说实话,这个项目的起因挺简单的。
人过三十天过午,我记忆力一直也不好,平时写课件讲义,经常要查文档,numpy 怎么用、pandas 某个函数的参数是啥、Rust 的所有权又是怎么回事——每次都要开浏览器、搜索、翻页,来回切换窗口。再加上有时候网络不太稳定,或者干脆就是在没网的环境里开发,这就很痛苦了。
后来大模型火了,我试了不少工具,但总觉得哪里不方便。要么得联网用 API,要么没法跟本地文档结合起来,要么就是功能太单一。我想要的其实很简单:一个能在本地跑的、能聊天、能查文档、能跑命令的一体化工具,打开浏览器就能用,不依赖任何云端服务。
于是就有了纲担(GangDan)。
为什么叫"纲担"
取的是"有纲领有担当"的意思。写代码这件事,说到底还是要有条理、有章法。这个名字听着土,但我觉得挺贴切。一个工具嘛,踏踏实实能干活就行,不需要多花哨的名字。
到底能干什么
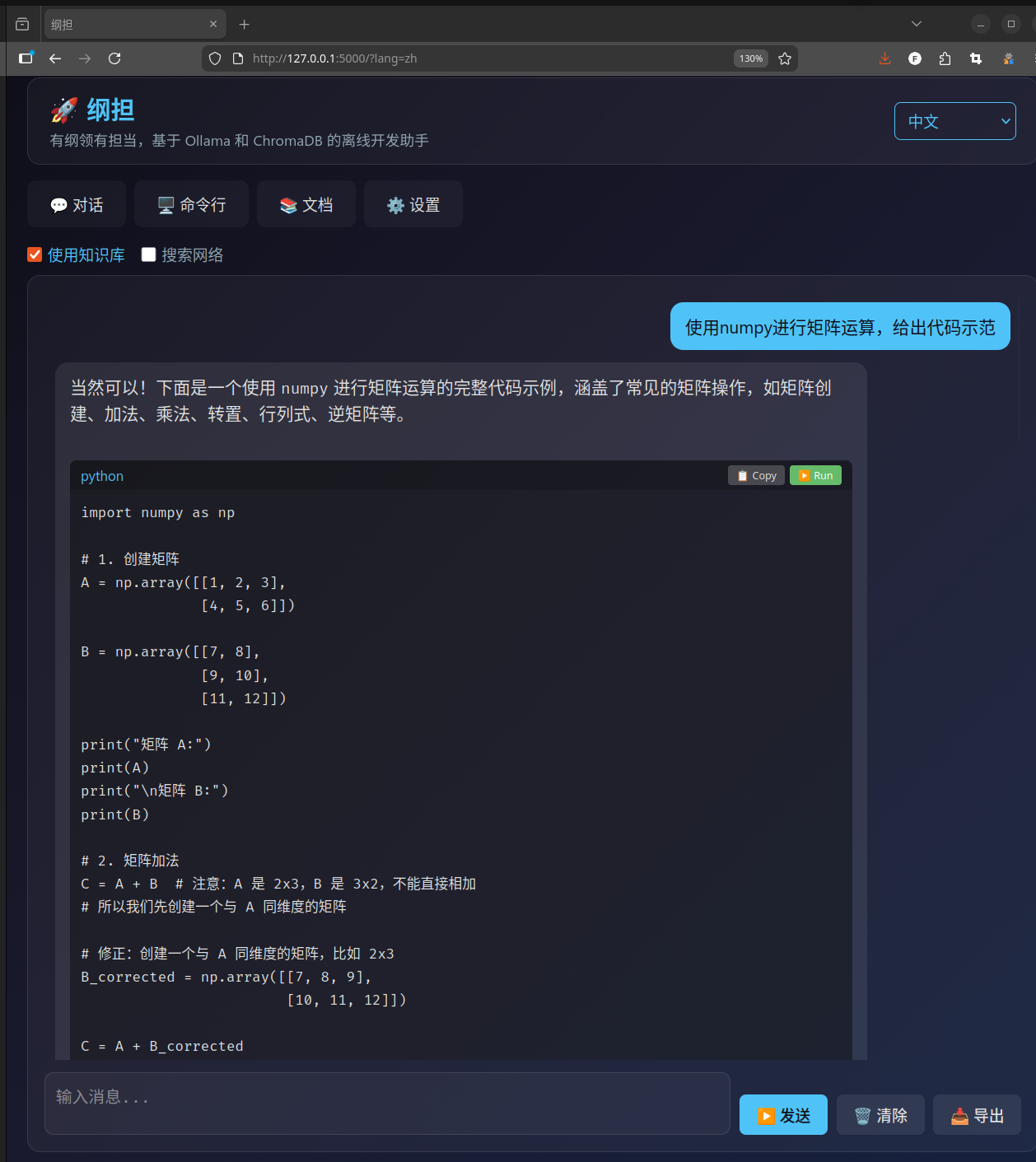
先说最核心的功能——RAG 对话。
简单来说,你可以把各种技术文档下载到本地,纲担会把它们切成小块、生成向量嵌入,存到 ChromaDB 里。之后你问问题的时候,它会先从知识库里检索相关内容,拼到 prompt 里一起发给大模型。这样模型的回答就不是纯靠记忆了,而是有据可依的。
举个例子,你下载了 NumPy 的文档,然后问"怎么用 numpy 创建一个对角矩阵",它会先从文档里找到相关段落,再让模型结合这些内容来回答。比起模型自己瞎编,准确率高不少。
除了本地知识库,它还支持网络搜索。DuckDuckGo、SearXNG、Brave 都能用,搜到的结果也会作为上下文喂给模型。当然,如果你就是想纯离线用,关掉就行。
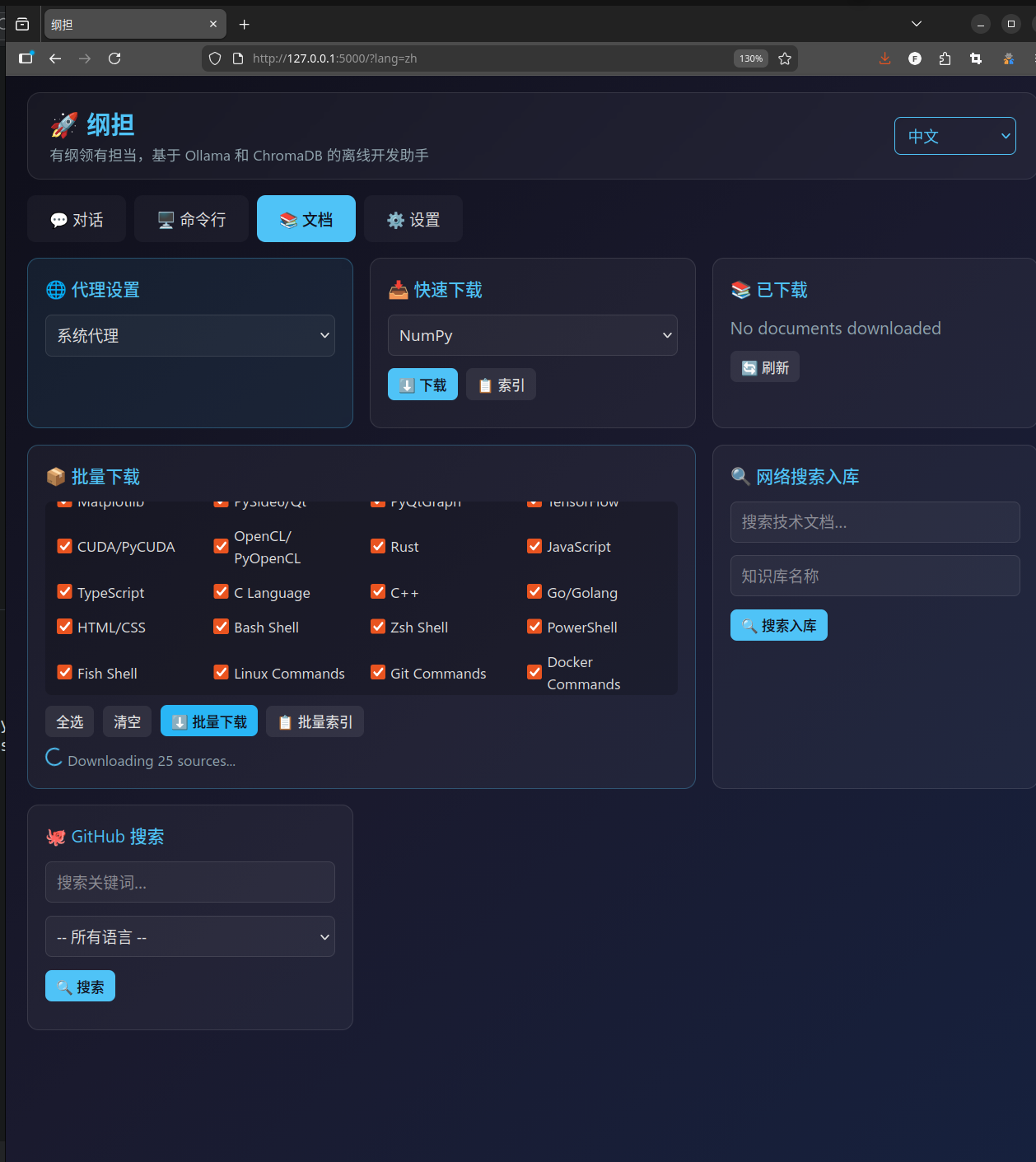
然后是文档管理器。目前内置了多种技术栈的文档源,从 Python 生态的 NumPy、Pandas、SciPy、Scikit-learn、SymPy、Matplotlib、PyTorch、TensorFlow,到 Rust、Go、JavaScript、TypeScript、C/C++,再到 Docker、Kubernetes、各种 Shell——基本上常用的都覆盖了。点一下就能下载,下载完自动切块建索引,不需要你操心。
还有一个我自己特别喜欢的功能:AI 命令助手。你用自然语言描述你想干什么,比如"把当前目录下所有 .py 文件里的 print 替换成 logging.info",它会生成对应的 Shell 命令。生成的命令可以直接拖到旁边的终端里执行,执行完了还会自动总结结果告诉你干了啥。
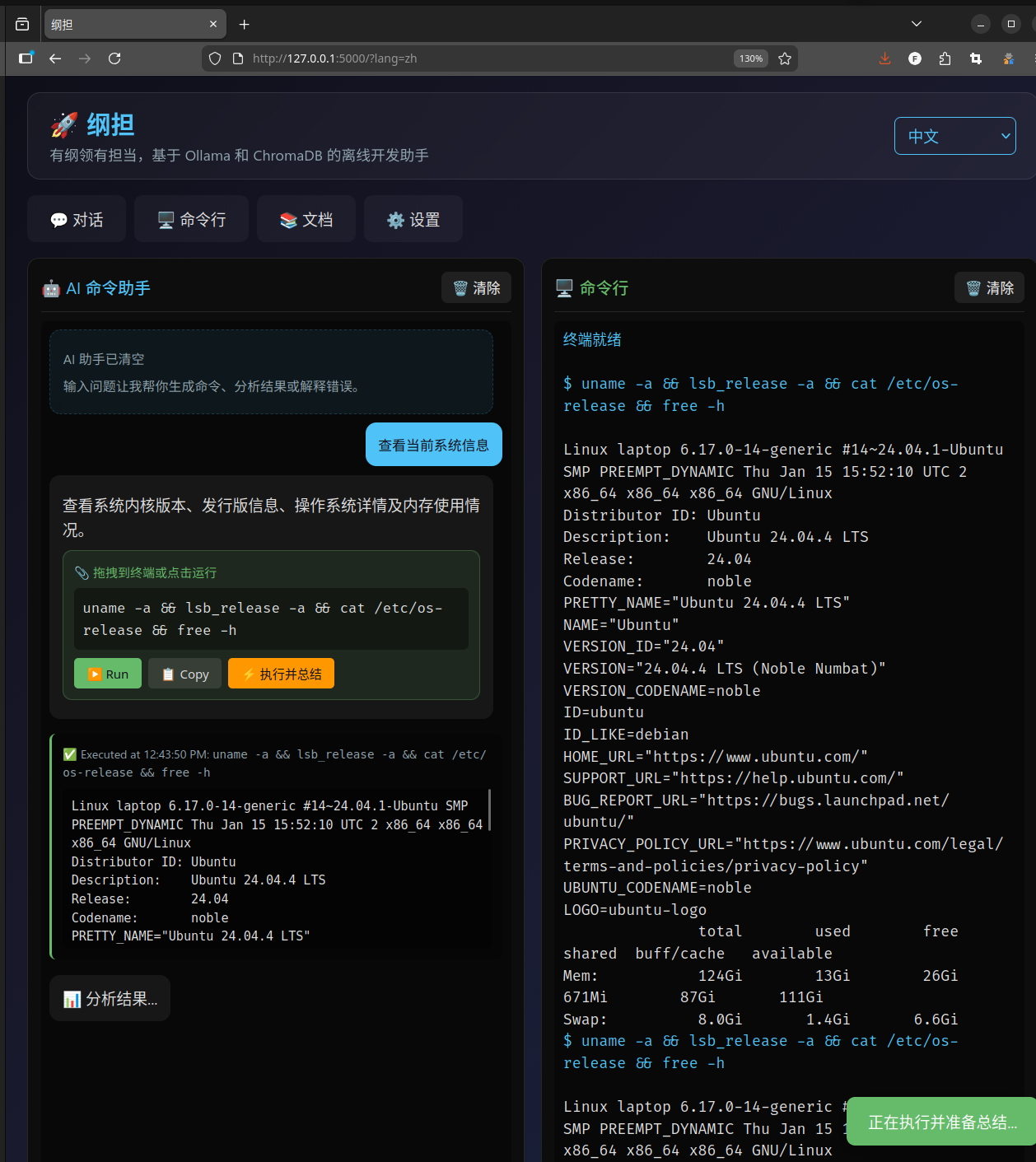
对了,终端也是内置的。不用切到别的窗口,直接在浏览器里就能跑命令,stdout 和 stderr 都会显示出来。虽然比不上一个完整的终端模拟器,但日常用来跑跑脚本、看看输出够用了。
界面还支持 10 种语言切换,中英日法俄德意西葡韩,切换的时候不刷新页面,所有文本即时更新。这个功能实现得比较简洁,前端用一个全局的翻译字典,后端在渲染模板的时候把对应语言的文本注入进去就行。
技术选型的思考
做技术选型的时候我纠结了一阵子。
后端用 Flask,这个没什么好犹豫的。纲担本质上就是一个单用户的本地工具,不需要 Django 那种重量级框架,FastAPI 的异步在这个场景里也没太大必要。Flask 轻,一个文件就能把所有后端逻辑装下,部署也方便。
前端没有用任何框架,纯 HTML + CSS + JavaScript。我知道这在 2026 年听起来有点"原始",但仔细想想,这个应用的前端交互其实不复杂,就是几个面板之间切换、发发请求、渲染一下 Markdown。上 React 或者 Vue 反而增加了构建步骤和依赖,对于一个追求"开箱即用"的离线工具来说,这不是好事。没有 node_modules,没有 webpack,没有 npm run build,clone 下来装上 Python 依赖就能跑,我觉得这是一个优点而不是缺点。
向量数据库选的 ChromaDB。说实话一开始也考虑过 FAISS,但 ChromaDB 用起来更简单,纯 Python,不需要编译,而且支持持久化。对于本地知识库这个场景来说足够了。它有个小问题是数据库偶尔会损坏(尤其是非正常退出的时候),所以我加了一个两级恢复机制:先尝试正常初始化,失败了就自动把损坏的数据库备份到旁边,然后新建一个干净的。用户可能完全感知不到这个过程,但它确实帮你保住了数据。
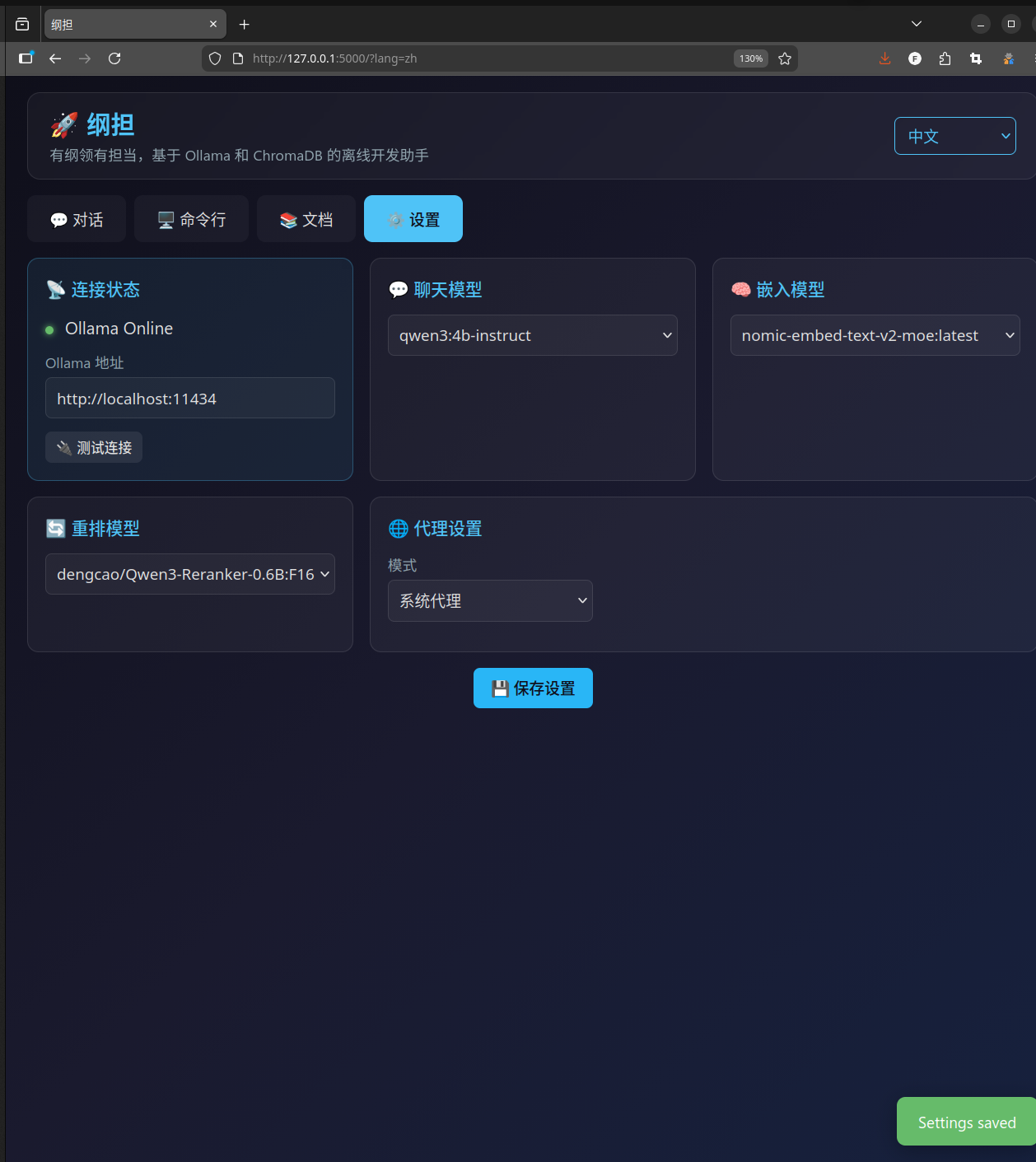
LLM 这边用的是 Ollama。这个选择比较自然,Ollama 是目前本地跑大模型最方便的方案之一,API 跟 OpenAI 格式很像,支持的模型也多。纲担不绑定特定的模型,你装了什么模型它就列出来让你选,聊天模型、嵌入模型、重排序模型都可以分别配置。
整体架构
整个应用就一个 Python 文件加一堆前端资源,但内部还是分了几个清晰的模块。
后端这边,app.py 里有五个核心类:
Config 管配置,用的 dataclass,所有设置项都有默认值,改了之后会自动持久化到一个 JSON 文件里。OllamaClient 负责跟 Ollama 通信,包括模型列表、聊天生成、向量嵌入、重排序。它内部做了连接重试(3 次退避重试),还支持中断生成。ChromaManager 管向量数据库,负责文档的切块、嵌入、存储和检索,前面提到的两级恢复也在这里。DocManager 处理文档下载、格式转换和索引构建。WebSearcher 做网络搜索,目前主要走 DuckDuckGo。
前端这边,JavaScript 按功能拆成了 7 个文件:i18n 管多语言、utils 管面板切换和提示、chat 管聊天逻辑和 SSE 流式输出、terminal 管终端和 AI 命令、docs 管文档下载、settings 管设置面板、markdown 管渲染。它们之间通过全局函数共享状态,加载顺序是固定的。
前后端完全解耦。后端通过 window.SERVER_CONFIG 把初始配置注入到 HTML 模板里,之后所有交互都走 API。聊天用的是 SSE(Server-Sent Events)做流式输出,打一个字就推一个字,体验跟 ChatGPT 差不多。
怎么装
说了这么多,聊聊怎么把它跑起来。
最简单的方式是直接 pip 装:
pip install gangdan
装完之后命令行里就多了一个 gangdan 命令,直接敲就能启动:
gangdan
浏览器打开 http://127.0.0.1:5000 就能用了。
如果你想指定端口或者绑定地址,可以加参数:
gangdan --host 127.0.0.1 --port 8080
数据默认存在 ~/.gangdan/ 下面,如果你想放到别的地方,也可以指定:
gangdan --data-dir /your/path/here
如果你想折腾源码,或者参与开发,那就从 GitHub 克隆:
git clone https://github.com/cycleuser/GangDan.git
cd GangDan
建议搞一个虚拟环境,这样不会污染系统的 Python:
python -m venv .venv
source .venv/bin/activate
Windows 用户激活虚拟环境的命令不太一样:
.venv\Scripts\activate
然后以开发模式安装:
pip install -e .
这样装的好处是你改了代码之后不需要重新安装,直接就能生效。
不管用哪种方式安装,都得先把 Ollama 装好。去 ollama.ai 下载安装,然后拉几个模型:
ollama serve
ollama pull qwen3:4b
ollama pull nomic-embed-text
第一个是聊天模型,第二个是嵌入模型(用来做 RAG 检索的)。模型可以换成你喜欢的,纲担会自动列出你本地装了哪些模型,在设置里选就行。
一些设计细节
有几个设计上的细节,我觉得值得聊聊。
第一个是数据目录的处理。纲担会根据安装方式自动选择数据目录:如果是通过 pip 安装的(代码在 site-packages 里),数据就放在用户主目录的 ~/.gangdan/ 下;如果是直接从源码跑的(开发模式),数据就放在项目根目录的 ./data/ 下。这个判断逻辑很简单,就看一下当前包的路径里有没有 site-packages,但效果很好,用户完全不需要关心这个问题。
第二个是文档的处理流程。下载回来的文档格式五花八门,有 .rst、.md、.py、.html、.ipynb,纲担会统一转成 Markdown 格式存储。然后切块的时候,每块大约 800 个字符,相邻两块有 150 个字符的重叠。这个重叠很重要,能保证检索的时候不会因为恰好在边界处被切断而丢掉关键信息。
第三个是代理支持。做这个功能是因为有些环境下需要通过代理才能访问某些网站,下载文档和网络搜索都需要。纲担提供了三种模式:不用代理、跟随系统环境变量、手动指定。这个在界面里就能切换,改完立刻生效,不需要重启。
第四个是 Ollama 客户端的健壮性。跟 Ollama 通信的 HTTP 请求全部走 Session,配了 3 次指数退避重试,针对 429、500、502、503、504 这几个状态码。这样万一 Ollama 正在忙或者暂时没响应,不会直接报错,而是会自动重试。聊天生成还支持中途中断,点停止按钮就能立刻终止流式输出。
最后
纲担现在还在持续开发中。我自己每天都在用它修改课件讲义之类的,遇到问题就顺手改改。它不是一个完美的工具,但对我来说确实解决了一个实际问题:在一个浏览器标签页里,把 AI 对话、文档检索、命令执行这几件事整合到一起,而且完全不依赖外部服务。
如果你也有类似的需求,不妨试试。
源码在 GitHub 上,GPL-3.0-or-later 许可证,随便折腾。
https://github.com/cycleuser/GangDan