间数据 Travel Times data来分析交通模式,发现30分钟车程可达地区。这种地图也叫做等时线地图 Isochrone Map ,可以用于城市规划。
这份数据有两部分,首先是一个GeoJSON文件bangalore_wards.json描绘了城市内各区域的边界,另外有一个CSV文件bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate.csv包含了城市各区域和一天中各时段的旅行时间,日期是2019年的第三季度(789三个月)。一份白皮书讲述了创建这些数据的方法。
CSV格式文件的内容如下所示:
| sourceid | dstid | hod | mean_travel_time | … |
|---|---|---|---|---|
| 55 | 111 | 8 | 2026.76 | … |
| 22 | 25 | 13 | 770.07 | … |
| … | ||||
| … |
- sourceid 和 dstid 指的是出发地和目的地的区块ID。
- hod: hour-of-day,一天中的时间,从0-23。
- mean_travel_time: 平均旅行时间,秒为单位,从所有旅行中提取。
班加罗尔城区中有 198 个分区。CSV文件中包含任意两区之间的成对的旅行时间。总共的记录时间会有198 x 198 x 24 = 940896条。但由于在特定时间内不是所有的区都有充足的行程发生,就存在对应的空白。因此实际上这个数据是818263列。这数据规模还是挺大的,需要用一些分析方法来提取其中的正确数据集。
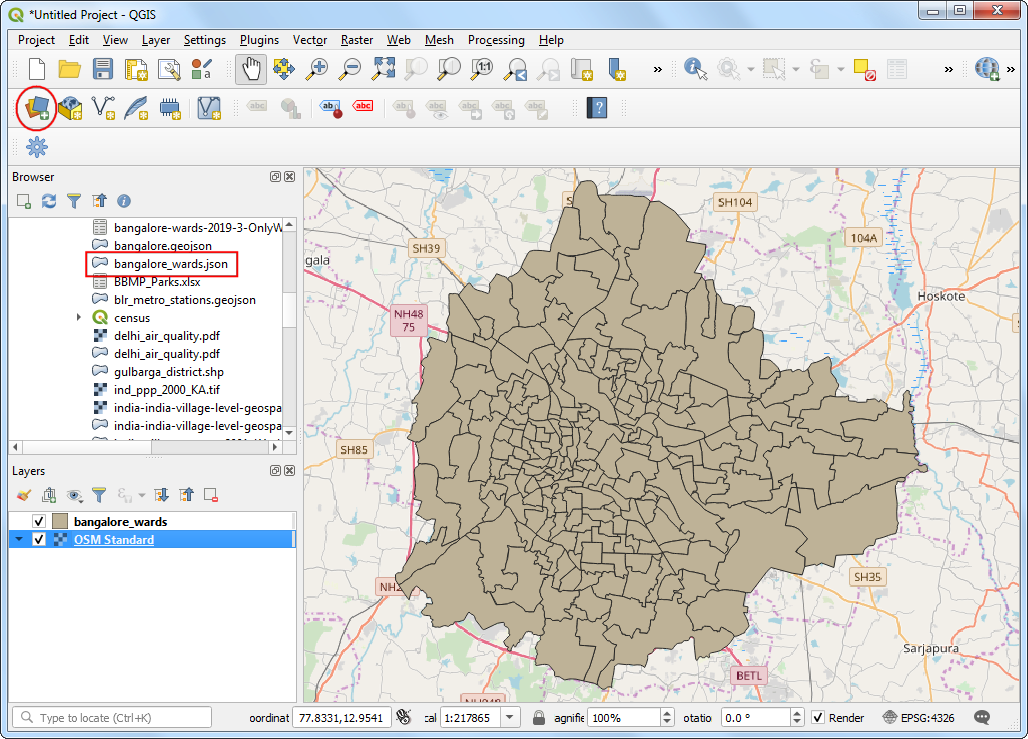
- 选中
bangalore_wards.json拖拽到QGIS的地图画布。然后夹在一个街景地图作为地图层,在菜单栏找到Web → QuickMapServices → OSM → OSM Standard,加载之后,点击 Open Data Source Manager 按钮。
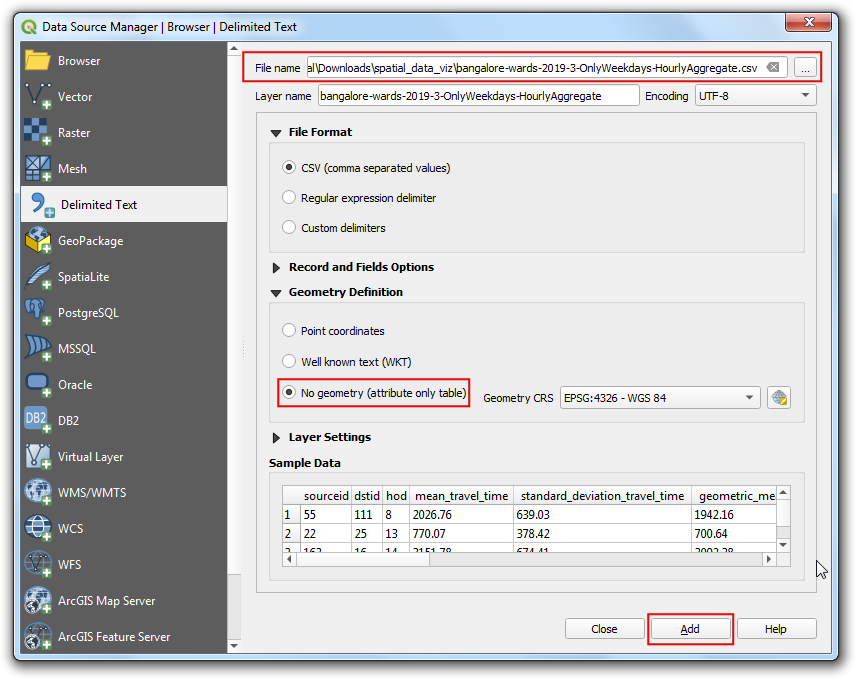
- 切换到Delimited Text 按钮,找到
bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate.csv文件并选中。由于CSV文件只是表格数据,选择No geometry (attribute only table) 选项然后点击添加Add。
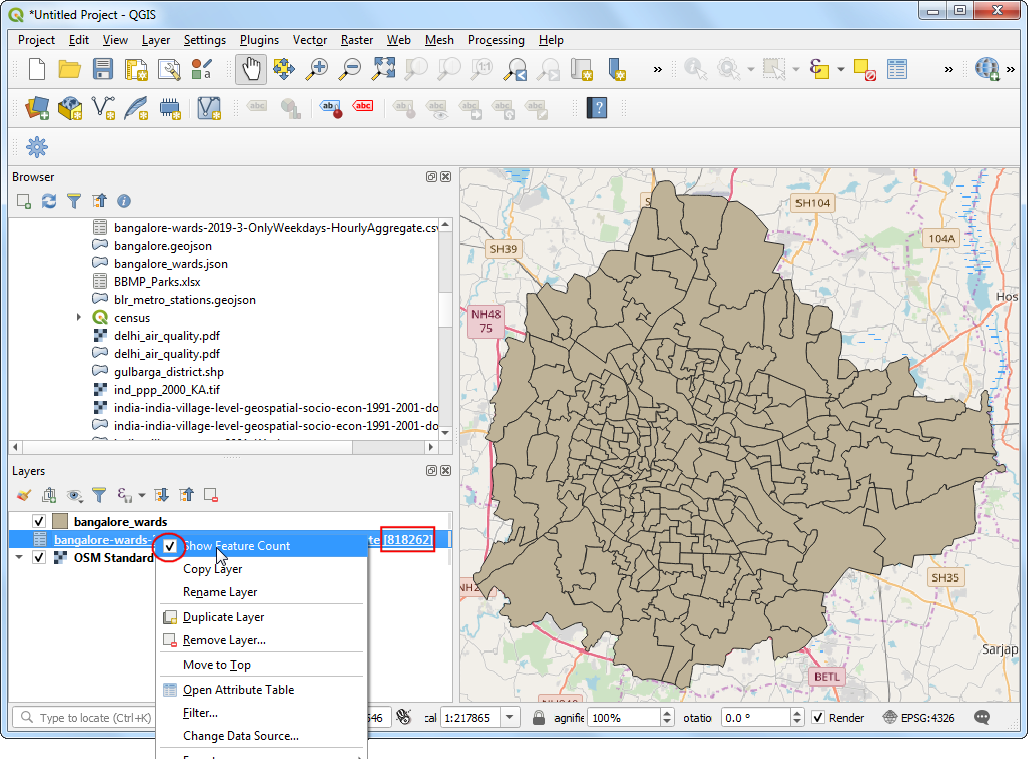
- CSV倒入后,图层界面Layers 下面就有了
bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate这一项,右键然后选中Show Feature Count。全部的列数就出现在旁边了。
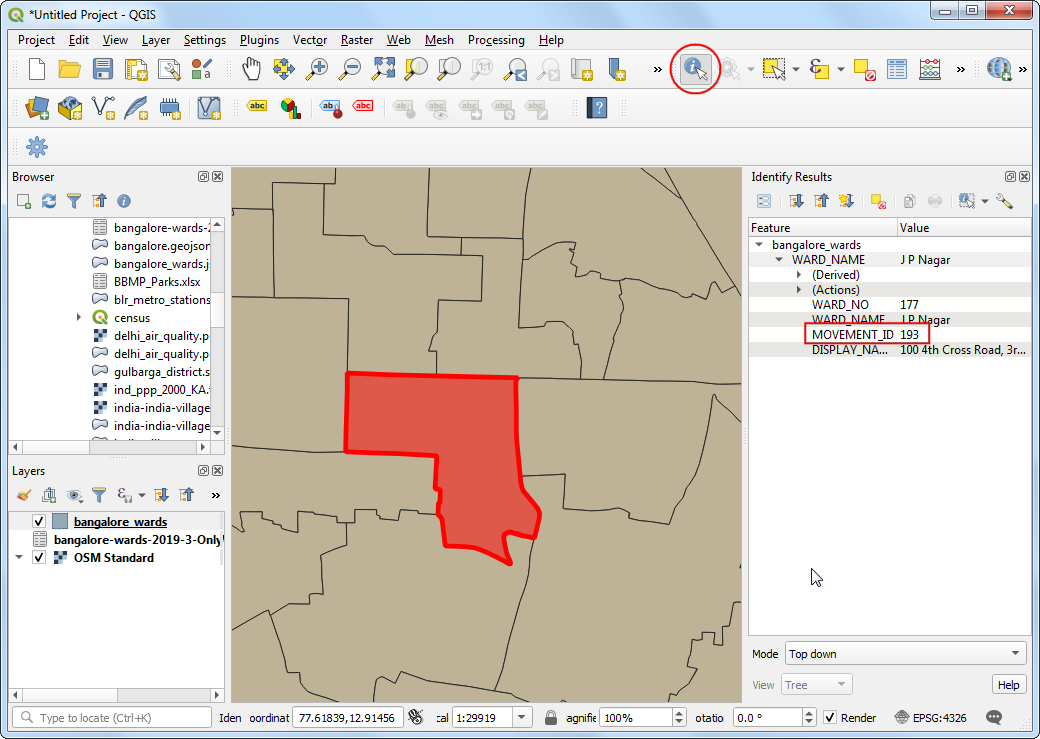
- 对于本次练习,要计算全部从Spatial Thoughts office出发30分钟内车程能到达的位置。在地图上找到对应区域,可以选中Identify 按钮来选择
bangalore_wards图层并点击,然后该地的位置结果就会出现,位于JP Nagar 区,MOVEMENT_ID 为193。
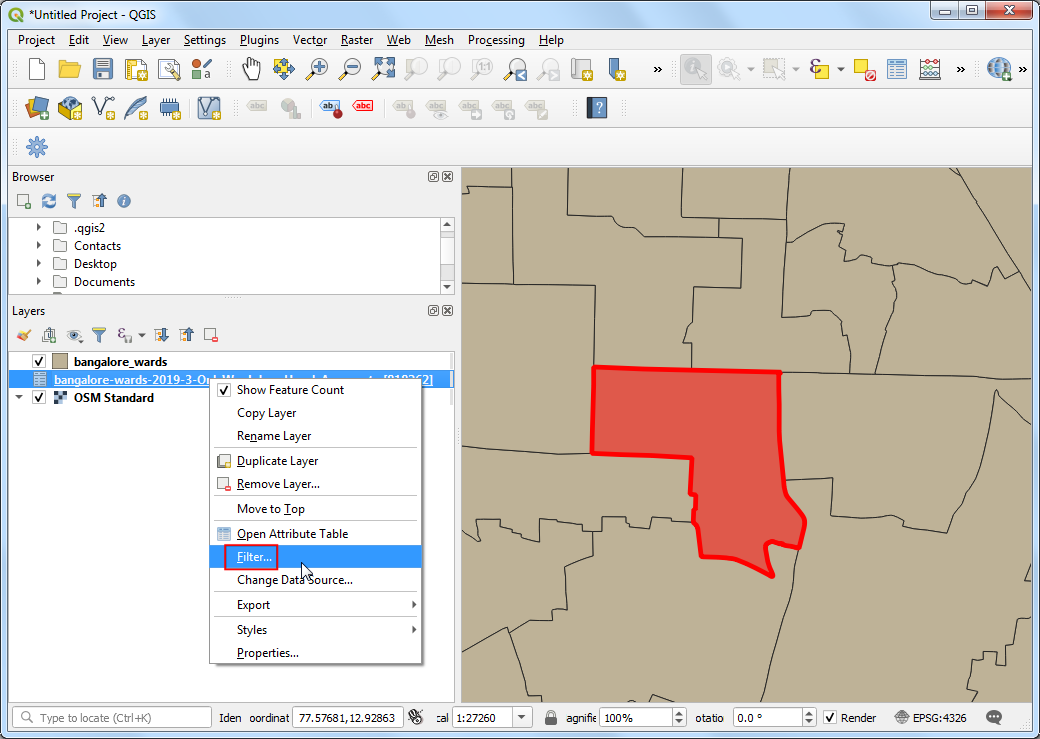
- 接下来可以筛选将这个区域作为目的地的行程记录。还可以限制分析范围在早高峰上午9-10点钟这个时间段内。右键
bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate层然后选中筛选Filter。
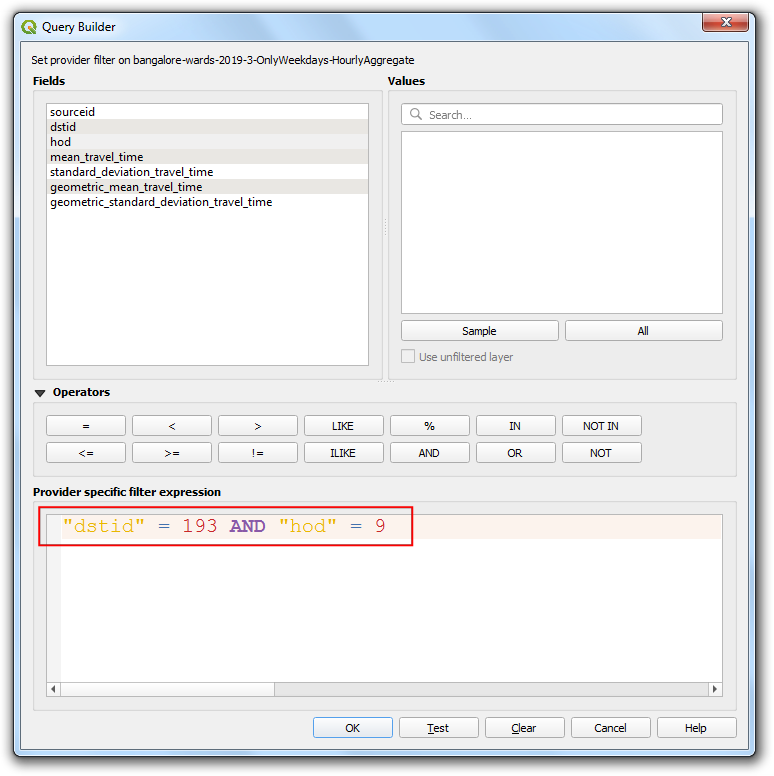
- 输入下面的筛选表达式,然后点击 OK。
"dstid" = 193 AND "hod" = 9
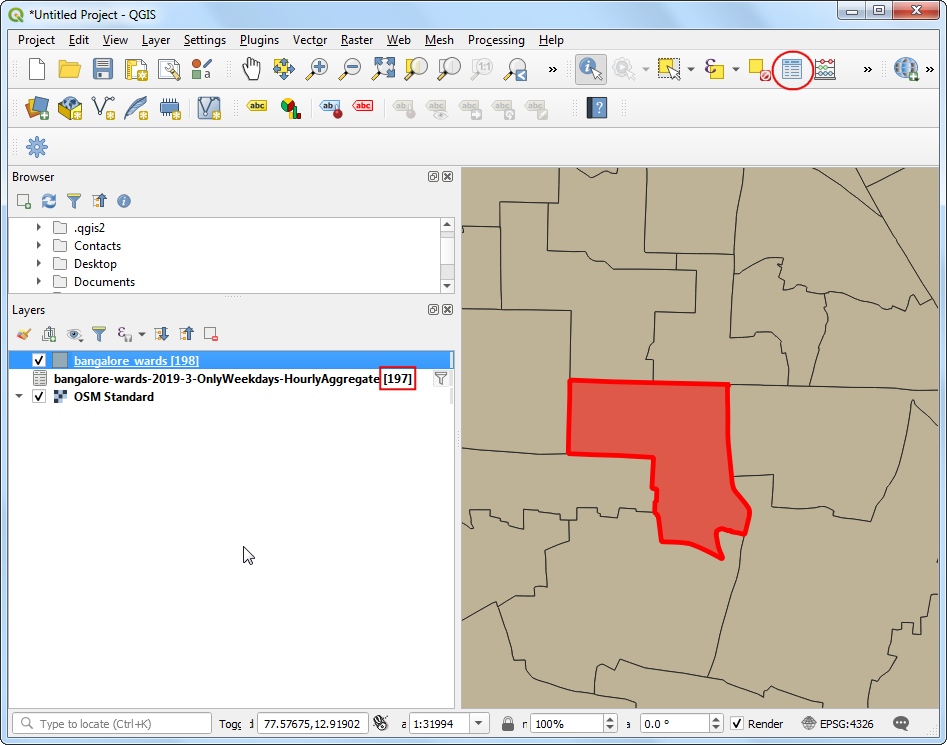
- 现在返回到QGIS的主窗口,你会发现数据项目数已经缩减到了197。这是因为城市中一共只有198个区,那以
193号位置为目的地的自然只有其他197个,也就是1个目的地,197个出发地。现在到Attributes工具栏中使用Open Attribute Table 打开各图层的属性表格。
- 现在我们在图层
bangalore_wards中有各区范围,在层bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate中有表格信息。现在就可以使用一个公用属性(common attribute)来将属性信息连接起来。此处的 MOVEMENT_ID 列来自bangalore_wards图层,而 sourceid 列来自bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate,这两个都是分区id,可以连接起来。这个操作就叫Table Join。
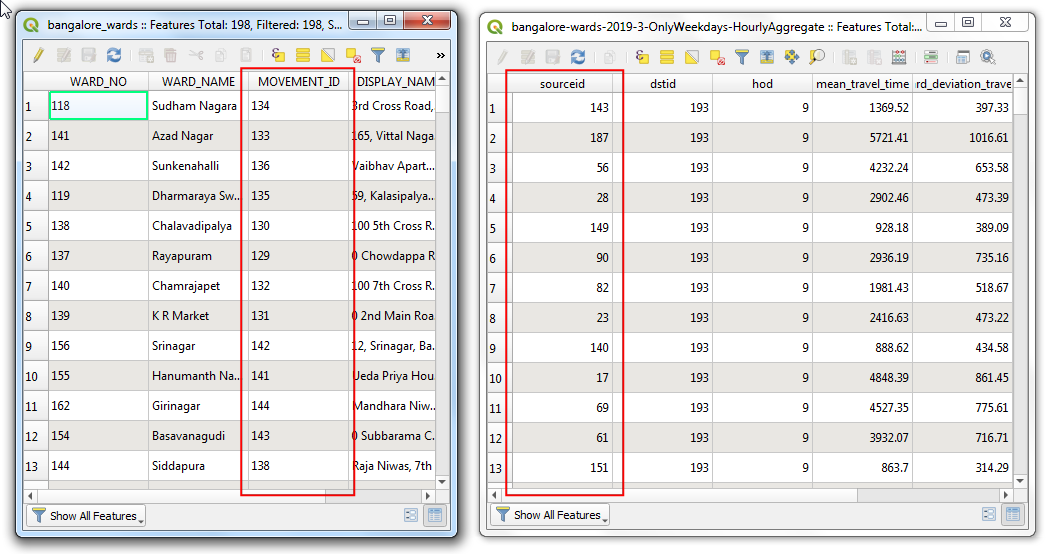
- 在对两个图层进行联合(join)之前,要保证两列中的数值严格一直。比如看上去一样,可能有不同的数据类型。因为GeoJSON格式不允许指定属性的数值类型,所有的值都是存储成字符串String,也就是文本。但当导入CSV到QGIS的时候,QGIS会智能地将这些列的类型根据值来进行解析,因此就会给sourceid这列解析成整数Integer。所以我们需要将GeoJSON里的列数据也转换到整数。在菜单栏中找到Processing → Toolbox,搜索Vector Table → Field Calculator算法,双击运行。
- 选择
bangalore_wards作为输入层Input Layer,将要合并的Field name值为joinfield,然后选择Result field type 作为整数Integer,输入"MOVEMENT_ID"作为表达式。点击… 按钮,就在Calculated旁,然后选中Save to File..,输入文件名,将文件保存成bangalore_wards_fixed.gpkg。点击Run,关闭Field Calculator。
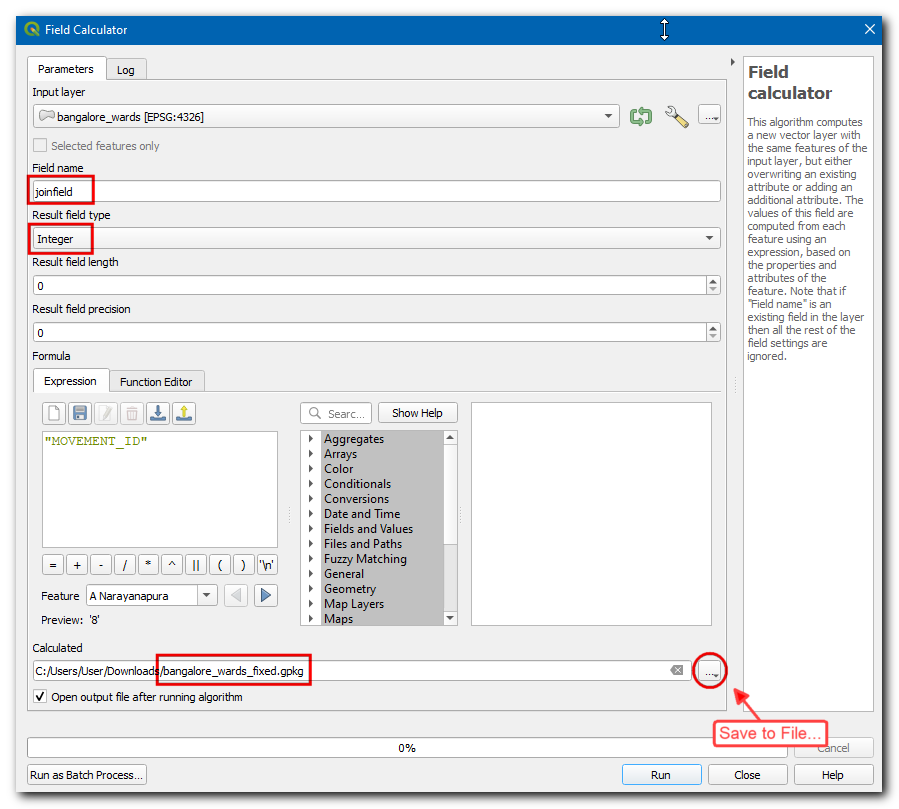
- 经过上面的步骤,在图层Layers 中就多了
bangalore_wards_fixed这一个新图层了。现在就可以进行联接(join)操作了。在Processing Toolbox里面搜索并找到Join attributes by field value算法 。
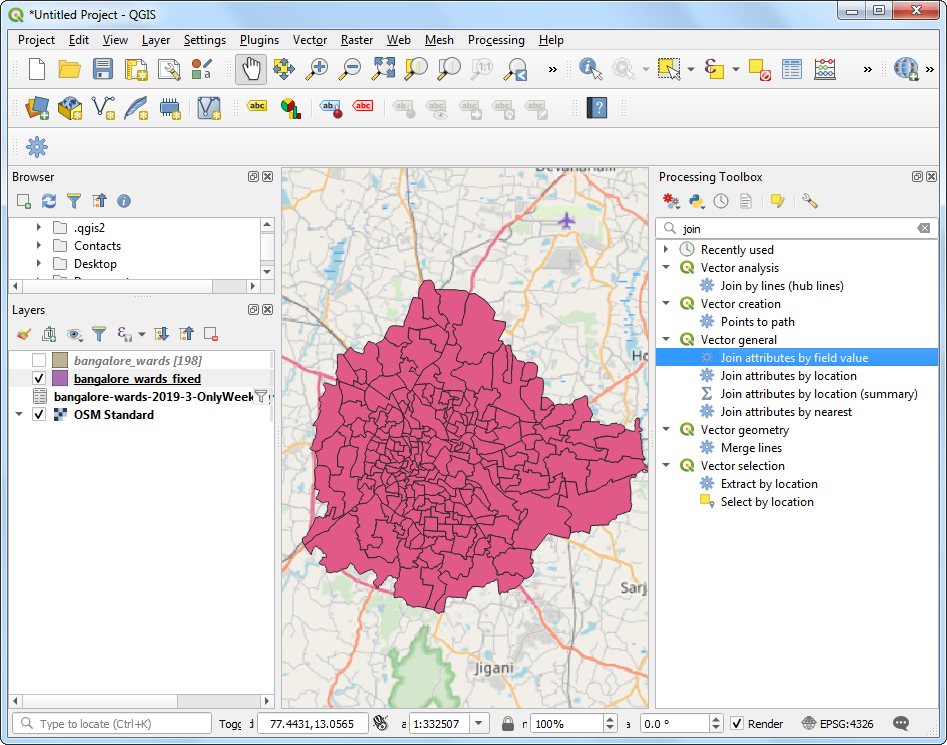
- 选择刚刚生成的
bangalore_wards_fixed作为输入层Input layer ,然后设Table field为joinfield。选择bangalore-wards-2019-3-OnlyWeekdays-HourlyAggregate作为第二输入层Input layer 2,并选择Table field 2作为sourceid。将Joined layer 命名为uber_travel_times.gpkg然后点击Run。
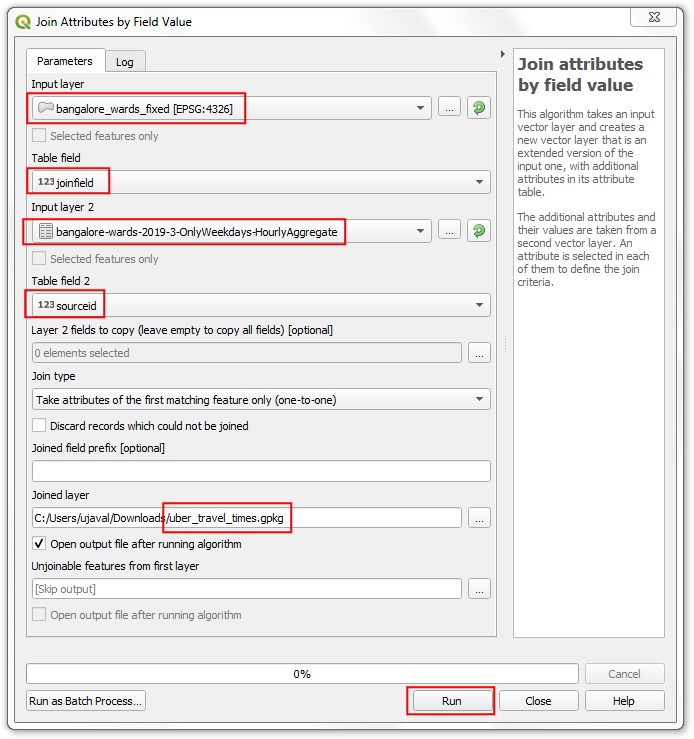
- 现在一个新的
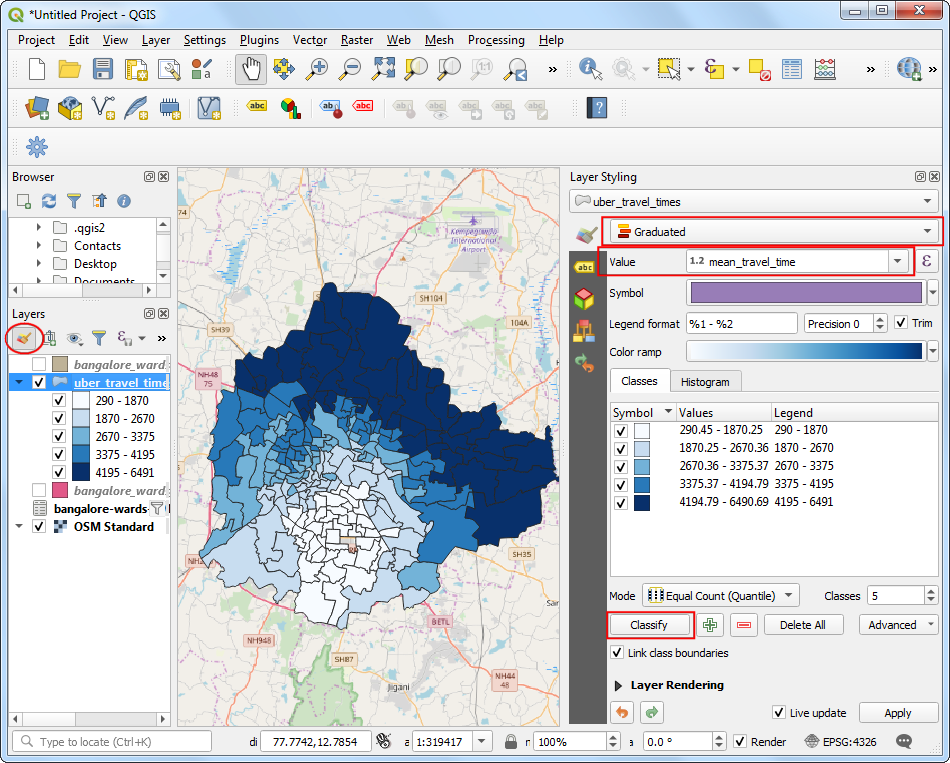
uber_travel_times图层就出现在图层面板Layers中了。接下来对其进行可视化的调整。点击Open the Layer Styling Panel,选择Graduated着色器,设置Value为mean_travel_time。选择一个配色方案然后点击Classify进行分类。就能看到随着距离目的地越远颜色就越深。
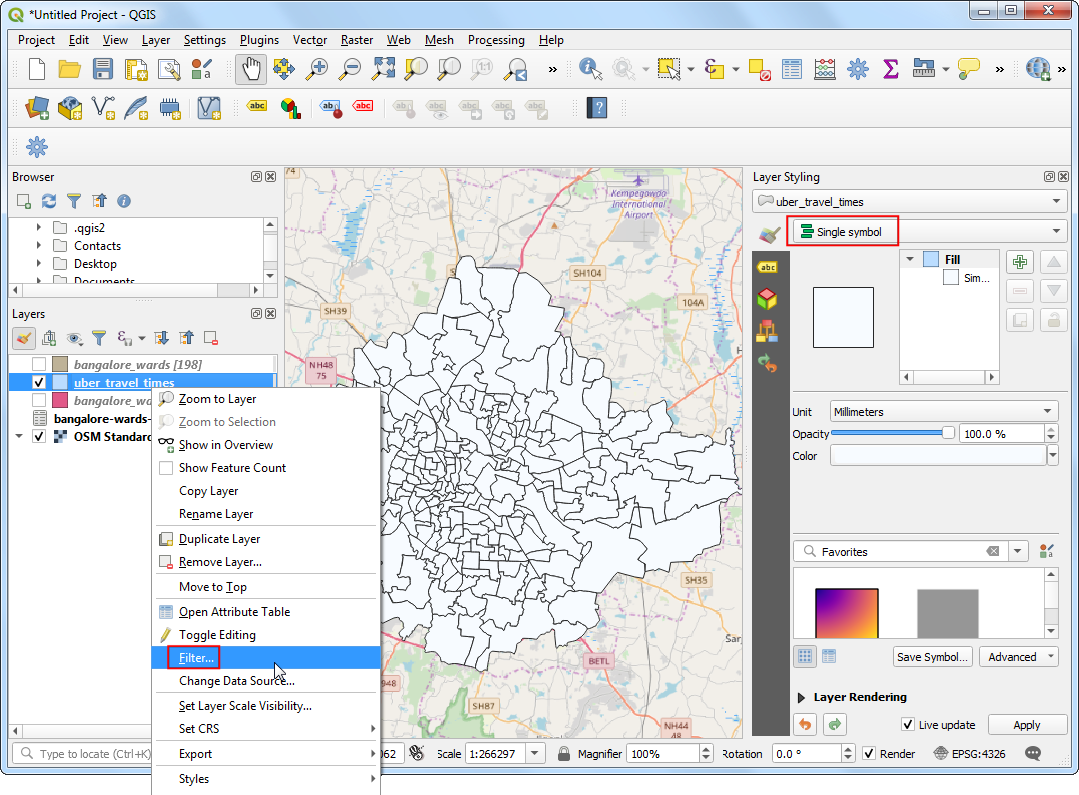
- 咱们想要提取和分析的是小于三十分钟的,所以还需要进一步处理一下。切换到Single symbol 着色器,右键
uber_travel_times图层选择 Filter。
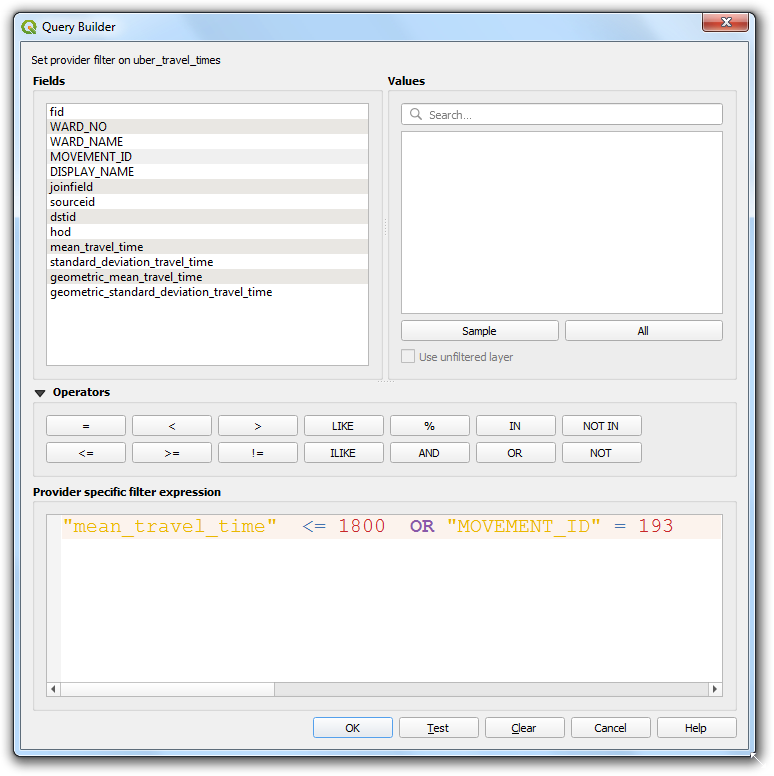
- 输入下面的表达式,选择所有平均旅程时间(mean travel time)小于等于1800秒也就是30分钟的(30 minutes) 。另外还要包含目的区域本身。
"mean_travel_time" <= 1800 OR "MOVEMENT_ID" = 193
- 现在这个图层就显示的是我们感兴趣的区域的众多多边形了。接下来咱们将这些多边形合并成一个多边形。在处理工具箱
Processing Toolbox中搜索Dissolve算法。
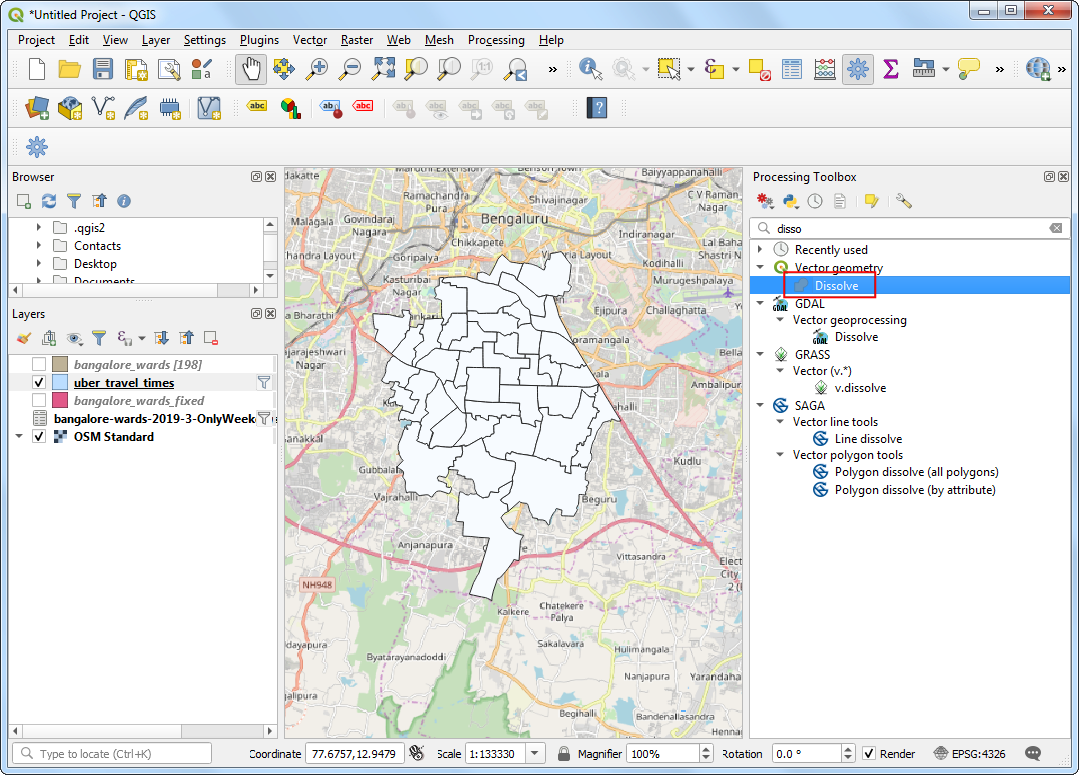
- 选择
uber_travel_times作为输入图层Input layer。将融合的Dissolved图层命名为30min_isochrone.gpkg,点击Run运行。
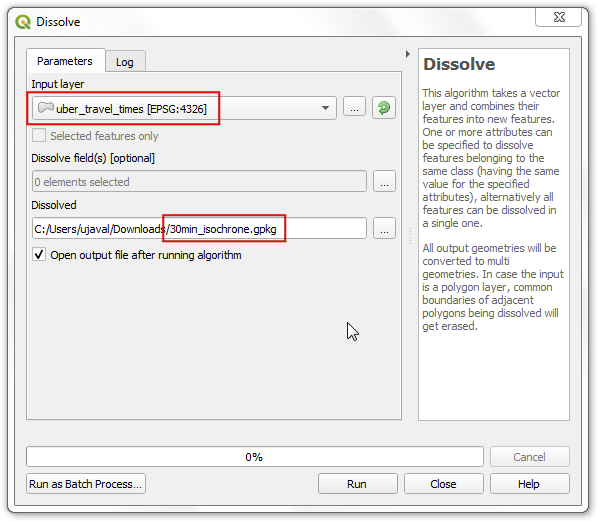
- 这样得到的新图层
30min_isochrone就出现在图层面板Layers中了。
练习:分析地铁可及性
在规划城市基础设施的时候,尤其是以交通为导向的发展规划(Transit-Oriented Development,TOD),一项指标就是公共交通可及性。 LiveMint上面有一篇关于印度公共交通挑战的文章对印度全国的地铁可及性进行了分析。这个练习中也要实现一个类似的分析过程。
通过这个分析,我们要确定在班加罗尔城中有多少人口生活在地铁站1km范围内。要解决这个问题,需要用到GIS的线条,结合多个离散数据源的相关信息。要进行这次的分析,首先要查询OpenStreetMap数据库来获得班加罗尔的地铁站位置。然后计算1km范围内的缓冲区域,再将其和基于WorldPop的人口网格(population grid)来完成人口分析。
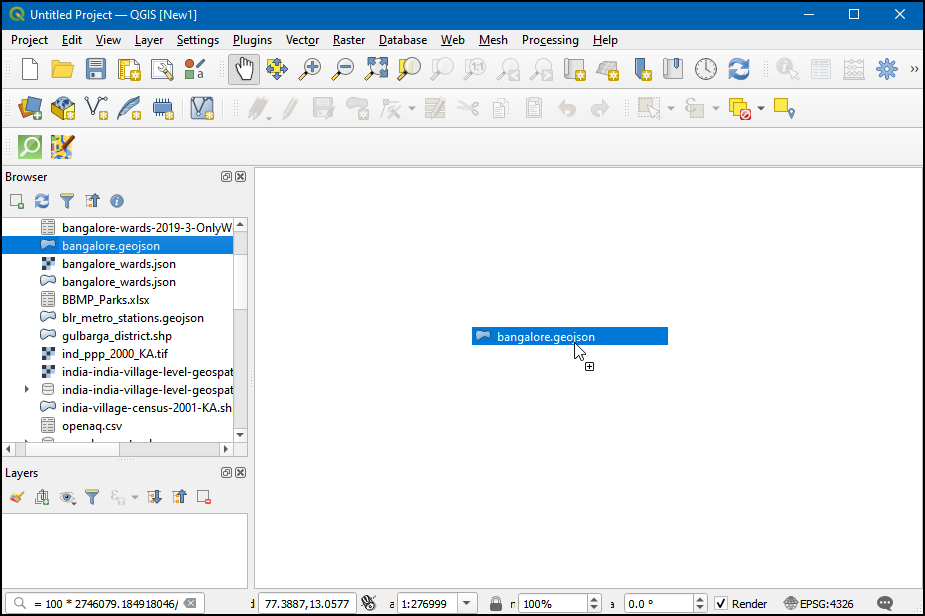
- 找到
bangalore.geojson文件,拖拽到QGIS的地图画布上。这个多边形表示的就是城市边界。
- 接下来查询OpenStreetMap来获得该城市上的铁路车站。到菜单栏中找到 Vector → QuickOSM → QuickOSM。OpenStreetMap 利用一个标签系统(tagging system)来记录物理特征的属性。这种标签和键值对的具体细节可以参考OpenStreetMap wiki。铁路车站的标签是
railway=station。在键名Key处设置为railway,键值Value设为station,地理位置过滤选项In设置为Bangalore 。扩展Advanced 区域,只选中 Node 和Points 两个勾选框。点击运行查询Run Query。
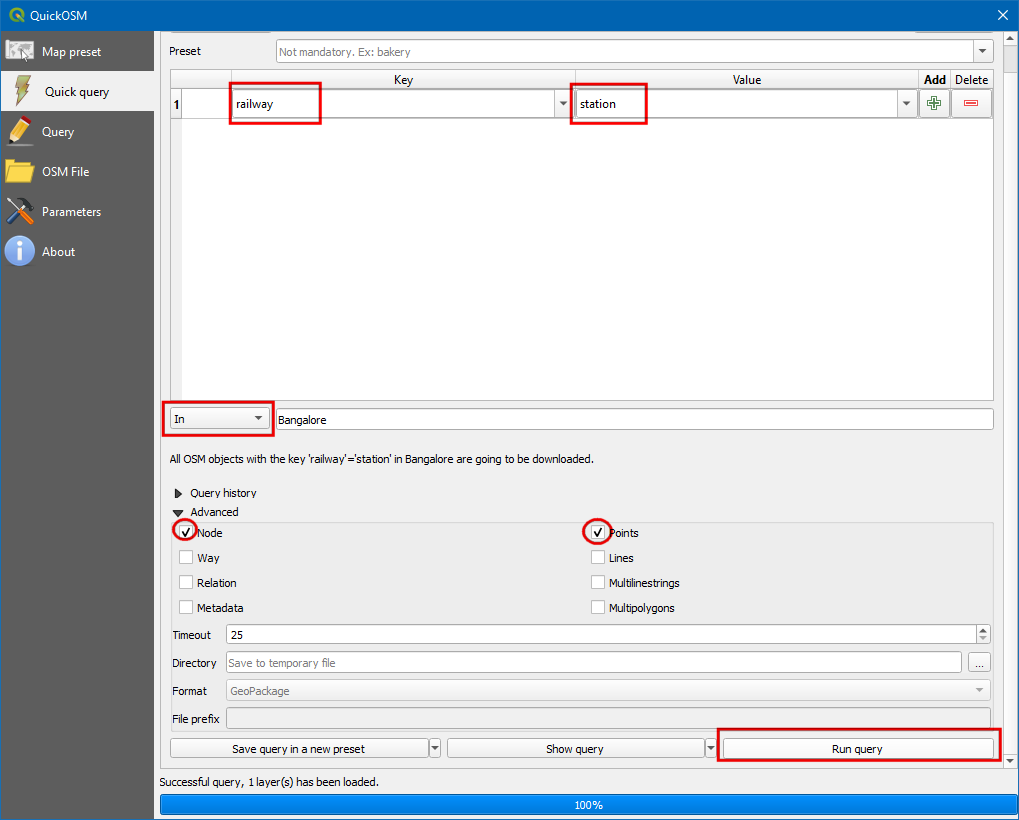
- 查询完成后,你就能看到新图层
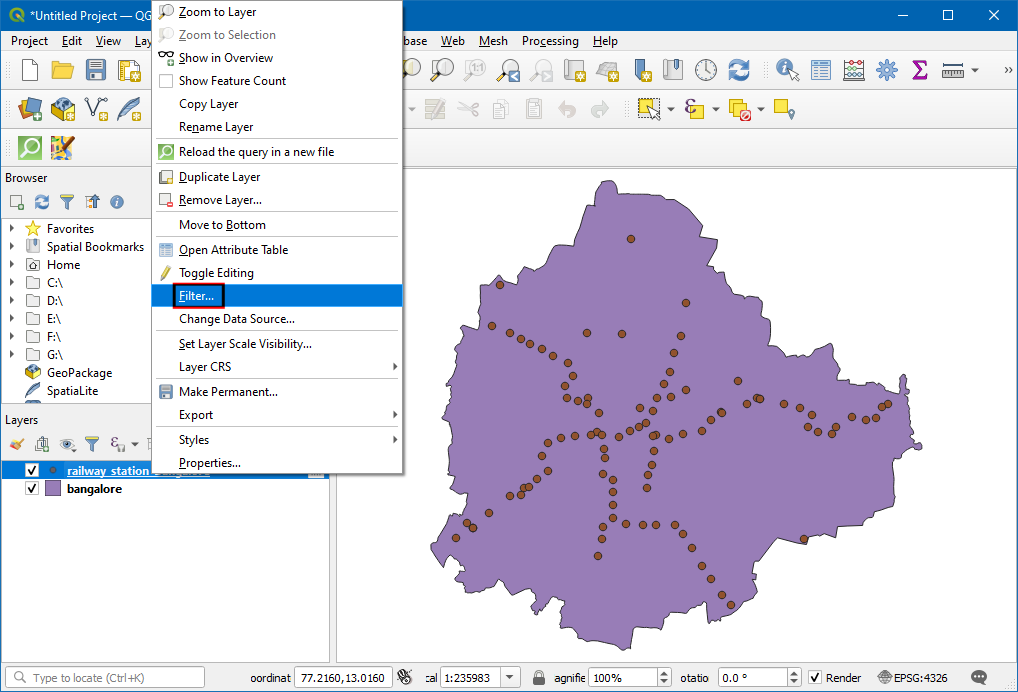
railway_station_Bangalore已经加载到地图画布上了。这个图层中包含铁路车站和在建设中的车站。接下来就要进行筛选,只保留我们关注的地铁车站。右键该新图层,选择筛选Filter。
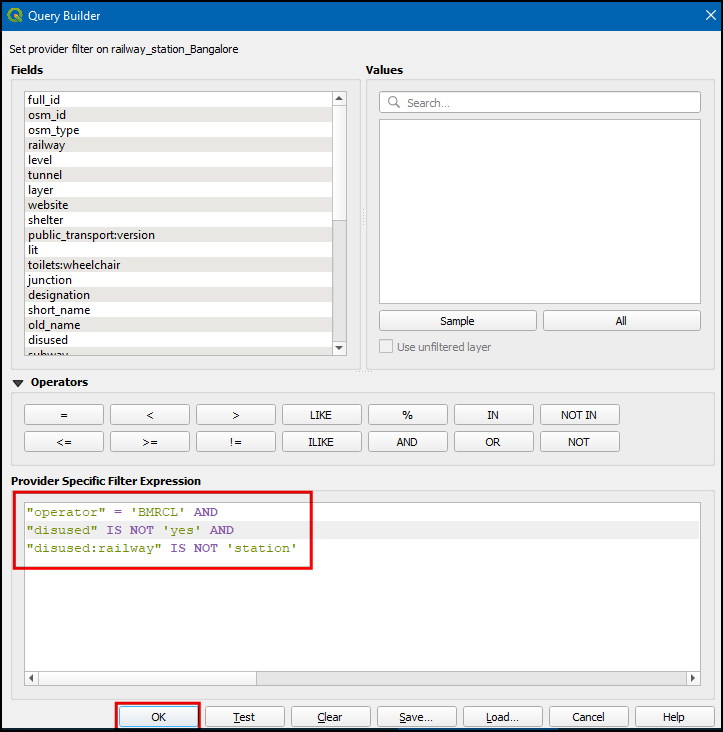
- 在Query Builder 输入下面的表达式,然后点击OK。
注意:这里的使用的是
IS NOT,而不是!=。这是因为这些列当中有位置为NULL。而NULL 并不是一个值,不能和其他值进行等于、不等于这样的比较。而IS NOT可以适用于所有类型,能够有效验证项目是否匹配,就包括NULL。
"operator" = 'BMRCL' AND
"disused" IS NOT 'yes' AND
"disused:railway" IS NOT 'station'
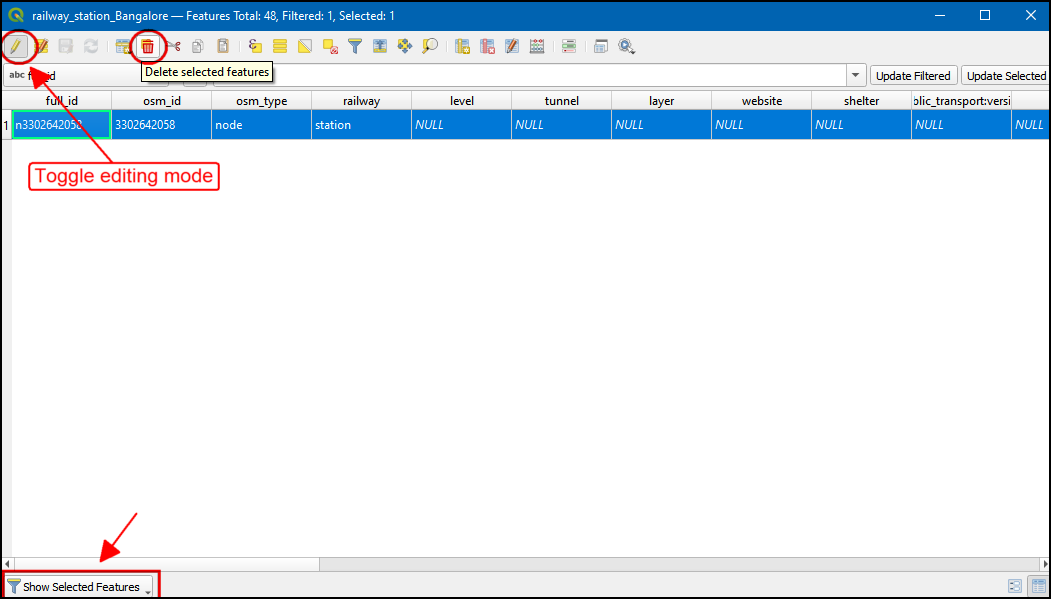
- 已建成但未连接到整个体系的车站是由于中间的车站还在建设。所以在可视化解译中,要再对这部分车站进行清洗。点击Select Features按钮,选择未连接的地铁站。然后点击Open Attribute Table图标。
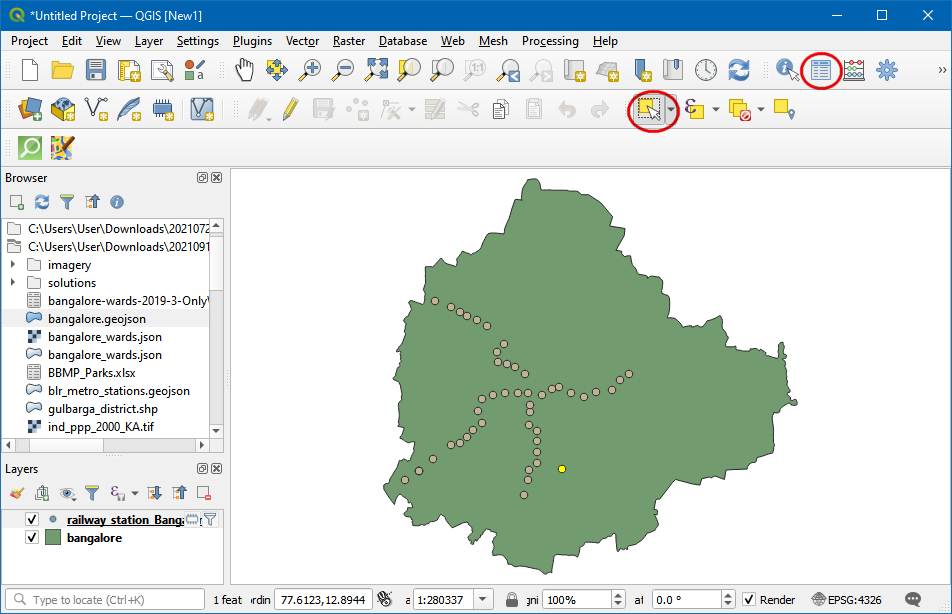
- 在属性表格中,切换到显示所选特征Show selected Features。然后直邮要删除的个别特征会显示出来。 然后就会凸显出刚刚选中的。现在点击左上角小铅笔图标进入编辑模式Toggle editing mode 然后点击小垃圾桶图标删除选中特征Delete selected features。完成之后,再点击小铅笔图标 Toggle editing mode,然后再点击Save保存。
- 现在地图就更新了,只保留了咱们想要的城区地铁站。接下来需要对这些站点应用一个缓冲处理Buffer来获得距离地铁站1km范围内的区域。但咱们的地图用的是EPSG:4326 WGS84地理投影,用的单位是度分秒。要将单位从度分秒转化到公里网格,就必须将图层重新投影到一个合适的坐标参考系统(coordinate reference system,CRS)。到菜单栏中找到Processing → Toolbox,搜索定位到Vector general → Reproject layer 算法,双击运行。
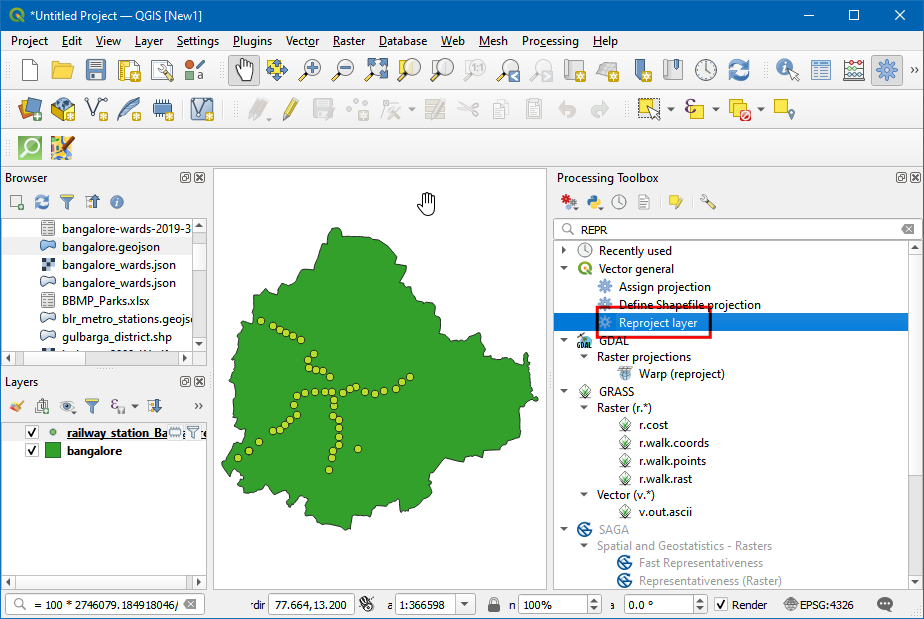
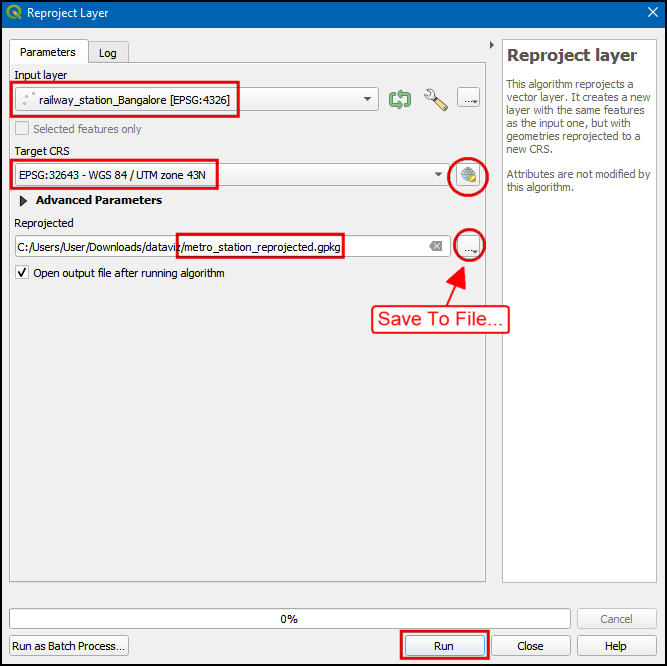
- 选择
railway_station_Bangalore作为输入层Input layer。点击下图所示的小图标,目标坐标参考系Target CRS选择EPSG:32643 - WGS 84 UTM Zone 43N。将重命名的Reprojected图层命名为metro_stations_reprojected.gpkg。
- 重新投影的
metro_stations_reprojected图层创建好后,在Processing Toolbox中搜索Vector geometry → Buffer然后双击运行算法。
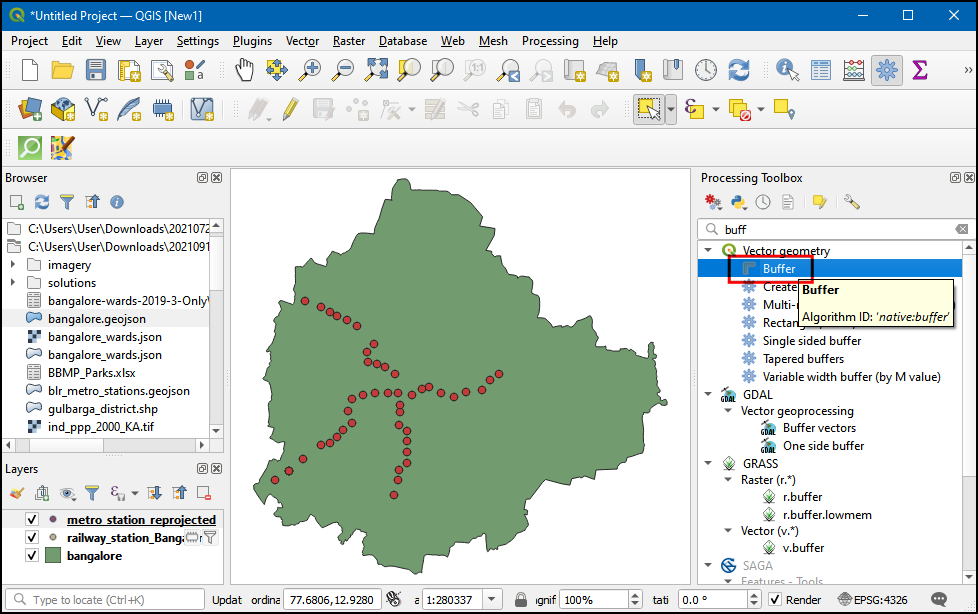
- 将
metro_stations_reprojected设做输入层Input layer。设置Distance为1 kilometer。选中Dissolve result 选项,然后将Buffered 输出图层命名为metro_stations_buffer.gpkg。点击Run来运行。
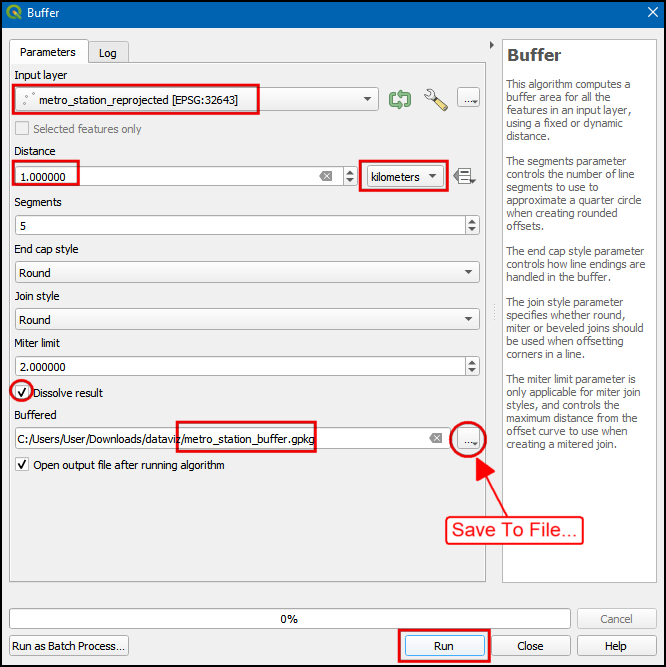
- 现在图层中就出现了刚刚得到的距离地铁站范围1km的多边形组成的新图层
metro_stations_buffer了。图层上的一个个圆表示的就是距离地铁站圆心1km范围。地理处理完成了,我们接下来将得到的图层再转换回原来的坐标参考系。在Processing Toolbox中搜索Vector general → Reproject layer算法然后运行。
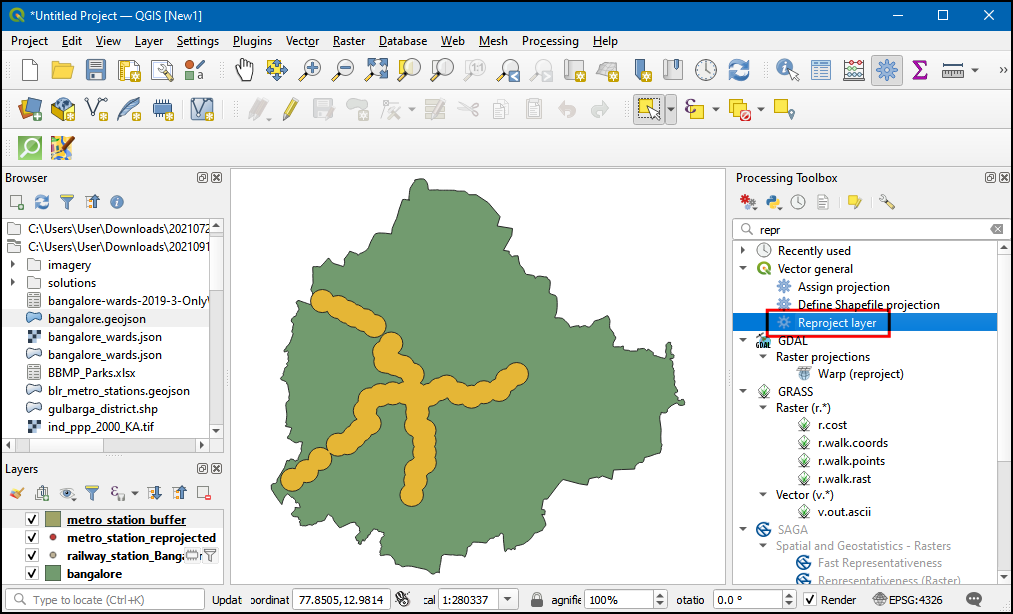
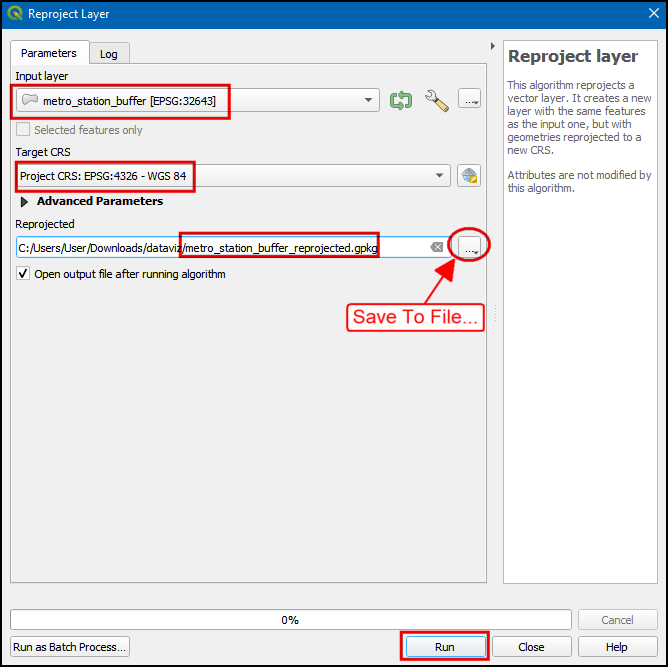
- 选择刚刚生成的
metro_stations_buffer图层作为输入图层Input layer,然后设置Target CRS为EPSG:4326 -WGS 84。将新生成的图层命名为metro_station_buffer_reprojected.gpkg。点击Run运行。
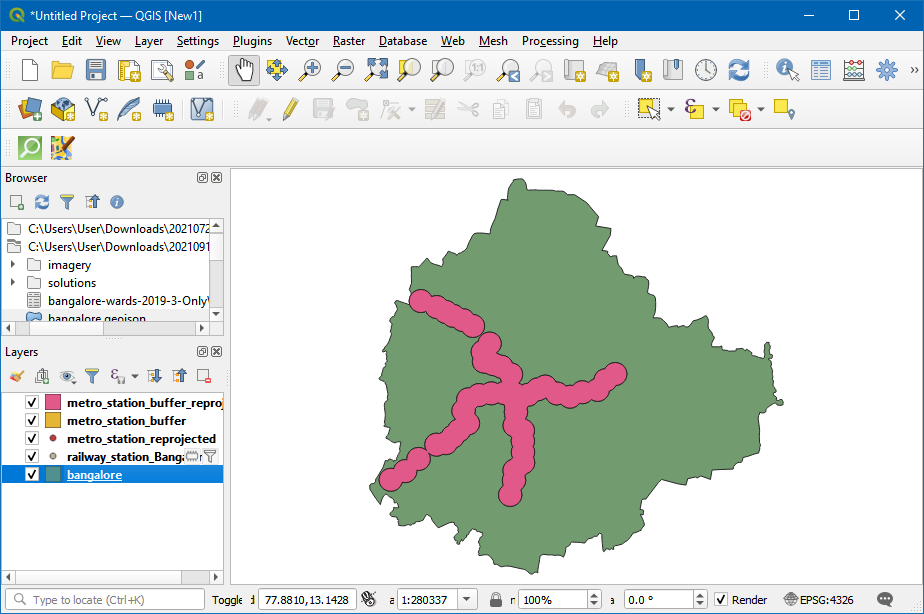
- 新图层
metro_station_buffer_reprojected就被添加到画布上了,表示的是距离地铁站1km范围内的地方。之前已经有了bangalore图层表示整个城区范围。接下来要给这些图层添加人口数据。
- 找到
ind_ppp_2000_KA.tif文件,拖拽到画布上。
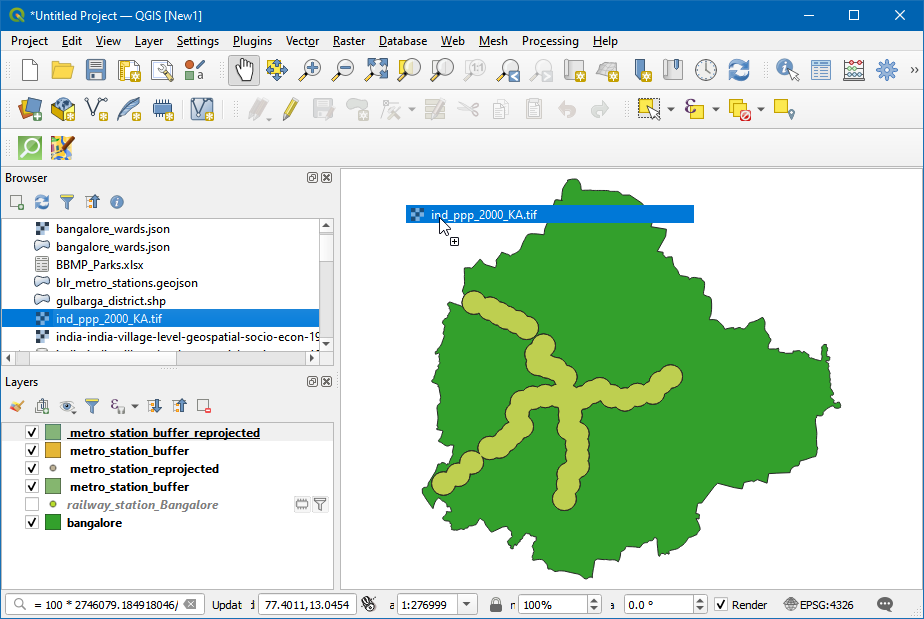
- 选择
ind_ppp_2000_KA图层,然后使用 Identify工具查看像素质。这个栅格图像的分辨率大约是100m x 100m,单一通道,每个像素的值是对应大小区域的估计人口。
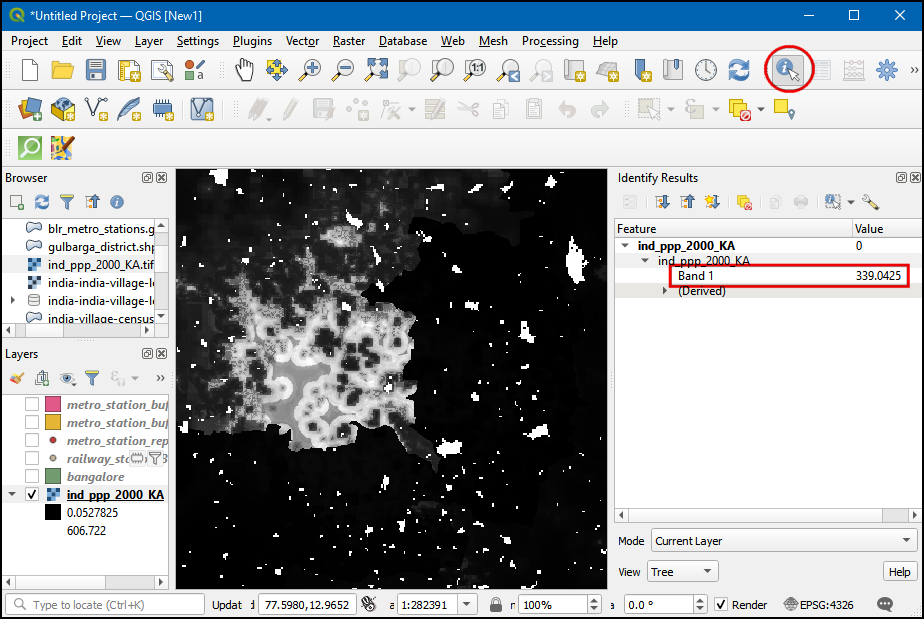
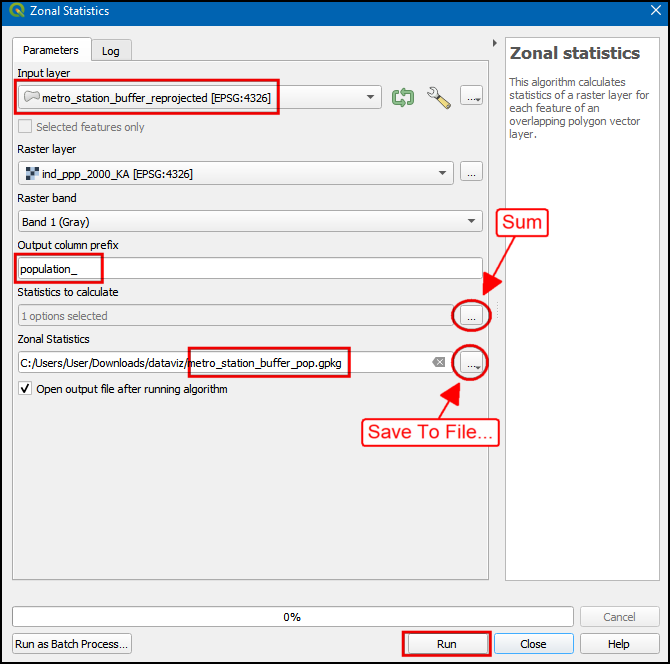
- 将所有落在多边形的区域中的像素加到一起就能获得对应区域的总人口。这个操作也叫区域统计Zonal Statistics。在Processing Toolbox中搜索Raster analysis → Zonal statistics算法。这个算法是对每个层增加了一个新属性,这个属性存储的是每个层当中包含在多边形中的总人口。双击运行。
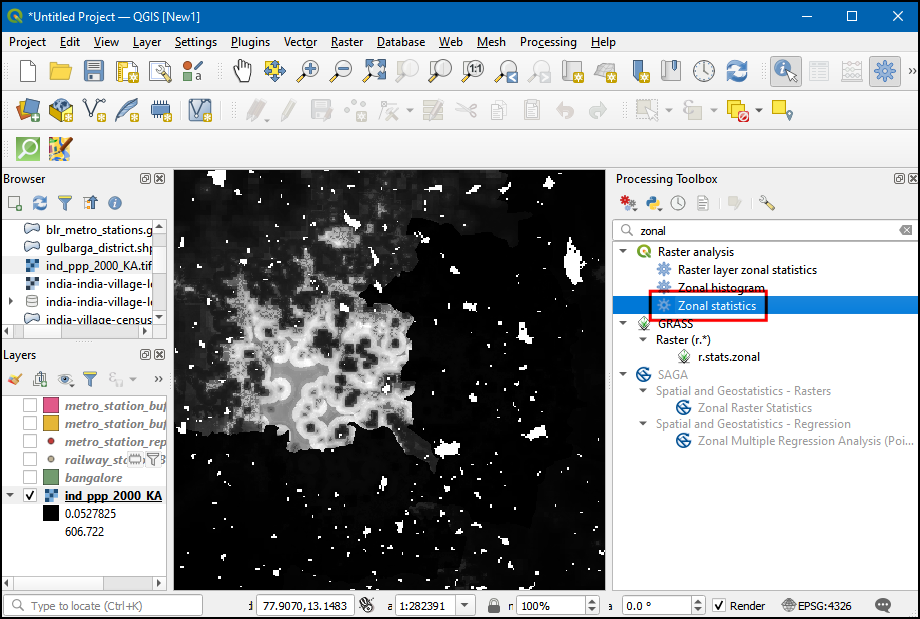
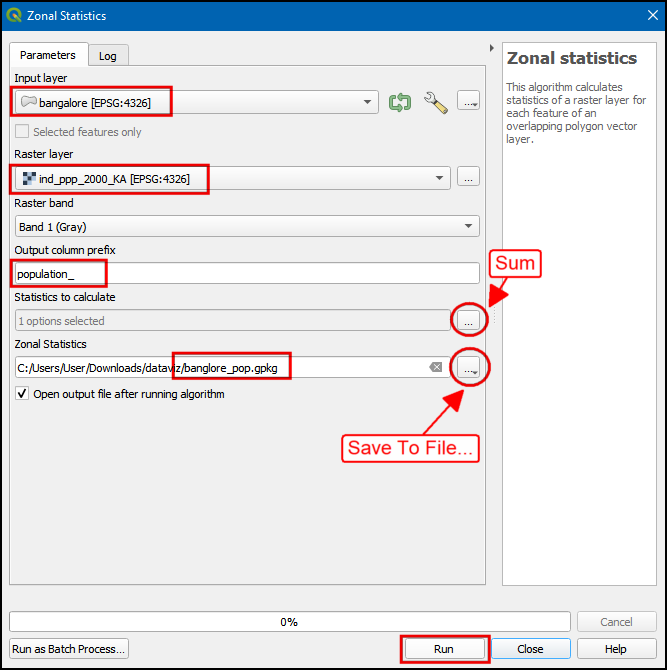
- 选择
bangalore作为输入层Input layer,将ind_ppp_2000_KA作为栅格层Raster layer。输入population_作为输出列前缀Output column prefix。我们感兴趣的只是总和Sum,所以点击Statistics to calculate旁边的...,然后只选中Sum。在Zonal Statistics 中点击...然后将生成文件设置保存为banglore_pop.gpkg。点击Run运行。
- 算法完成后,选择
metro_station_buffer_reprojected作为输入层Input layer。然后再Zonal Statistics 中点击...将生成层保存为metro_station_buffer_pop.gpkg。点击Run运行。
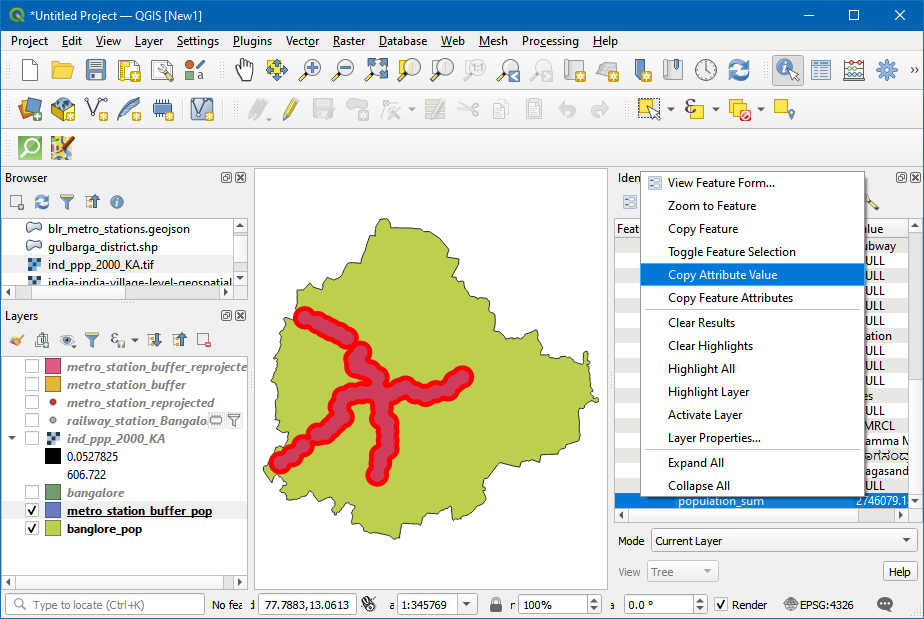
- 现在地图画布上就出现了新生成的两个图层了。点击
banglore_pop然后使用Identify工具,然后点击多边形。里面的population_sum 就应该是人口了。可以📧然后选择复制属性值Copy Attribute Value。
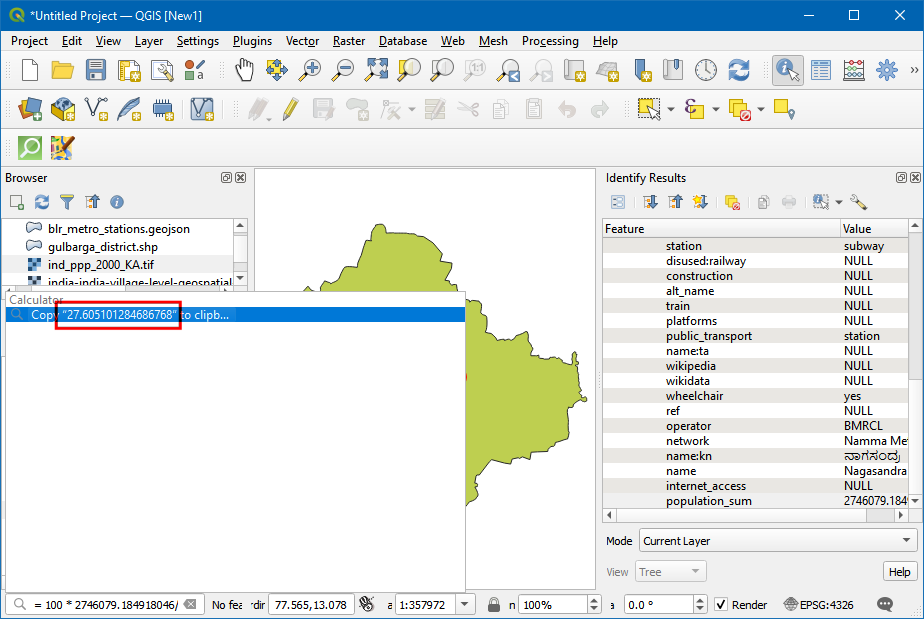
- QGIS 有一个内置计算器。点击界面左下角的Locator窗体然后输入等号
=。将metro_station_buffer_pop和banglore_pop的人口总数粘贴进去,算出比值。得到的结果就是班加罗尔城市中住在地铁周围1km范围内的人口比例。
= 100 * pasted value from from metro_station_buffer_pop / pasted value from banglore_pop
练习:绿地分布
拥挤的城市区域中,公园之类的开放空间很有必要。这些场所不仅能改善环境提供娱乐设施,还对人的心理健康有正面影响。
本次练习中,我们使用来自Bruhat Bengaluru Mahanagara Palike (BBMP)出版的公园列表,计算城市中每个分区的公园面积。这个数据可以通过 OpenCity - Urban Data Portal 获取到PDF格式的文件。本课程原作者将PDF格式数据文件使用Zamzar Online file conversion转换成了表格文件BBMP_Parks.xlsx。
注意,本练习只考虑每个区域的公园总面积。但实际上公园质量也很重要,对此的相关分析可以参考Parks and Playgrounds Score of Bengaluru Report。
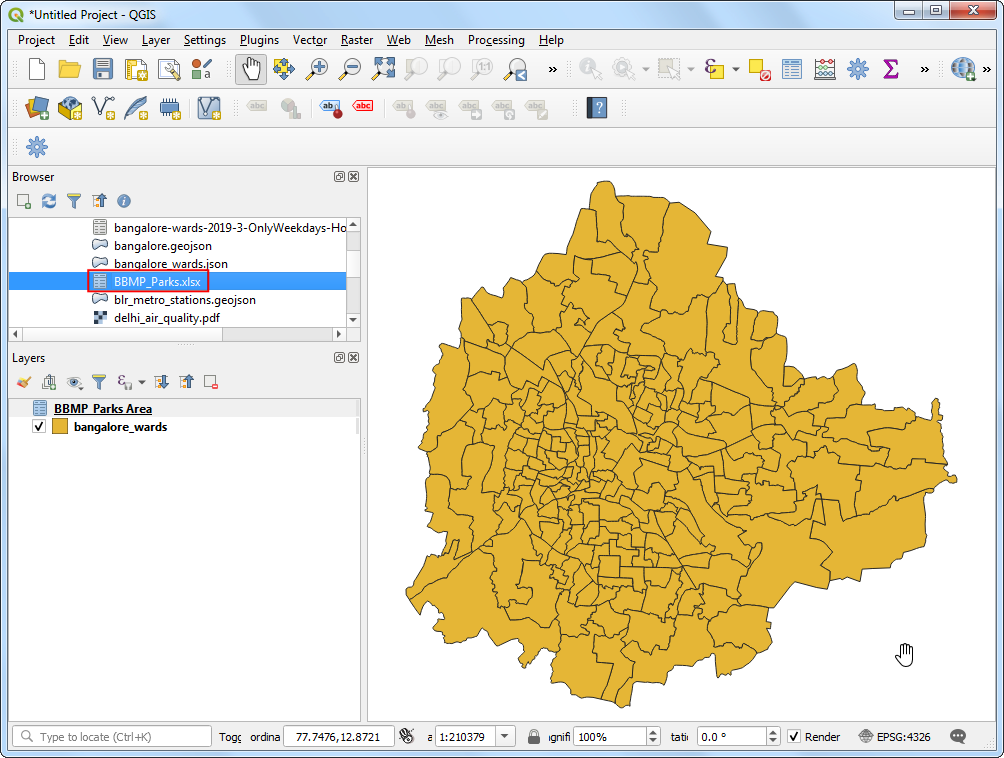
- 将
bangalore_wards.json文件拖拽到QGIS地图画布上。然后找到BBMP_Parks.xlsx文件。QGIS也可以直接读取Excel文件。拽到画布上就可以,现在就有bangalore_wards和BBMP_Parks_Area两个图层出现在图层面板Layers 。
- 选中
BBMP_Parks_Area图层然后点击Open Attribute Table。可以看到数据有超过900多行,每行都描述了一个公园和对应的面积,单位是平方米。我们不需要提取公园的地理位置坐标,但需要知道归属的区。
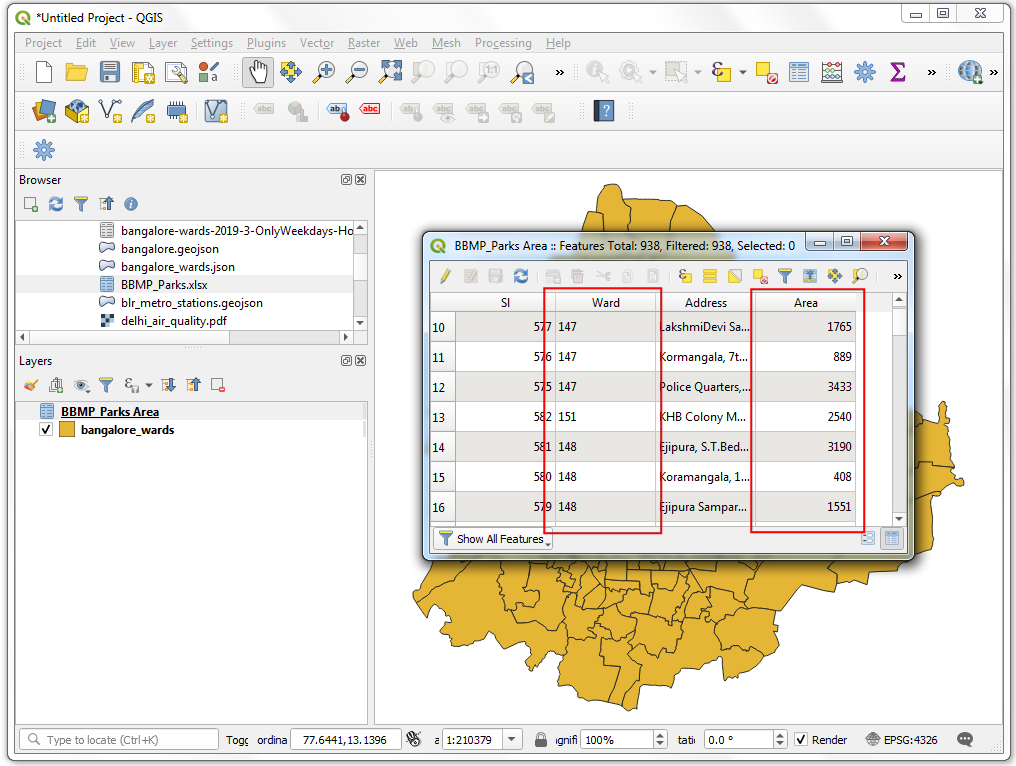
- 接下来可以按照各个区计算每个区一共有多少个公园。打开Processing Toolbox然后搜索Vector analysis → Statistics by categories 算法,双击运行。
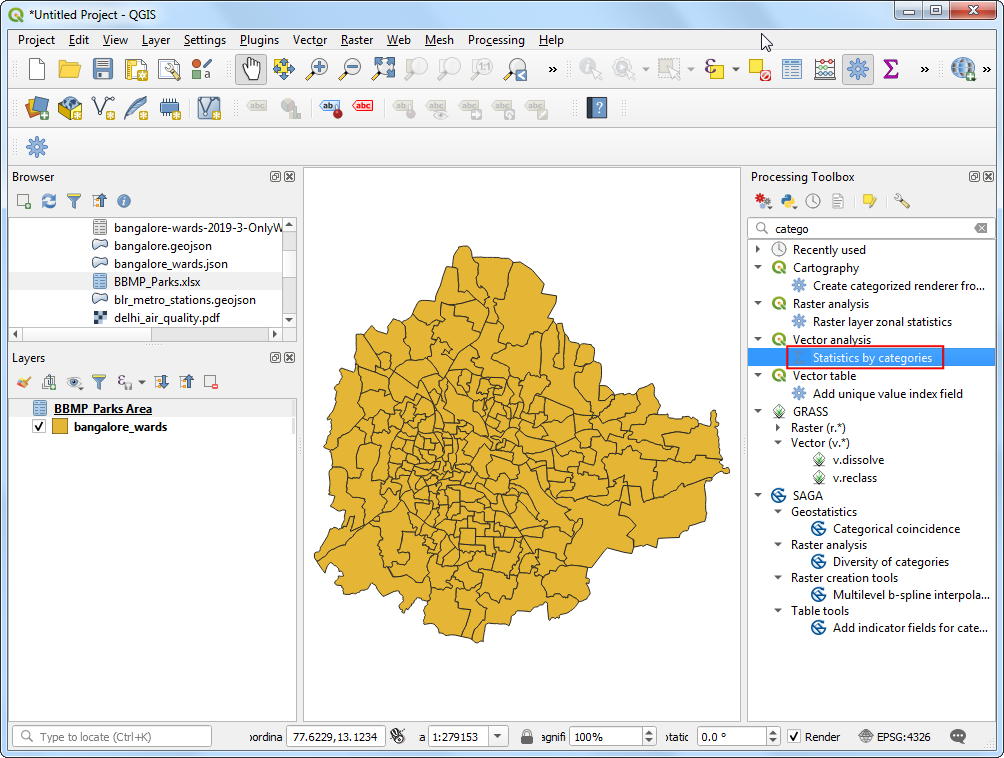
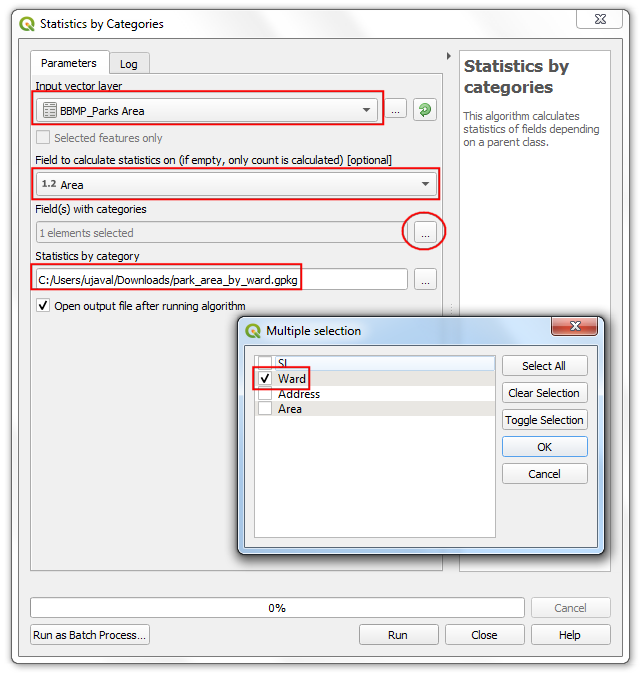
- 选中
BBMP_Parks_Area图层作为输入向量层Input vector layer。选中Area作为Field to calculate statistics on. 由于要按区分辨,选中Ward作为Field(s) with categories。将生成的Statistics by category层存储为park_area_by_ward.gpkg。点击Run运行。
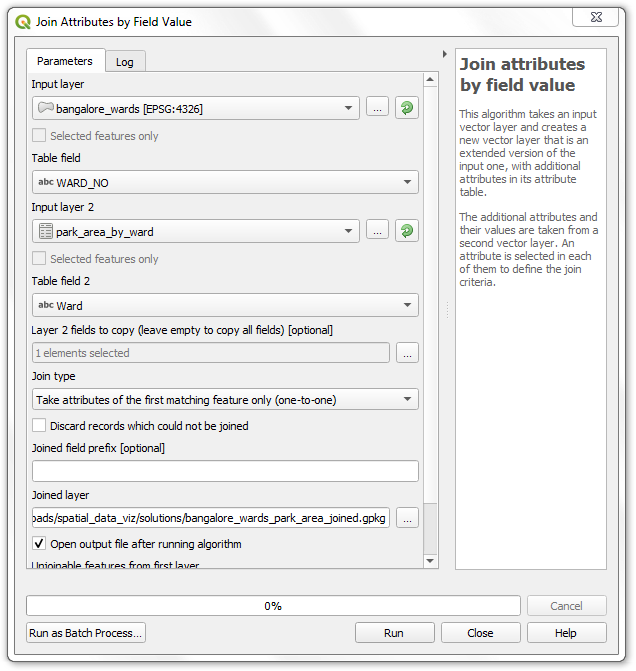
- 接下来每一个区都有一个对应的面积总和sum,然后可以将其于一个空间图层联接起来。在
Processing Toolbox里面搜索Join attributes by field value算法。选中bangalore_wards作为输入层Input layer,然后设置WARD_NO作为Table field。选择park_area_by_ward作为第二输入层Input layer 2,设置Ward为Table field 2。这里的park_area_by_ward包含很多列,但我们要用的只有sum。所以选中sum作为Layer 2 fields to copy。将输出层命名为bangalore_wards_park_area_joined.gpkg然后点击Run运行。
可能会有警告提示你不是所有的特征都成功联接。这是因为Excel文件并不能包涵覆盖所有区域的全部数据。这对于咱们的练习分析目的来说没啥影响,不用担心。
- 新图层
bangalore_wards_park_area_joined就出现在图层面板Layers了。在完成结果之前,可以将每一列都重命名一下使之更容易理解。在Processing Toolbox里面搜索找到Vector table → Refactor fields 算法。
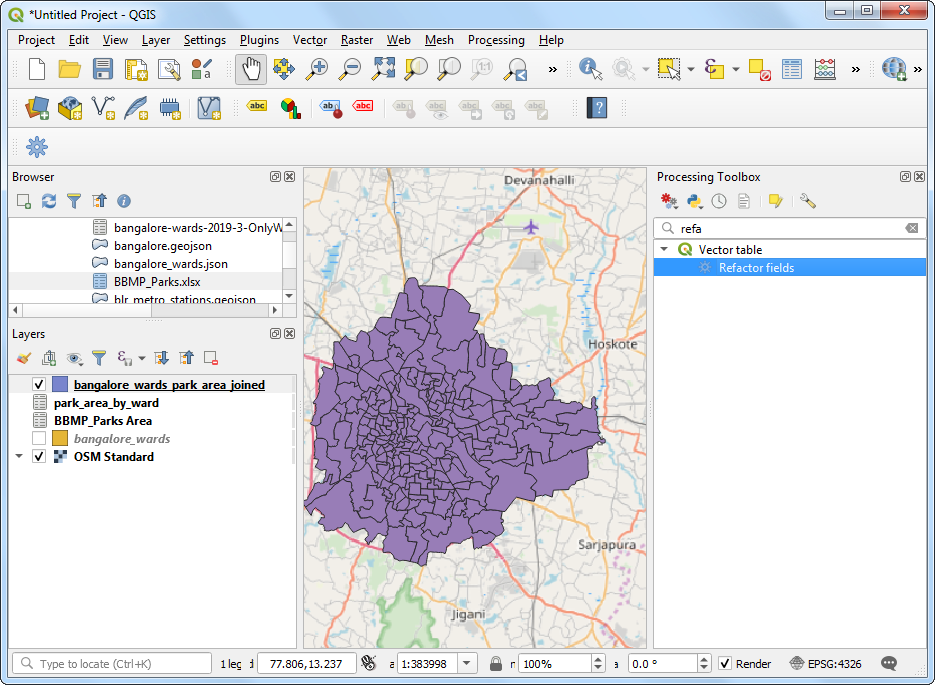
- 选中不需要的列,然后用Delete field移除。对于sum列,输入
PARK_AREA作为名称Field name。然后将Refactored输出的文件名设置为bangalore_wards_park_area.gpkg,点击Run运行。
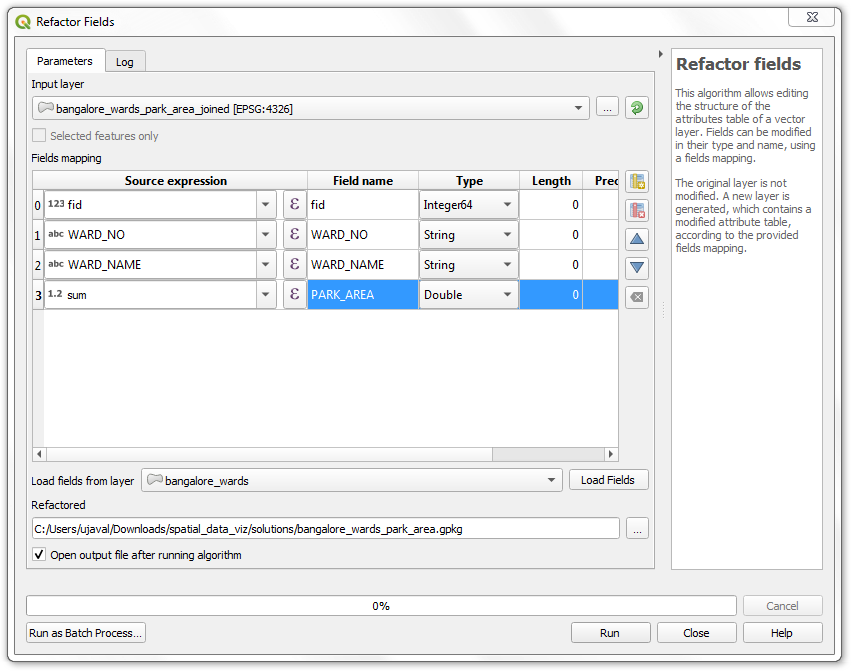
- 得到的新图层
bangalore_wards_park_area也能在图层面板Layers里看到了。打开一下属性表格查看各分区的公园面积吧。
练习:选择最佳居住区
寻找最优区域是空间分析技术的常见实用场景。使用合适的模型,就可以将多种因素一起考虑,然后推断出排列顺序。这里我们使用的是一个真实的场景,要在一个城市中根据多个因素寻找最佳居住场所。
本次练习所选用的优选因素如下:
- 距离工作地必须在三十分钟车程范围内,办公地点设为Spatial Thoughts office。
- 距离地铁站点必须在1km范围内。
- 要有公园,无公园的区域不考虑。
前面的练习已经为这次联系准备了数据:
30min_isochrone.gpkg图层表示的是距离工作地30分钟的区域。metro_station_buffer_reprojected.gpkg图层表示的是地铁周围1km范围。bangalore_wards_park_area.gpkg表示了每个区的公园面积。
接下来就把上面这几层都用上,交叉分析出来就可以了。
- 将
30min_isochrone.gpkg、metro_station_buffer_reprojected.gpkg、bangalore_wards_park_area.gpkg这三个文件拖拽到QGIS里面,然后在Processing Toolbox里面搜索Vector overlay → Intersection算法,双击运行。
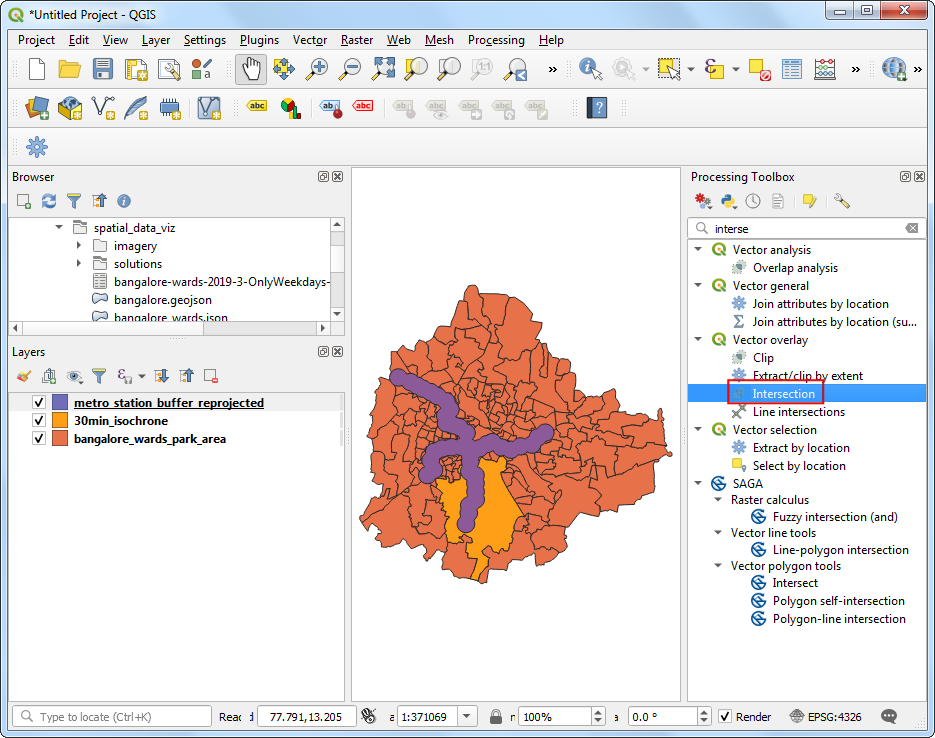
- 选中
30min_isochrone作为输入层Input layer,选中metro_station_buffer_reprojected作为叠覆层Overlay layer。设置Intersection交叉生成文件为intersection.gpkg。点击Run运行。
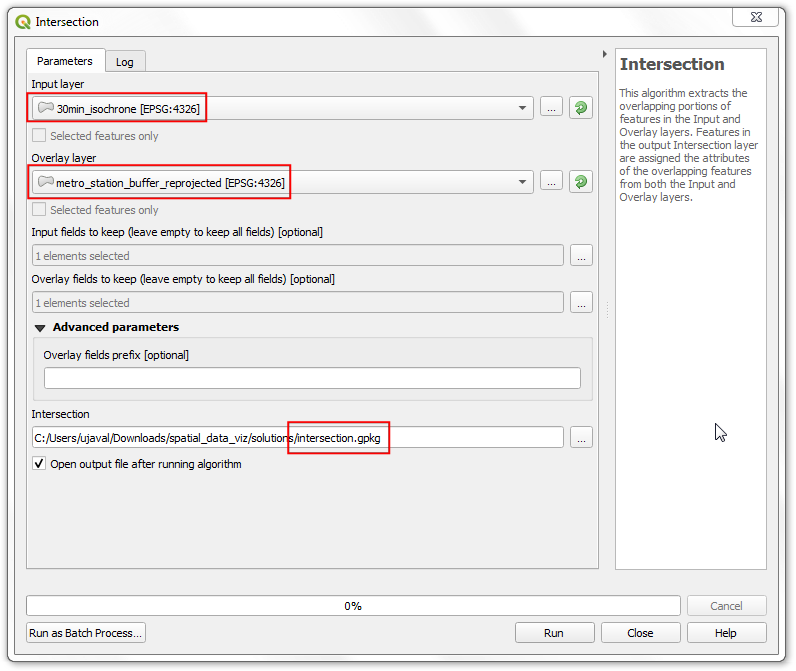
- 得到的
intersection图层表示符合地铁站1km和开车通勤时间30分钟内这两个条件。接下来要用第三个条件筛选。在Processing Toolbox中搜索定位到Vector analysis → Overlap analysis 算法,双击运行。
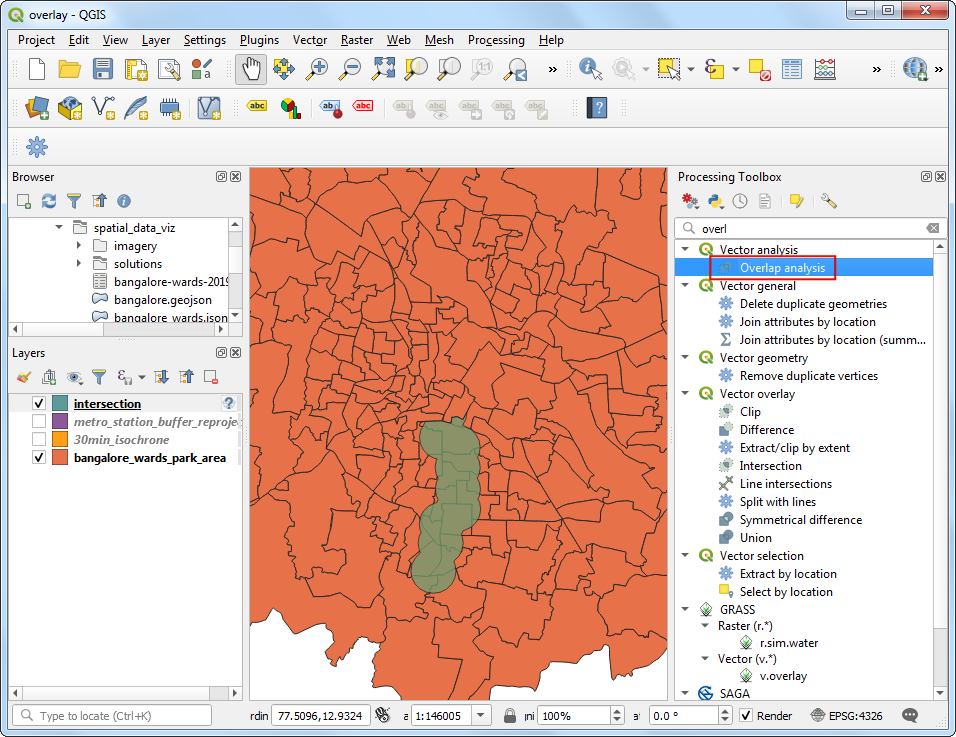
- 选中
bangalore_wards_park_area.gpkg作为输入层Input layer。选中intersection作为叠覆层Overlay layer。将输出层Output layer命名为park_intersection_overlap.gpkg,然后点击Run运行。
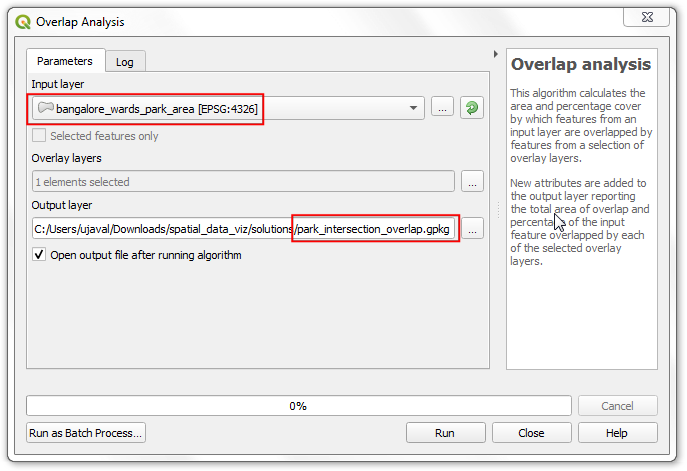
- 得到的新图层
park_intersection_overlap比原来的多了两列:intersection_area和intersection_pc。对每个多边形,现在知道每个区域与我们感兴趣区域的交叉比例。如果假设公园在每个区都是均匀分布,就一使用intersection_pc这个参数计算公园比例。在Processing Toolbox中搜索定位到Vector Table → Field Calculator 算法,双击运行。
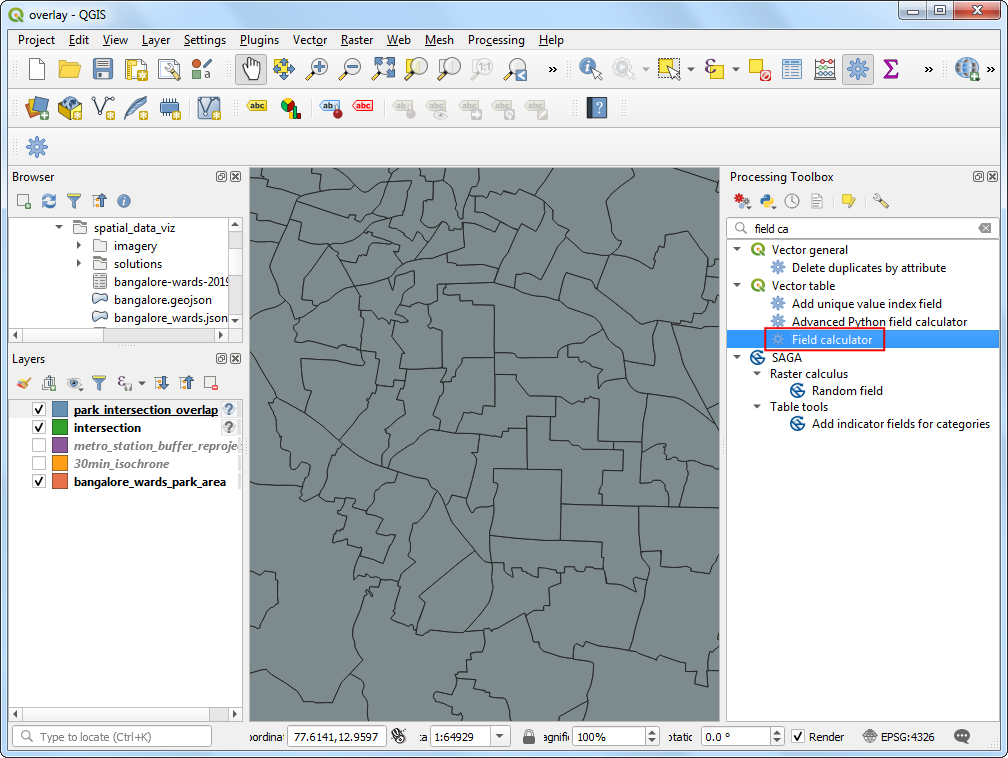
- 输出文件Output file设置为
park_intersection_percentage_area.gpkg。将输出域名Output field name设置为perc_area。输入下面的表达式,然后点击OK。
("intersection_pc" * "PARK_AREA")/100
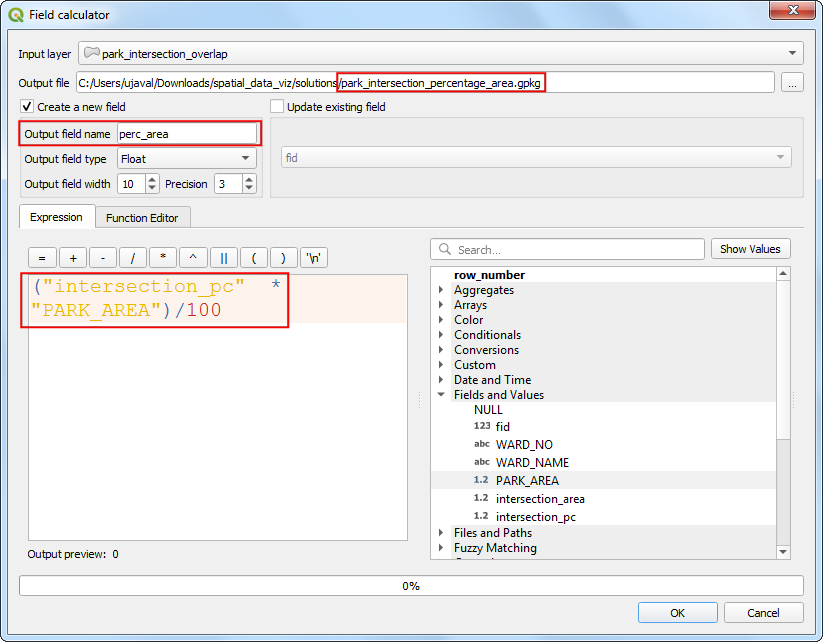
- 基本就差不多了,现在就知道兴趣区内每个地区的公园总面积了。可以排一下顺序。在ProcessingWe Toolbox里面搜索定位到 Vector Table → Add autoincremental field 算法,双击运行。
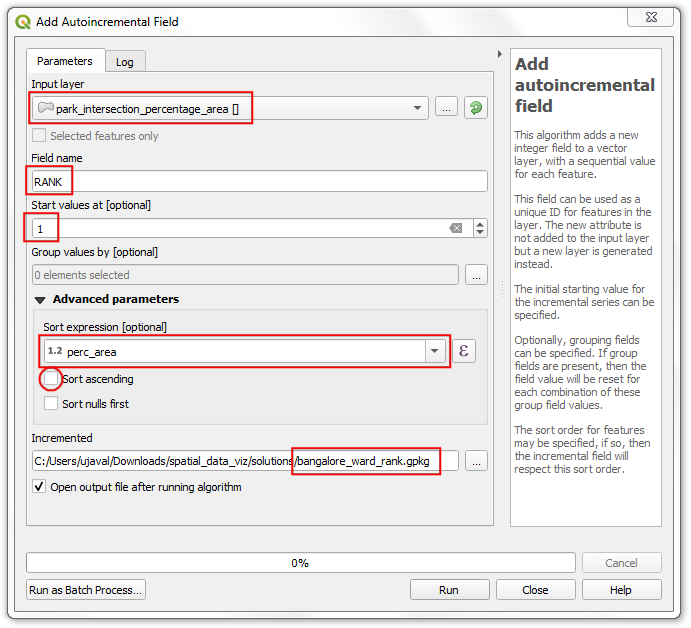
- 选择
park_intersection_percentage_area作为输入层Input layer。输入RANK作为Field name ,输入1作为Start values at。扩展Advanced parameter区域然后选perc_area作为Sort expression。去掉勾选Sort ascending。将Incremented 输出层命名为bangalore_ward_rank.gpkg然后点击Run保存。
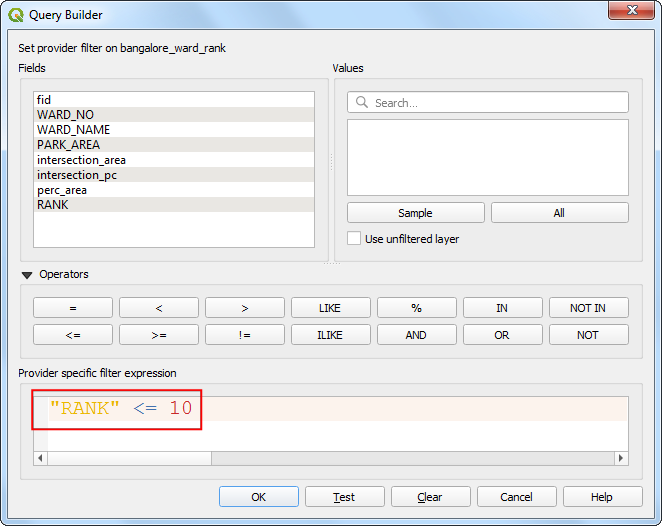
- 右键新生成的
bangalore_ward_rank图层选中筛选器Filter。输入下面的表达式就获得前十个候选区域。
"RANK" <= 10
- 接下来看到的就是排名最靠前的十个区域。点击Open the Layer Styling Panel 切换到Labels标签页。选择Single labels然后设置
RANK作为Value。这样地图上就显示出排序了
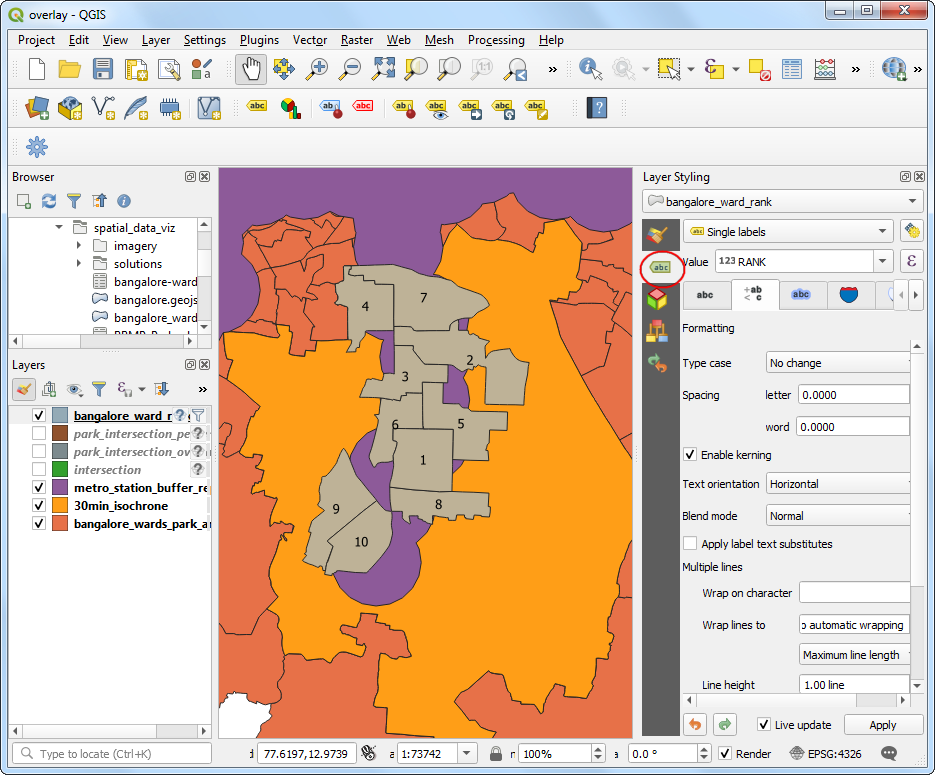
补充资料
查看云优化的无人机图像
Zanzibar Mapping Initiative (ZMI)是坦桑尼亚科学和技术委员会(Tanzania Commission for Science and Technology ,COSTECH)和桑吉巴尔革命政府(Revolutionary Government of Zanzibar,RGoZ)的一项合作计划。这个计划正在拍摄无人机照片来为桑吉巴尔创建航拍地图,并通过开放航拍计划 OpenAerialMap公开。
针对这样的大规模图像的使用和分析,有一种新文件格式叫做云优化的地理信息位图 Cloud-Optimized GeoTIFF (COG) 。作为一种「云优化」(Cloud-optimized )的GeoTIFF格式,和之前我们看到的常规GeoTIFF一样有地理信息,但不需要将所有图像下载到本地,你就可以读取图像的一部分(portions),使用的是云端服务推流技术,客户端就是QGIS这类软件。这就使得对这类数据的读取和分析非常简单方便,不用下载很大的文件了。
桑吉巴尔测绘计划的所有图像的收集和处理都是以云优化的GeoTIFF格式存储在亚马逊S3云上。接下来我们用QGIS来查看一下。
- 首先要在 OpenAerialMap 上访问Zanzibar Mapping Initiative (ZMI) 的用户页面。找到你要用的图像,右键
Download raw .tiff image file按钮,然后选中复制链接地址Copy Link Address。本次练习使用的是这个图像链接
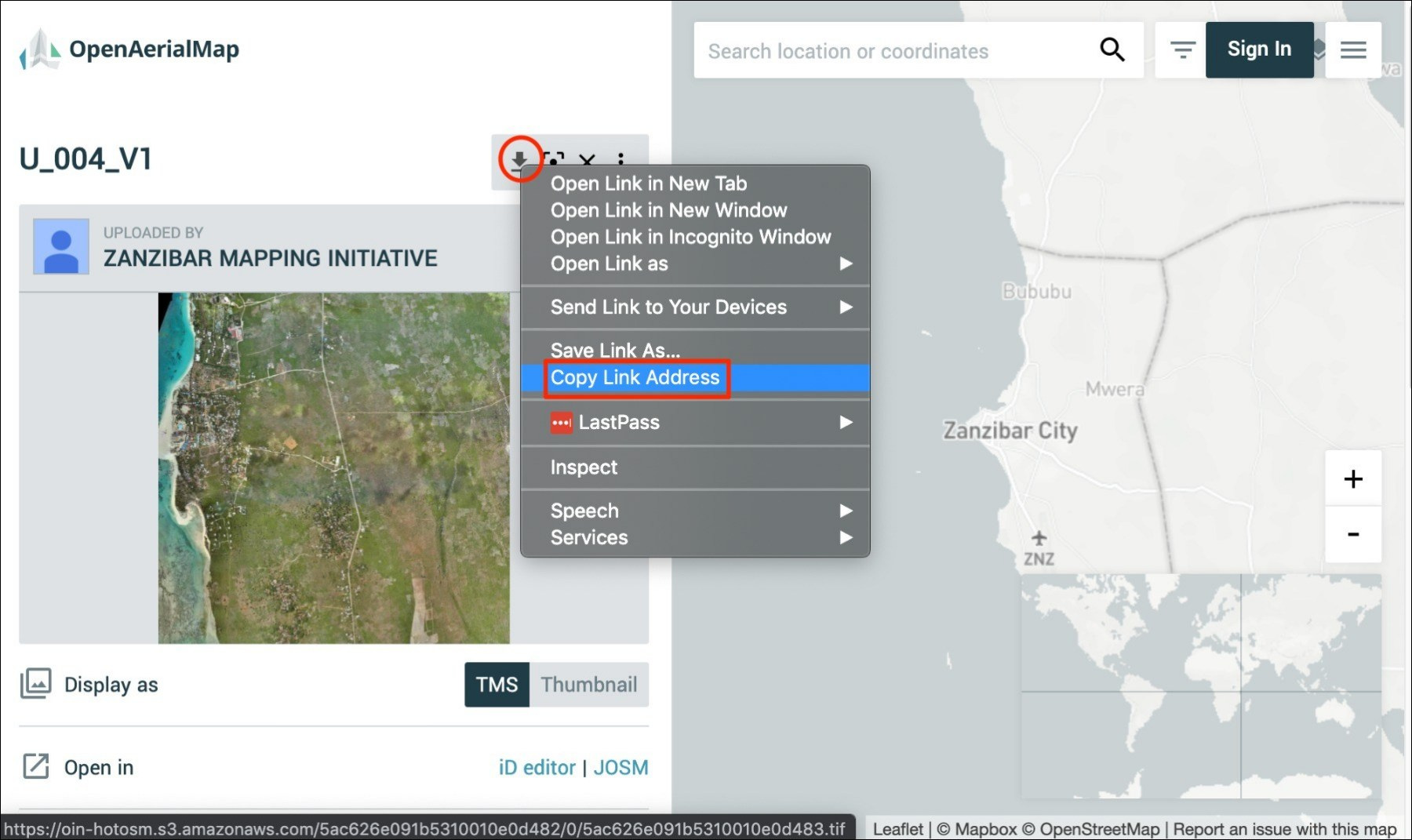
- 在QGIS中,点击Open Data Source Manager,或者使用快捷键
Ctrl+L/Cmd +L。
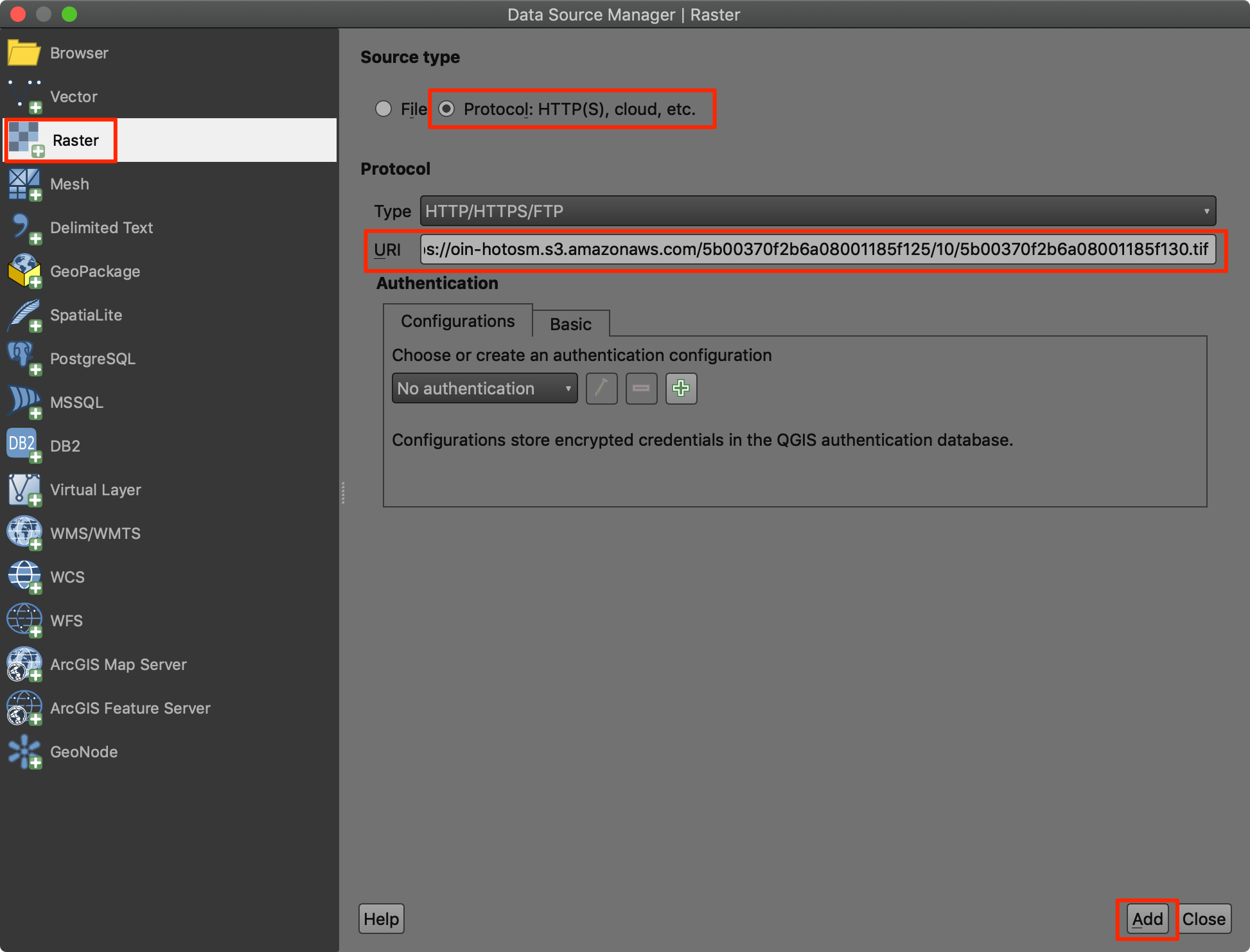
- 切换到栅格Raster标签,然后选中协议
Protocol: HTTP(S), cloud etc.作为数据源Source type。输入刚刚的geotiff链接地址作为URI。然后点击Add添加。
- 初始化下载之后,图像就可以在QGIS中呈现为一个新图层了。要注意每个图像的原始大小可能有几百兆字节,但加载的时候其实只传输了必要的一小部分。
- 使用Identify 工具来点一点图像。你会发现这是一个四通道的无人机图像,四个通道就是红、绿、蓝、明度(Red, Green, Blue, Alpha)。你不仅可以查看图像,还可以查询图像的像素值。这酒喝常规的GeoTIFF格式文件一样。如果你使用的是XYZ切片图层,是绝对无法实现这个效果的。所以一个云优化的GeoTIFF格式提供了这一独一无二的功能,具有这种快速流式访问的独特优势,同时保留了源数据的完全性。
数据来源
- Delhi PM2.5 concentrations. Downloaded from OpenAQ data download service. Source data from Central Pollution Control Board (CPCB) India and EPAAirNow DOC.
- OSM Tile Layer, Bangalore Metro Stations : (c) OpenStreetMap contributors
- India Village-Level Geospatial Socio-Economic Data Set. Meiyappan, P., P. S. Roy, A. Soliman, T. Li, P. Mondal, S. Wang, and A. K. Jain. 2018. India Village-Level Geospatial Socio-Economic Data Set: 1991, 2001. Palisades, NY: NASA Socioeconomic Data and Applications Center (SEDAC). https://doi.org/10.7927/H4CN71ZJ. Accessed 15 February 2020.
- Census 2001 Districts: Downloaded from Datameet Spatial Data repository.
- Oxford Point Cloud. DTM, and DSM. Downloaded from Defra Data Services Platform. Crown Copyright 2019
- Kathmandu University Ground Drone Imagery. Downloaded from OpenAerialMap. Captured by WeRobotics
- Zanzibar Cloud-Optimized GeoTiff and XYZ Layer. Accessed from OpenAerialMap. Commission for Lands (COLA) ; Revolutionary Government of Zanzibar (RGoZ)
- Bangalore Sentinel-2 Imagery. Downloaded from Copernicus Open Access Hub. Copyright European Space Agency - ESA.
- Travel Times for Bangalore. Data retrieved from Uber Movement, (c) 2020 Uber Technologies, Inc., https://movement.uber.com.
- Bangalore Ward Maps Provided by Spatial Data of Municipalities (Maps) Project by Data{Meet}.
- Karnataka Population Grid 2020: Downloaded from WorldPop - School of Geography and Environmental Science, University of Southampton; Department of Geography and Geosciences, University of Louisville; Departement de Geographie, Universite de Namur) and Center for International Earth Science Information Network (CIESIN), Columbia University (2018). Global High Resolution Population Denominators Project - Funded by The Bill and Melinda Gates Foundation (OPP1134076). https://dx.doi.org/10.5258/SOTON/WP00645
- BBMP: List of Parks - wardwise: Downloaded from OpenCity Urban Data Portal by Oorvani Foundation and DataMeet.
授权协议
本课程材料采用知识共享署名-非商业性4.0国际许可协议授权。你可以为任何非商业目的自由使用该材料。请适当注明原作者的名字。
本中文翻译版本禁止商用。
如果你想利用英文原版内容作为商业产品的一部分,需要 联系英文原作者 询问价格和使用条款,获得培训授权,付对应费用。
© 2020 Ujaval Gandhi www.spatialthoughts.com