本文将详细介绍如何使用 LLaMA-Factory 对本地自定义数据进行模型微调,并将微调后的模型导出为 GGUF 格式,最终通过 Ollama 加载运行。整个流程适用于显存有限(如 8GB)的用户,兼顾实用性与可操作性。
一、环境准备
首先创建 Conda 虚拟环境并安装 LLaMA-Factory:
conda create -n llamafactory python=3.12
conda activate llamafactory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bitsandbytes
💡 建议使用清华源加速依赖安装。
bitsandbytes是支持 4-bit 量化训练的关键库。
启动 WebUI:
llamafactory-cli webui
此时可通过浏览器访问 http://127.0.0.1:7860 进入图形化界面。
二、准备自定义数据集
LLaMA-Factory 默认从项目根目录下的 data/ 文件夹加载数据。假设你的路径为:
D:\GitHub\LLaMA-Factory\data
将你的数据文件(例如 test.json)放入该目录。数据格式应为标准指令微调格式,例如:
[
{
"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。",
"input": "",
"output": "细胞理论是生物科学的一个理论……"
}
]
编辑 dataset_info.json
在 data/dataset_info.json 中注册你的数据集。支持两种写法:
写法一(自动映射):
{
"my_dataset": {
"file_name": "test.json"
}
}
此方式默认将 "instruction" 视为 prompt,"output" 视为 response。
写法二(显式指定列名):
{
"my_dataset_explicit": {
"file_name": "test.json",
"columns": {
"prompt": "instruction",
"response": "output"
}
}
}
保存后刷新 WebUI,即可在“数据集”下拉菜单中看到 my_dataset。
三、启动微调训练
在 WebUI 中配置以下关键参数:
- 模型选择:推荐使用
Qwen/Qwen3-1.7B(较小且适合微调) - 量化方式:选择 4-bit (q4) 以降低显存占用
- 对话模板:若使用 Qwen3 的 thinking 模型,建议改用
qwen3-nothink模板,避免思维链干扰微调效果 - Offload 选项:若显存紧张但内存充足,可勾选 “使用 offload”,利用 CPU 辅助训练(速度较慢但可行)
点击“开始训练”,等待完成。
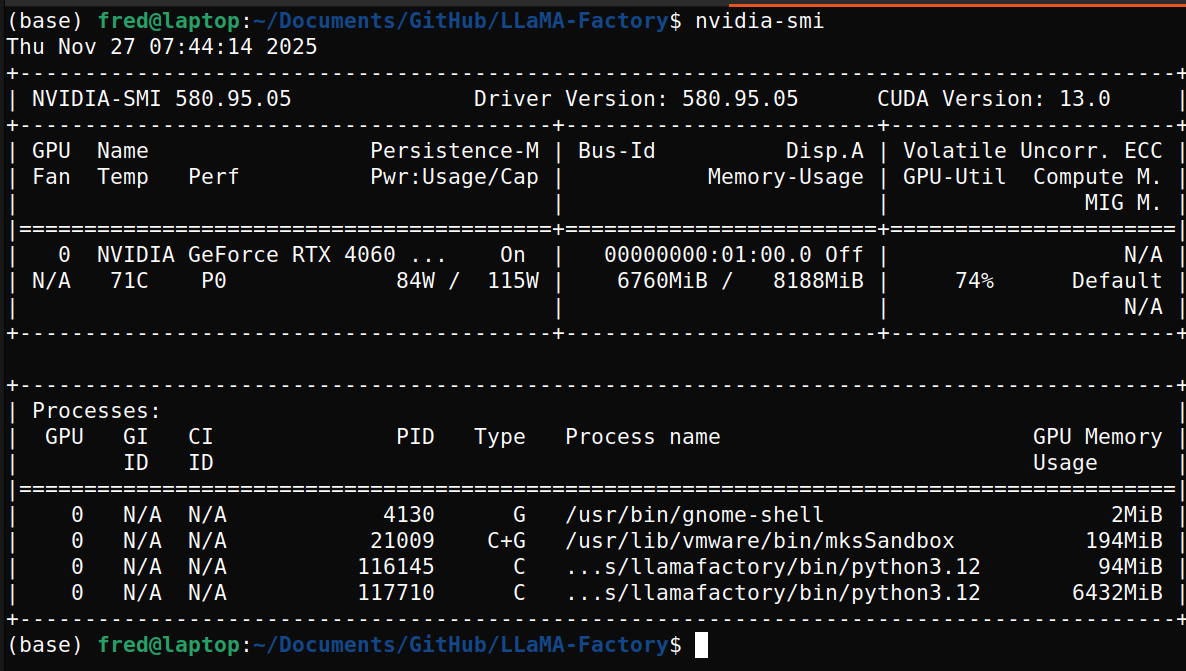
这时候以qwen3:1.7B-thinking为例,q4量化,显存占用在6-7G左右:
训练完成后会出现成功提示。
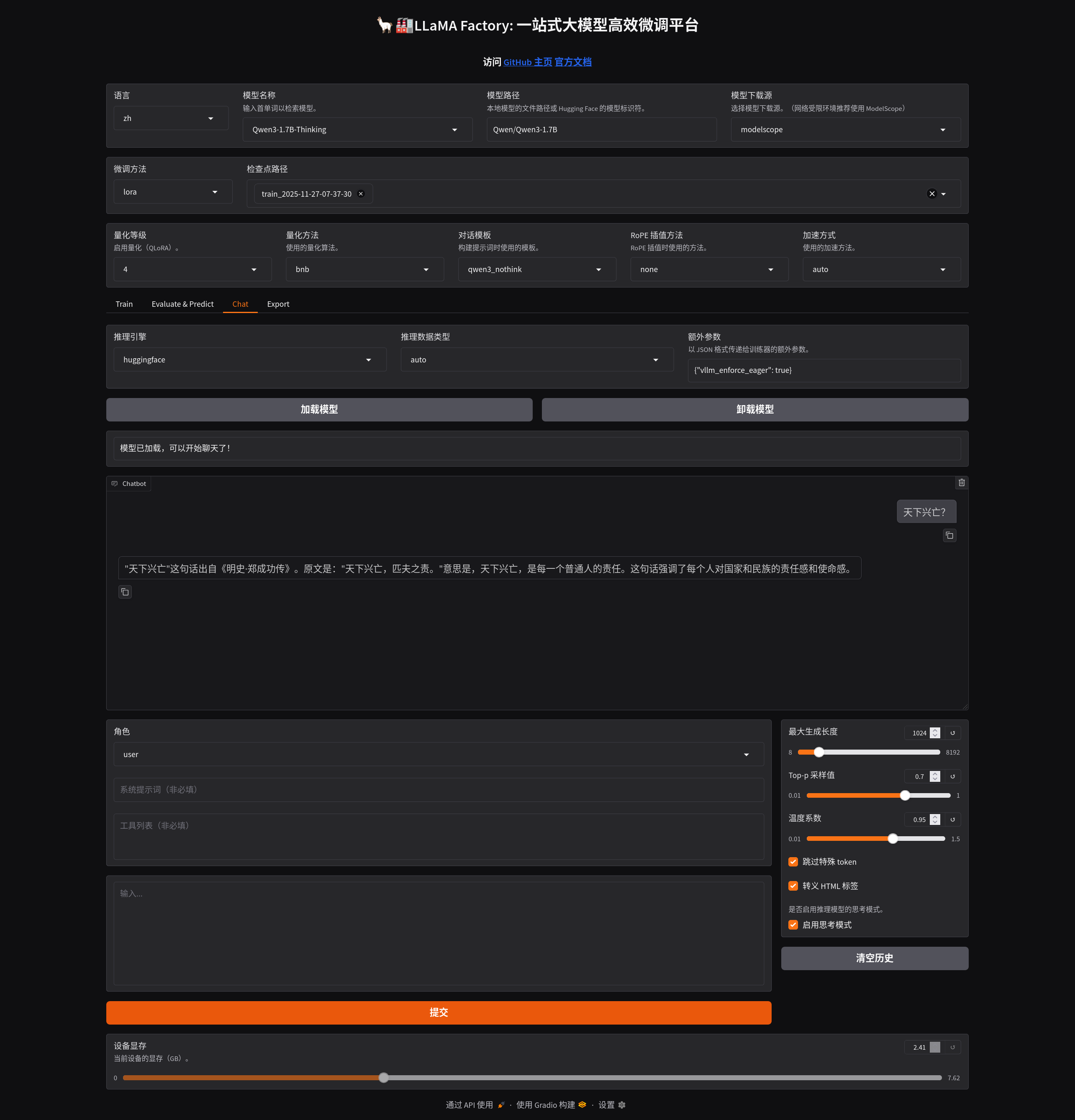
这时候在网页中点击加载模型,就可以对话了,如下图所示:
四、导出微调模型
训练完成后,在 WebUI 的“模型导出”页面:
- 检查点路径:选择刚刚生成的微调模型目录(如
output/checkpoint-xxx) - 输出目录:设为
output(或自定义路径) - 模型类型:务必选择 auto,以确保后续能使用 GPU 推理
具体配置参考下图:
导出成功后,会有如下提示:
output/ 目录将包含如下文件:
added_tokens.json
chat_template.jinja
config.json
generation_config.json
model.safetensors
tokenizer.json
tokenizer_config.json
vocab.json
...
这些是标准的 Hugging Face 格式模型文件。
五、转换为 GGUF 格式(用于 Ollama)
注意,下面的演示步骤过于简略,这样导入到ollama中之后的运行效果其实不如直接在llamafactory的webui中网页运行的效果。
为在 Ollama 中运行,需将模型转为 GGUF 格式。建议使用独立 Python 环境避免依赖冲突:
# 克隆 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
# 安装转换依赖(建议新建虚拟环境)
python -m venv gguf_env
source gguf_env/bin/activate # Windows: gguf_env\Scripts\activate
pip install -r llama.cpp/requirements.txt
执行转换命令(以 q8_0 精度为例):
python llama.cpp/convert_hf_to_gguf.py \
/path/to/LLaMA-Factory/output \
--outfile mymodel.gguf \
--outtype q8_0
✅
q8_0精度较高,适合推理;若需更小体积,可选q4_k_m或q5_k_m。
转换成功后,当前目录将生成 mymodel.gguf。
六、通过 Ollama 加载运行
在模型所在目录(如 output/)创建 Modelfile:
nano tmpmodelfile
内容如下:
FROM ./mymodel.gguf
然后创建 Ollama 模型:
ollama create mymodel -f tmpmodelfile
成功提示:
gathering model components
copying file sha256:... 100%
parsing GGUF
using existing layer ...
writing manifest
success
最后运行模型:
ollama run mymodel
现在你就可以与自己微调过的模型对话了!
注意事项
- 显存不足 优先尝试 1.7B 或 2B 的 Qwen 模型 + 4-bit 量化。
- 训练慢 可关闭
gradient_checkpointing或减少per_device_train_batch_size。 - 效果不佳 确保数据质量高、指令清晰,建议至少准备 100 条以上样本。
- Ollama 无法导入 则要确保 GGUF 文件完整,且 Modelfile 路径正确。
通过以上步骤,就以完成 数据准备 → 微调训练 → 模型导出 → GGUF 转换 → Ollama 部署 的全流程,打造属于自己的专属语言模型!