滤波,在最广泛的意义上,是从含噪声的观测序列中估计感兴趣信号的过程。这个概念横跨信号处理、控制理论、时间序列分析和统计学,但核心目标高度统一:从杂乱无章的测量值里还原出隐藏其后的真实状态或趋势。
在进入具体的滤波方法之前,需要先建立几个基本概念。
随机变量与期望
随机变量是取值不确定的量。它的期望值 刻画了"平均来说会取到什么值"。当样本量逐渐增大时,样本均值会收敛到期望值——这是大数定律告诉我们的。
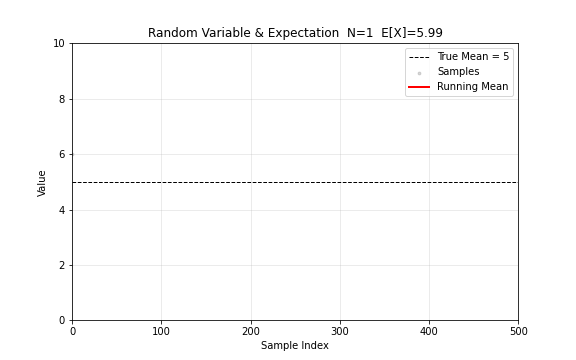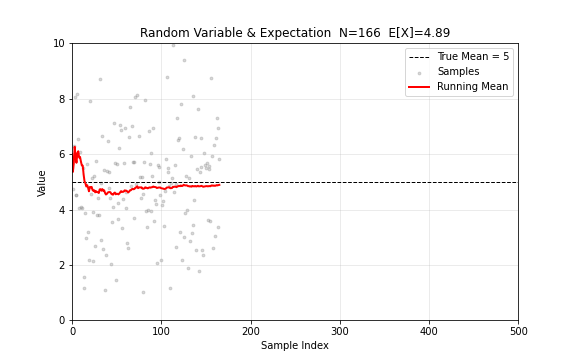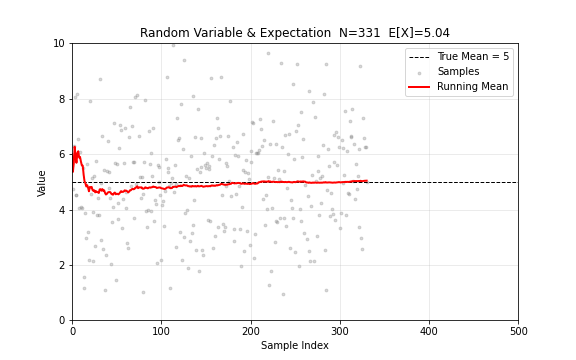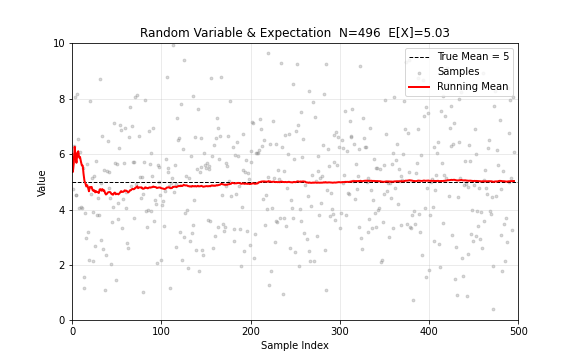
图 1. 随机变量与期望。从 中逐步采样,灰色点为样本值,红色线为累计均值,最终收敛到 。
方差与协方差
方差衡量单个随机变量的离散程度——偏离均值的幅度有多大。协方差更进一步,衡量两个随机变量之间是否同步变化。关键在于协方差要求两个变量是成对观测的:对同一个索引 ,我们同时记录了 和 。
如果 大于均值时 也倾向于大于均值,乘积为正,协方差为正——正相关;若方向相反则为负相关;若无同步趋势,正负乘积互相抵消,协方差趋近于零。
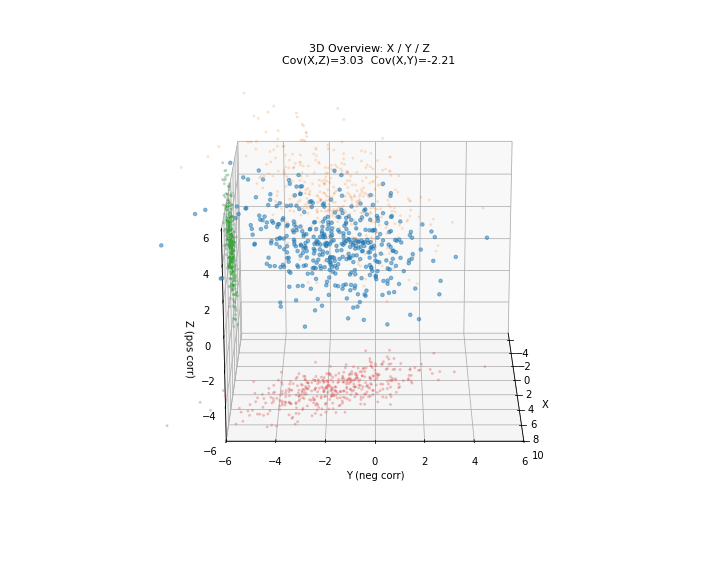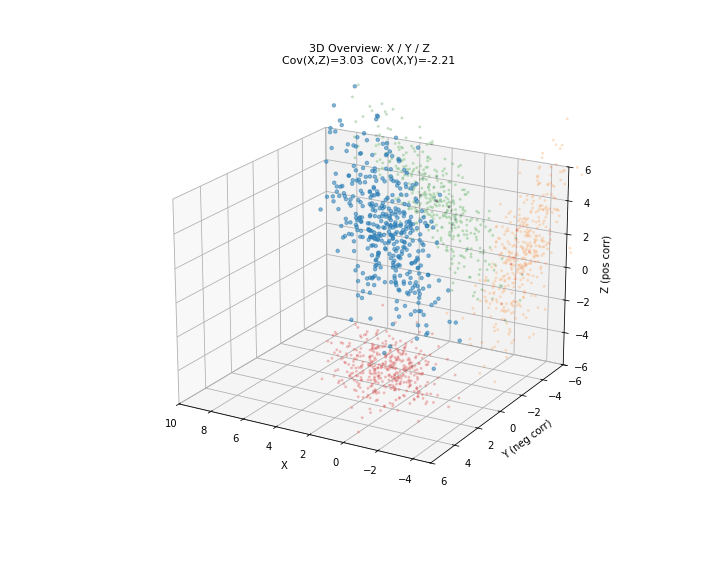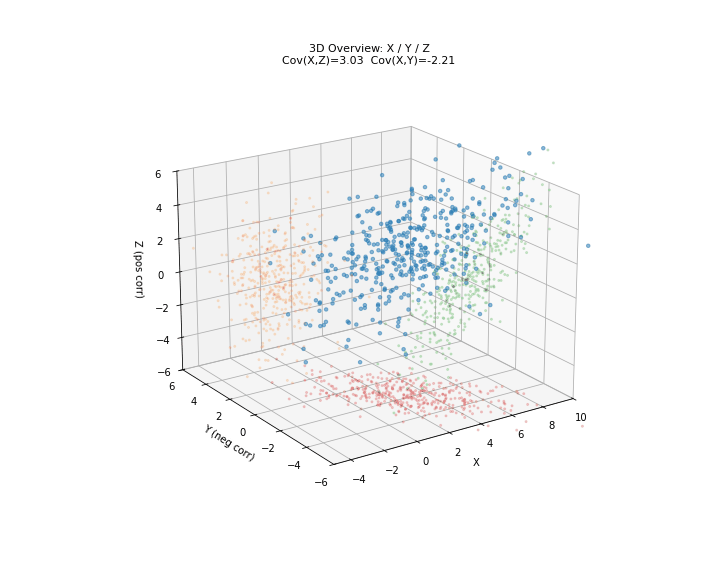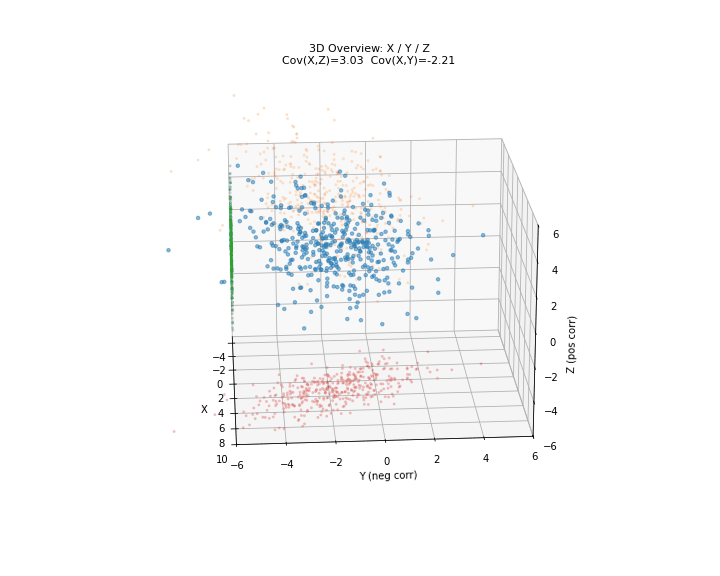
图 2. 协方差三维总览。X 轴为共享自变量,Y 轴为与 X 负相关的变量,Z 轴为与 X 正相关的变量。红色投影至 X-Y 平面,绿色投影至 X-Z 平面,橙色投影至 Y-Z 平面。
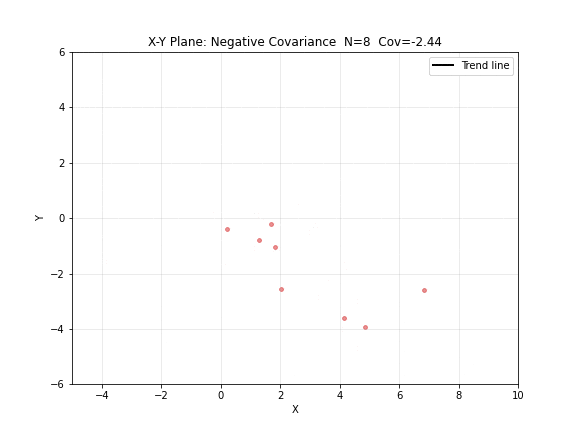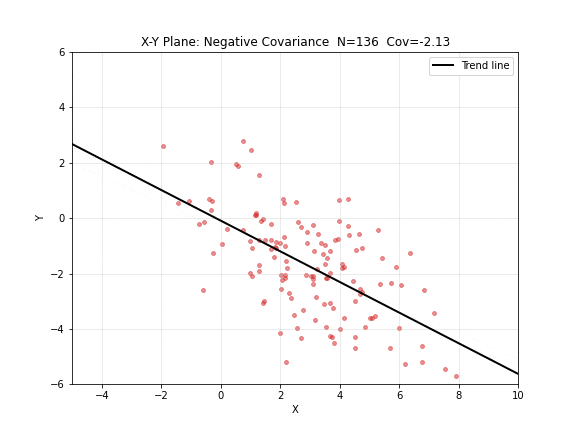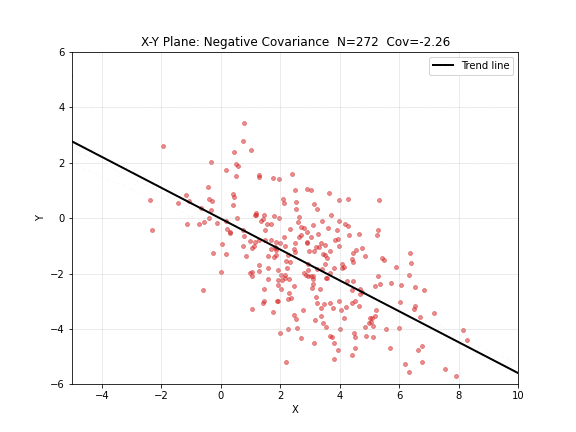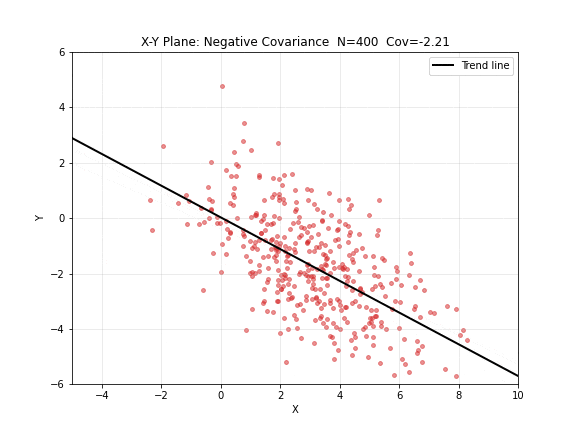
图 3. X-Y 平面:负协方差逐步构建。红点 为成对观测,黑色趋势线斜率为负—— 增大时 倾向于减小。
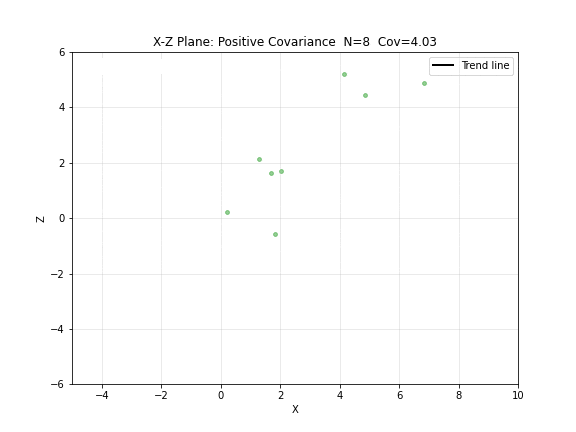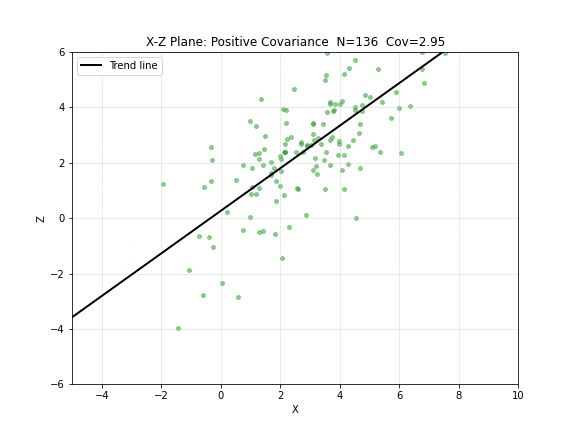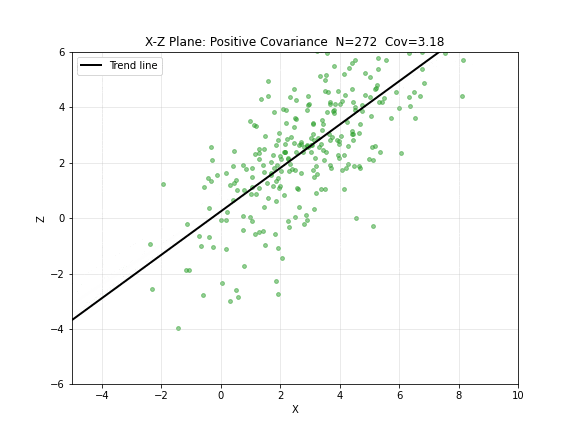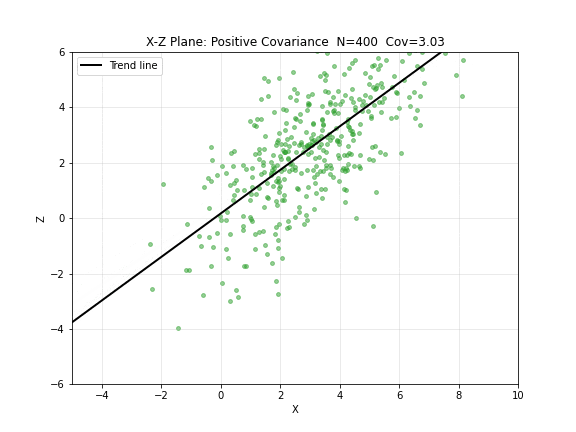
图 4. X-Z 平面:正协方差逐步构建。绿点 为成对观测,趋势线斜率为正—— 增大时 也倾向于增大。
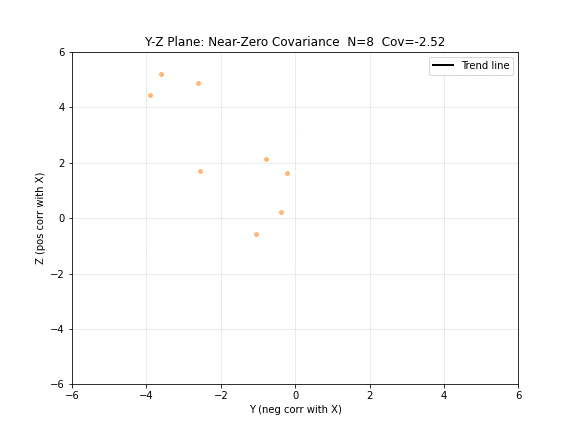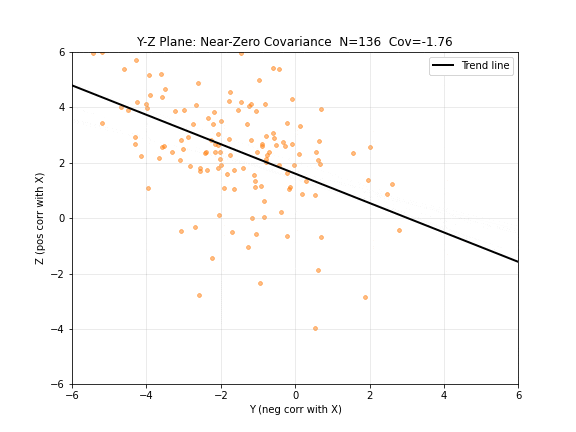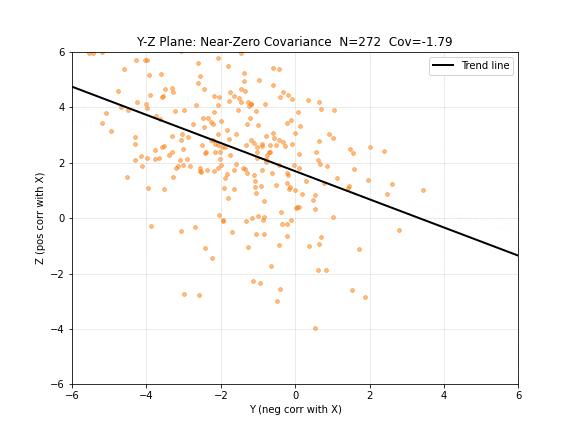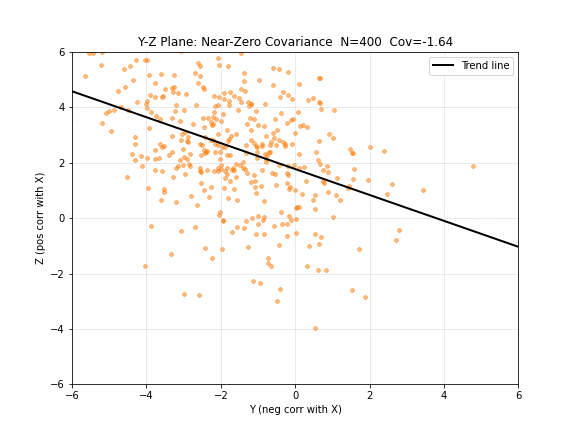
图 5. Y-Z 平面:协方差接近零。尽管 与 负相关、 与 正相关,但 和 之间却没有直接的线性关系——趋势线几乎水平。这说明协方差只反映线性相关性,两个变量可以分别与第三个变量相关但彼此不相关。
协方差矩阵
对于 维随机向量,协方差矩阵 是一个 矩阵,第 元素为 。对角元素是各分量自身的方差,非对角元素是分量之间的协方差。协方差矩阵是对称半正定的,完整描述了随机向量的二阶统计特性。在卡尔曼滤波中,每一个状态估计 都伴随一个误差协方差矩阵 ——它量化了"我们对当前估计有多不确定"。
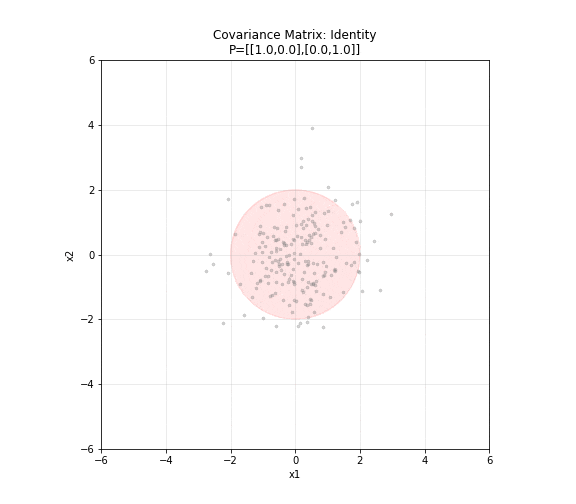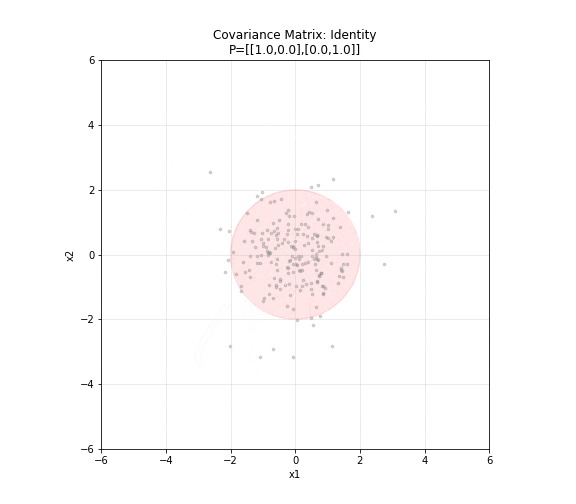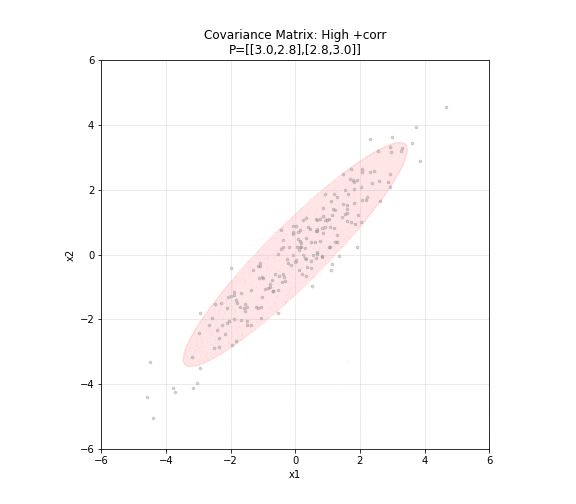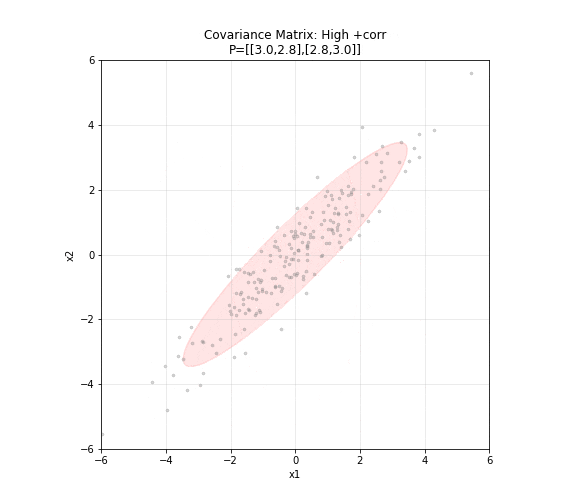
图 6. 协方差矩阵的几何意义。五种不同的协方差矩阵对应五种不同形状的二维高斯分布。对角矩阵产生圆形分布,非对角元素非零时椭圆倾斜,方差大的方向椭圆更长。红色椭圆为 2σ 置信区域。
高斯分布
高斯分布的概率密度函数为熟悉的钟形曲线:。多维形式记作 。
高斯分布在卡尔曼滤波中的核心地位来自两条关键性质。第一,高斯分布经过线性变换后仍然是高斯分布——若 ,则 。第二,两个高斯分布的乘积归一化后仍是高斯分布。预测步对应线性变换(保持高斯性质),更新步对应先验与似然的乘积(保持高斯性质)。这两个性质加在一起,意味着卡尔曼滤波器永远不需要离开高斯分布的框架。
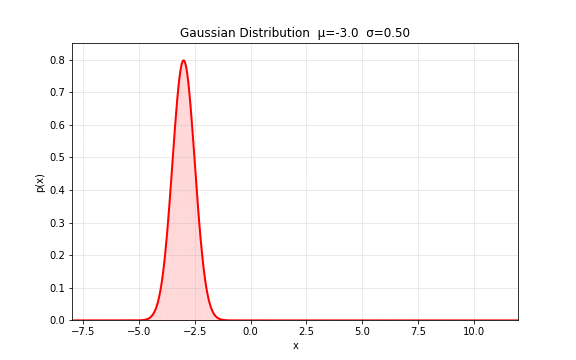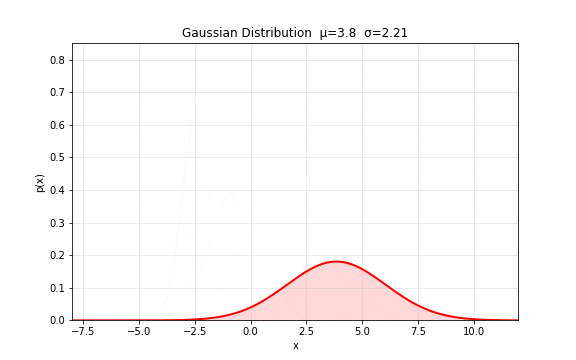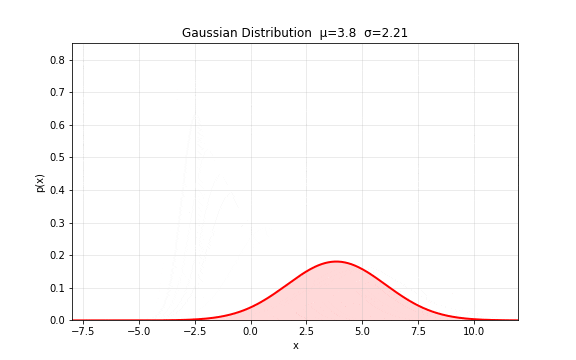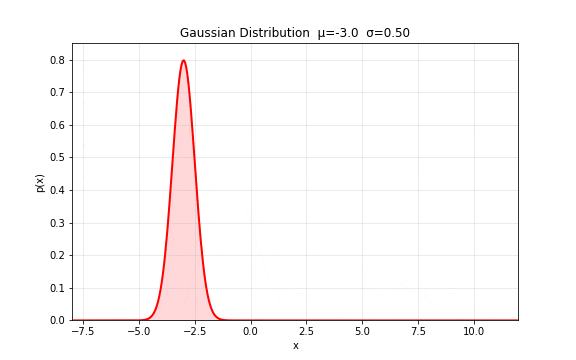
图 7. 高斯分布的基本形状。 控制中心位置(左右平移), 控制分布宽度(胖瘦),曲线下总面积始终为 1。
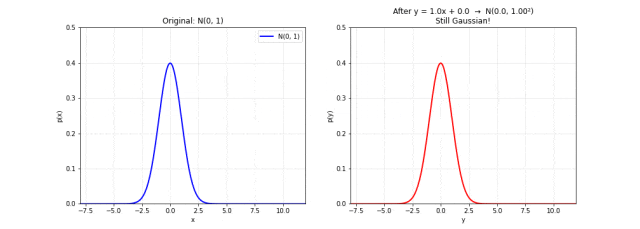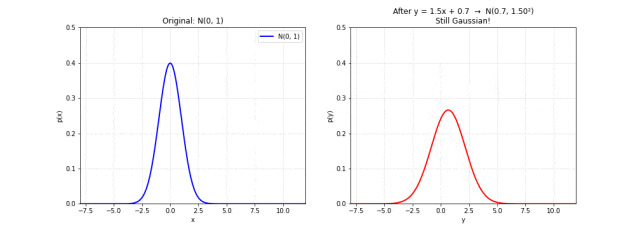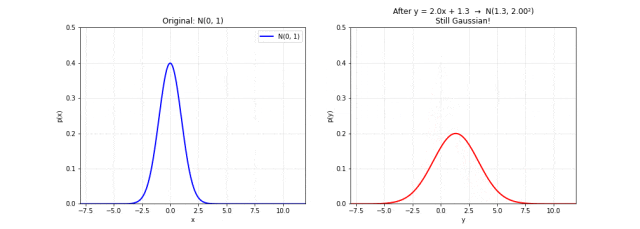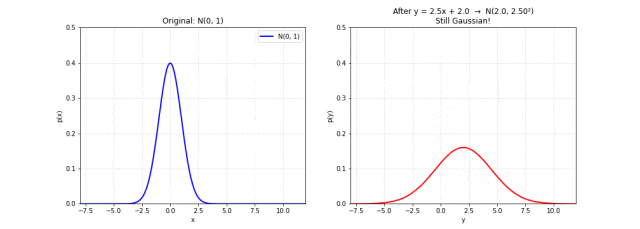
图 8. 线性变换保持高斯性质。左图为原始 ,右图是经过 变换后的分布。随着参数变化,钟形曲线变宽或变窄、左右移动,但始终保持高斯形状。
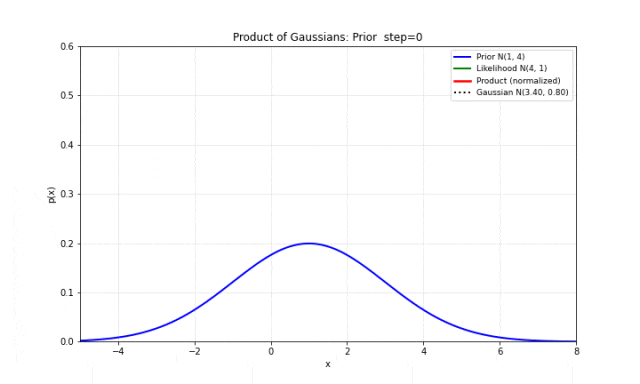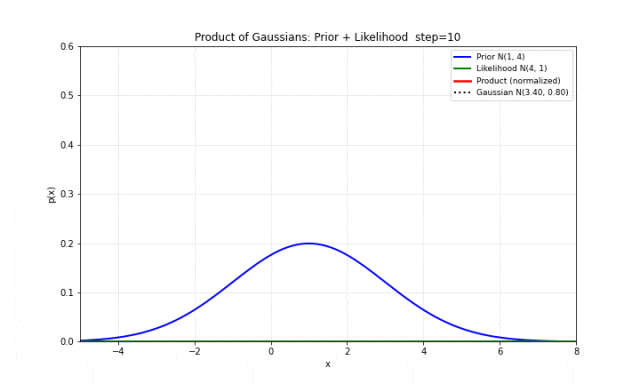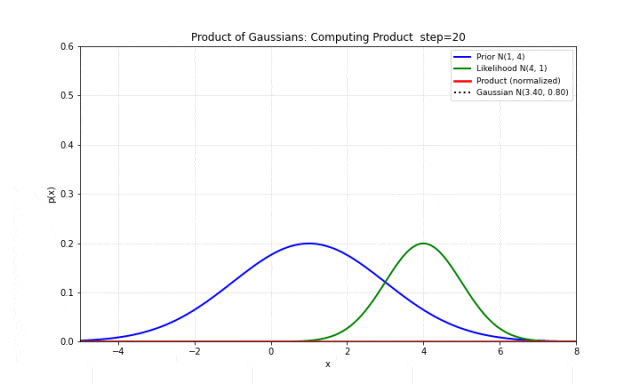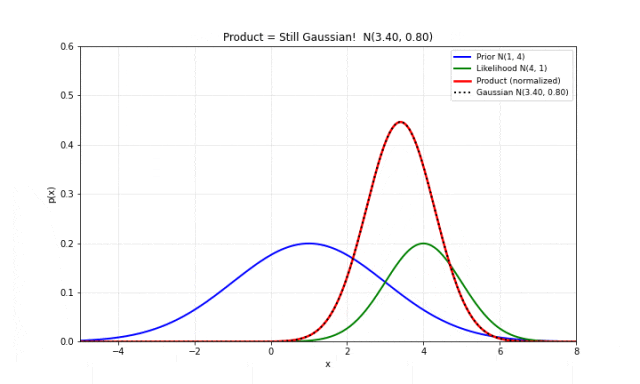
图 9. 两个高斯分布的乘积。蓝色是先验 ,绿色是似然 ,红色是乘积(归一化后),黑色点线是高斯拟合。两者完美重合,证明乘积仍然是高斯分布。注意乘积的方差比两者都小——这意味着融合两个信息源之后,不确定性减小了。
傅里叶变换
傅里叶变换的核心思想可以用一句话概括:任何信号都可以拆成一系列正弦波的叠加。每个正弦波有固定的频率和振幅——傅里叶变换就是找出这些频率分量各有多强。
离散傅里叶变换(DFT)的公式为 。直观来说,对每个频率 ,把信号和该频率的正弦波做内积,结果 就是该频率分量的强度。维纳滤波在频域中设计最优滤波器,需要用到傅里叶变换。
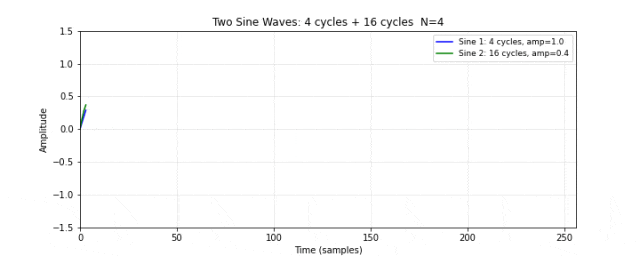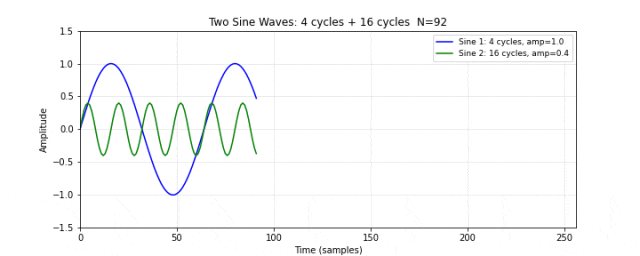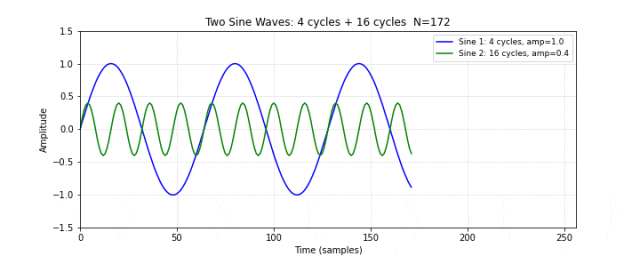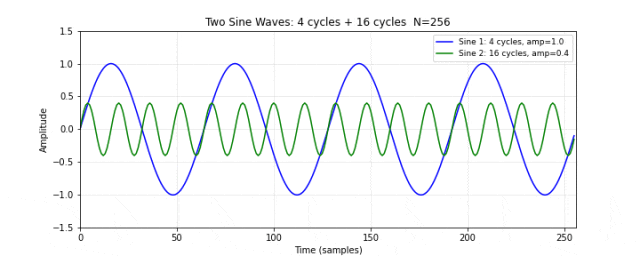
图 10. 两个独立的正弦波。蓝色为低频波(4 个周期,振幅 1.0),绿色为高频波(16 个周期,振幅 0.4)。
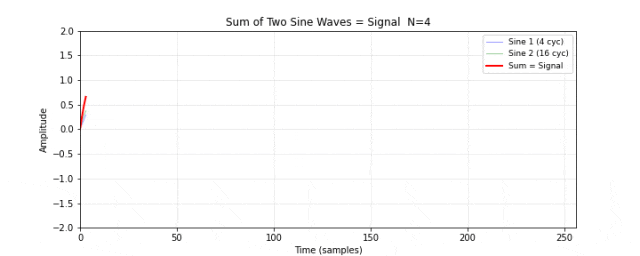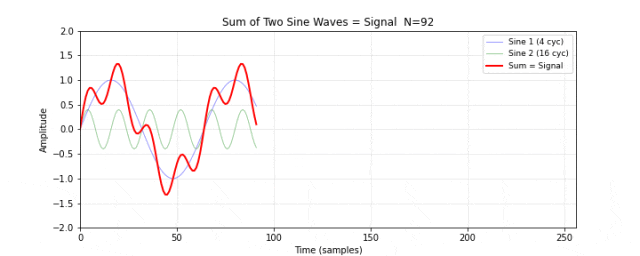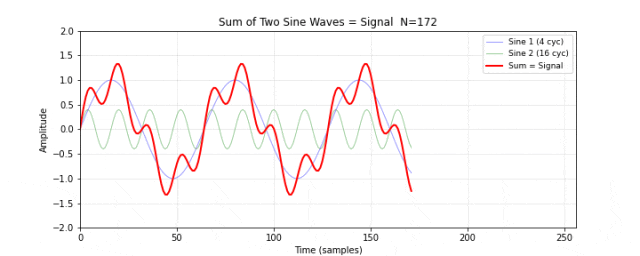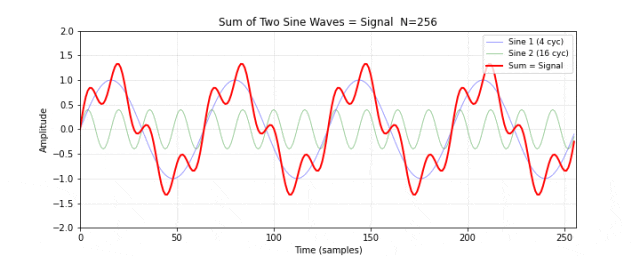
图 11. 合成信号。将图 10 的两个正弦波逐点相加,得到一个看起来不太规则的信号(红色粗线)。两个频率分量在时域上混合在一起,肉眼很难分辨出各自的存在。
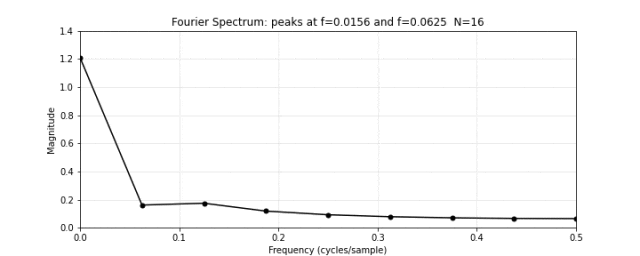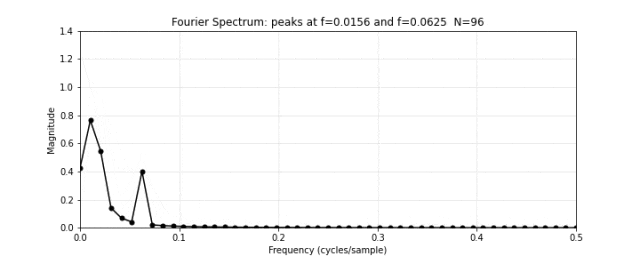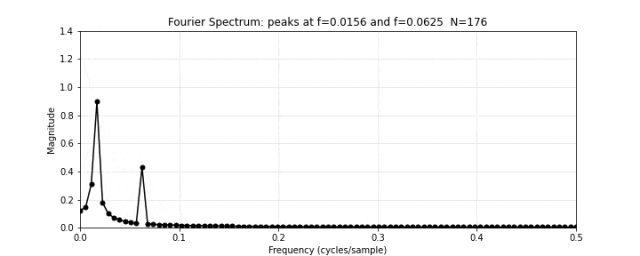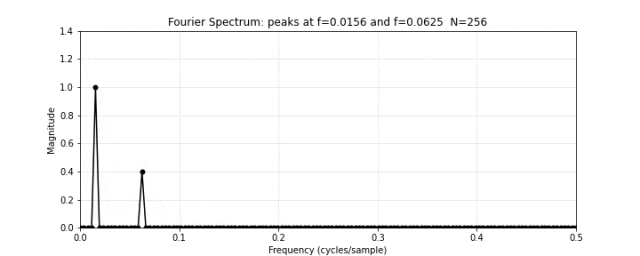
图 12. 傅里叶频谱。对图 11 的合成信号做傅里叶变换,频谱在频率 4 和 16 处出现两个尖锐的峰值。低频峰值对应振幅 1.0(高),高频峰值对应振幅 0.4(低)——精确匹配了图 10 中的两个原始频率分量。傅里叶变换把混合信号"拆"回了它本来的组成部分。
Python 工具
本系列涉及的主要 Python 库和运算:
import numpy as np
# 矩阵运算
C = A @ B; At = A.T; Ainv = np.linalg.inv(A)
vals, vecs = np.linalg.eigh(P) # 对称矩阵特征值分解
L = np.linalg.cholesky(P) # Cholesky 分解
w = np.random.multivariate_normal(mu, cov) # 多元高斯采样
# 信号处理
est = np.convolve(obs, np.ones(W)/W, mode='same') # 卷积
X = np.fft.rfft(x); x = np.fft.irfft(X, n=N) # 傅里叶正逆变换
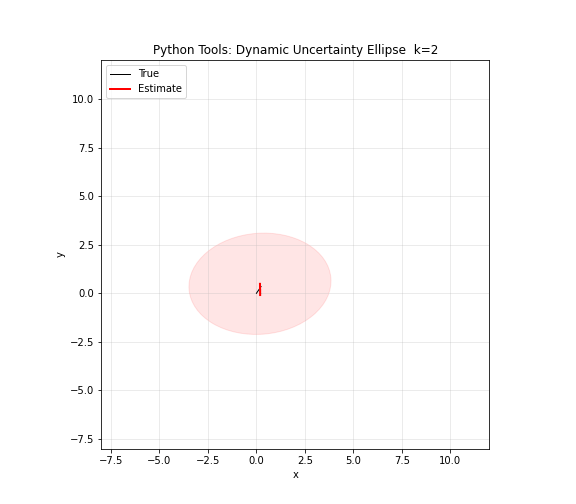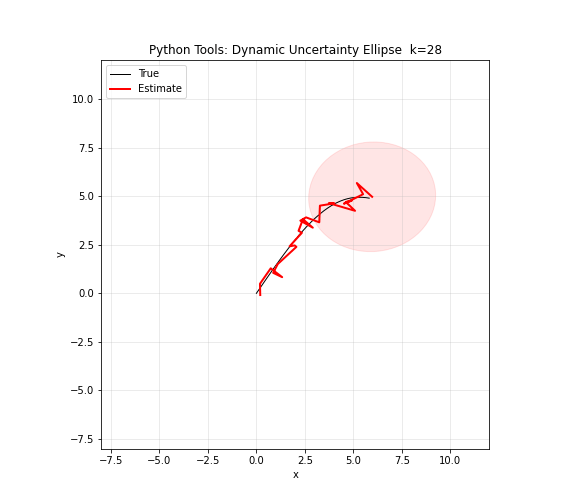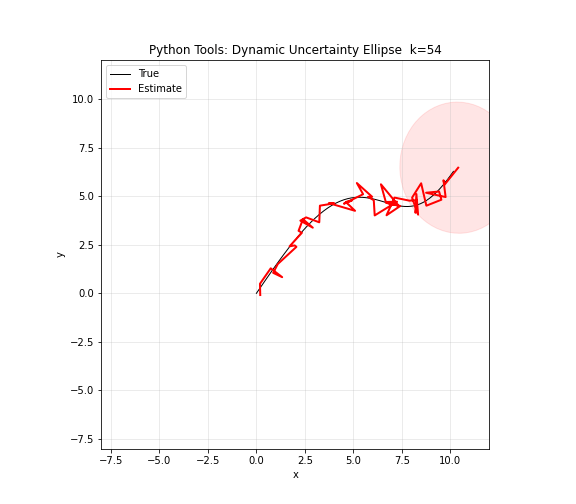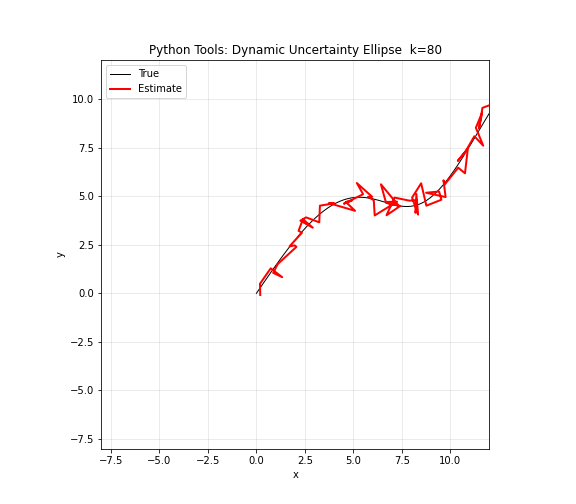
图 13. Python 工具综合演示。NumPy 生成模拟曲线数据,矩阵运算计算协方差,Matplotlib 绘制轨迹和散点,Ellipse 绘制不确定性椭圆。红色椭圆的大小、形状和旋转角度随位置和时间动态变化——这正是卡尔曼滤波器每个时刻输出的可视化:不仅有状态估计,还有估计的不确定性。
一、移动平均滤波
有了期望和方差的直观概念之后,最简单的滤波想法就是取平均——用多次观测的均值代替单次含噪声的读数,自然更接近真实值。
移动平均的公式极其简洁:。唯一的参数是窗口宽度 。 选大了,输出平滑但滞后于真实变化; 选小了,反应快但残留噪声多。这种平滑度与响应速度之间的基本权衡,贯穿此后所有的滤波方法。
从频域看,移动平均是一个有限脉冲响应(FIR)滤波器,频率响应 。 是 Dirichlet 核,在主瓣之外有衰减旁瓣——所以它抑制高频噪声的同时会引入振铃。
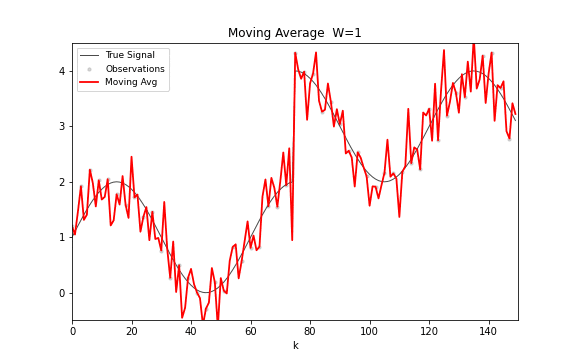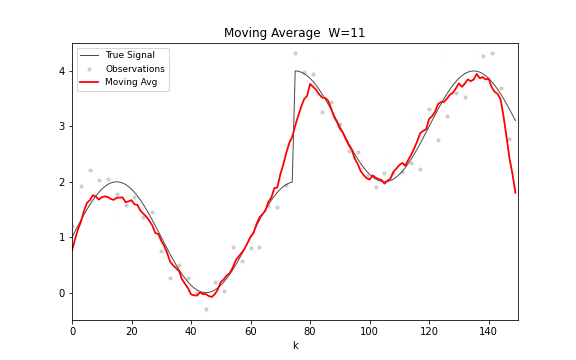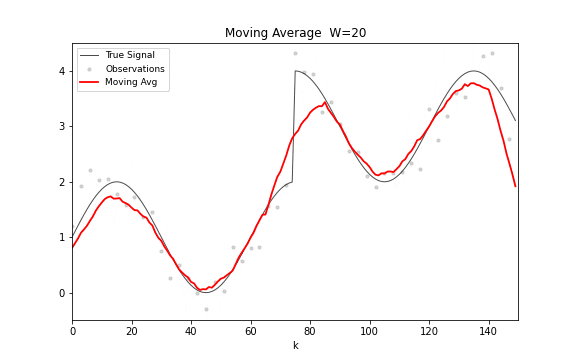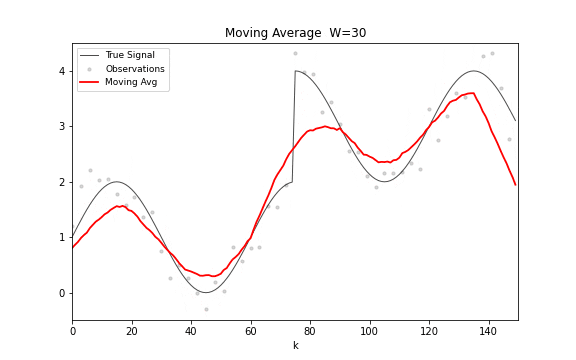
图 14. 移动平均滤波。窗口宽度从 1 逐步增加到 30,滤波输出从小锯齿到大平滑的变化清晰可见。窗口越宽,曲线越平滑,但响应阶跃变化的速度也越慢。
import numpy as np
def moving_average(obs, window):
return np.convolve(obs, np.ones(window) / window, mode='same')
移动平均的局限很明显。窗口内所有观测权重相等,没有理由认为一个月前的数据和昨天的数据同样重要;需要存储整个窗口的历史数据;对趋势信号的跟踪天然滞后。这三个局限中,前两个可以在不牺牲简洁性的前提下同时解决——这就是指数平滑。
二、指数平滑滤波
移动平均给窗口内每个观测相等的权重 ,窗口外的权重为零——这是一个矩形窗。指数平滑把这个矩形权重函数换成指数衰减的权重:越近的观测权重越大,越远的观测权重越小,衰减到无穷远。最关键的是,这个加权不需要存储整段历史。
递推公式极其优雅:。将其展开可以清楚地看到指数衰减的权重结构:。参数 是平滑因子:接近 1 则紧密追踪新数据,接近 0 则强平滑旧趋势。
指数平滑在频域上是一个单极点低通滤波器,幅度响应 。与移动平均的多旁瓣结构完全不同,指数平滑的幅频曲线是平滑衰减的单峰,没有振铃效应。它在时间序列预测中被广泛使用——Holt-Winters 方法就是它的多参数推广。
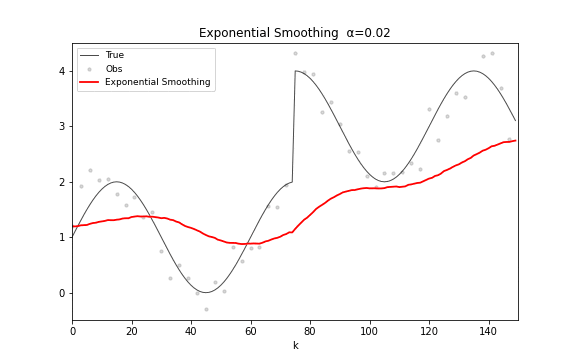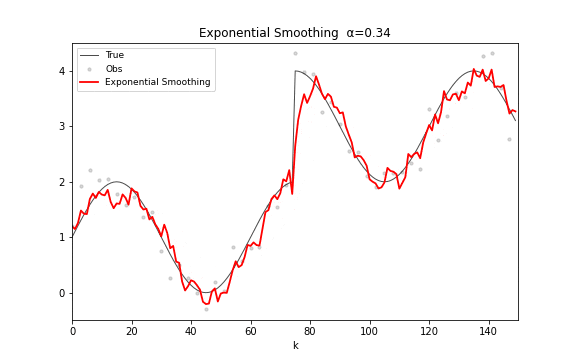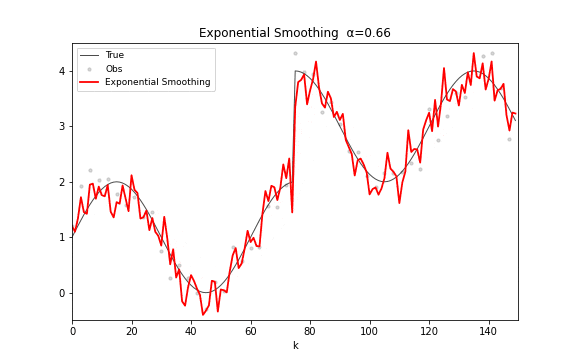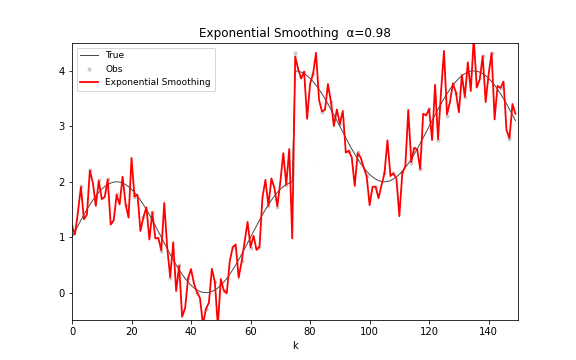
图 15. 指数平滑滤波。 从 0.02 连续变化到 0.98——左端几乎是水平线(极度平滑),右端几乎贴着观测点走(紧密追踪)。寻找合适的 就是在平滑度和反应速度之间折中。
import numpy as np
def exponential_smoothing(obs, alpha):
est = np.zeros_like(obs); est[0] = obs[0]
for k in range(1, len(obs)):
est[k] = alpha * obs[k] + (1 - alpha) * est[k-1]
return est
与移动平均相比,指数平滑在权重分配和存储效率上有了实质性进步。但它和移动平均共享同一个根本缺陷:它们都是单变量滤波器,只能处理标量信号,无法处理具有内部动力学的多维系统。当我们不仅需要估计当前位置,还需要估计速度、加速度等多个互相耦合的状态分量时,需要一种全新的思路。这就是维纳滤波和卡尔曼滤波的出发点。
三、维纳滤波
移动平均和指数平滑的滤波器参数——窗口宽度 或平滑因子 ——是完全靠经验调的,没有任何"最优"的保证。维纳滤波是历史上第一个在统计意义上最优的线性滤波器。它的核心洞察是:如果知道了信号和噪声各自的功率谱密度,就可以精确地算出使均方误差最小的滤波器传递函数。
在频域中,非因果维纳滤波器的传递函数有着极其简洁的形式:
这个公式的直觉非常清晰。在信噪比高的频率分量上(),——让信号无损通过。在信噪比低的频率分量上(),——完全抑制。维纳滤波器在每一个频率上独立地做信噪比加权,把滤波问题变成了一个简单的逐频率除法。
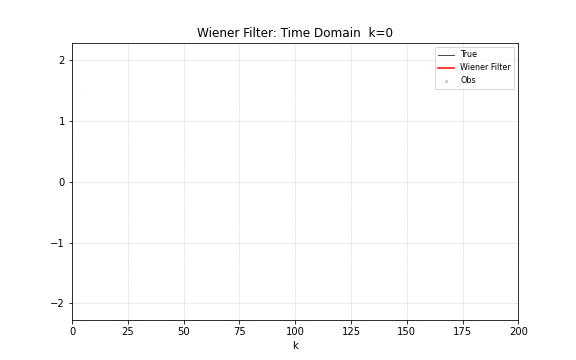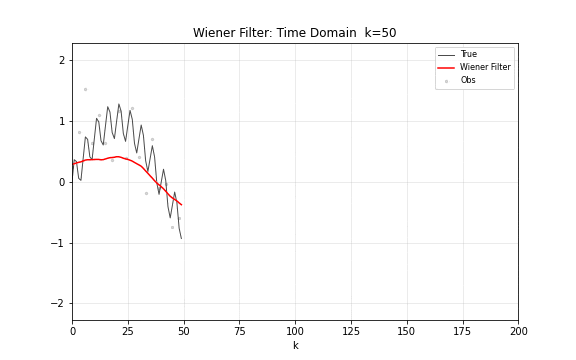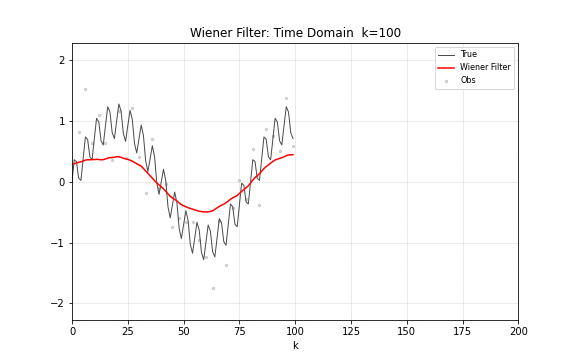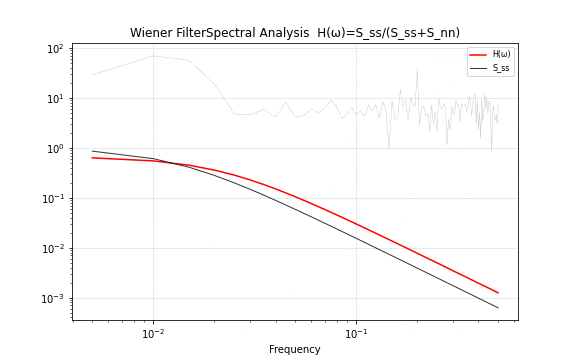
图 16. 维纳滤波过程。上半部分在时域中展示去噪效果,下半部分在频域中展示功率谱和传递函数 。高频区域的噪声功率大于信号功率, 压低这些频率分量;低频区域信号占主导, 接近 1 将其保留。
import numpy as np
def wiener_filter(obs, signal_psd, noise_psd):
X = np.fft.rfft(obs)
H = signal_psd / (signal_psd + noise_psd + 1e-10)
return np.fft.irfft(X * H, n=len(obs))
维纳滤波的三个致命缺陷也恰恰来自它的频域设计思路。它要求信号和噪声是平稳随机过程——统计特性不随时间改变,但现实中的信号往往包含趋势和突变。它要求批量处理整段数据,无法实时递推。它只能处理标量信号,无法描述多维状态之间的耦合关系。这三个局限引出了卡尔曼滤波的革命性突破——用状态空间模型彻底取代频域模型。
四、卡尔曼滤波
1960 年,鲁道夫·卡尔曼用一种完全不同的问题表述方式解决了维纳滤波的三个局限。他不把滤波看作频域中的最优传递函数设计,而是把它描述为时域中的状态递推估计。系统在每一个时刻有一个不可直接观测的状态 ,我们只能获得含噪声的观测 。已知状态如何随时间演化(状态方程),已知观测如何从状态产生(观测方程),任务是根据所有历史观测给出当前状态的最优估计。
状态空间模型由两个方程组成:
是状态转移矩阵,描述系统在没有噪声时如何从上一状态演化到当前状态。 是观测矩阵,描述状态如何映射到测量空间。过程噪声 和观测噪声 是独立的高斯白噪声。
算法以两步递推方式运行。预测步按系统模型将上一时刻的后验估计向前推演,得到当前时刻的先验估计:
更新步用当前观测修正先验估计,得到后验估计:
是卡尔曼增益矩阵,是整个滤波器的核心。以标量情况为例,——当观测噪声 很大时 (不相信观测),当 很小时 (充分相信观测)。卡尔曼增益在每一步自动调节预测与观测之间的信任权重。
从贝叶斯观点看,预测步给出了先验分布 ,更新步用贝叶斯公式将先验与似然 相乘得到后验分布 。在高斯假设下,后验仍然是高斯分布,其均值和协方差恰好由卡尔曼方程给出——这是线性高斯系统下的精确贝叶斯递推。
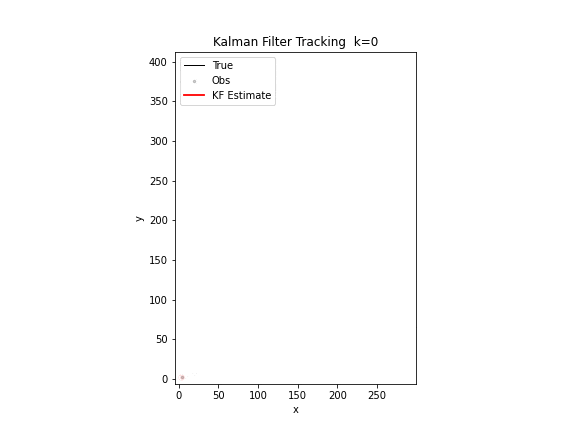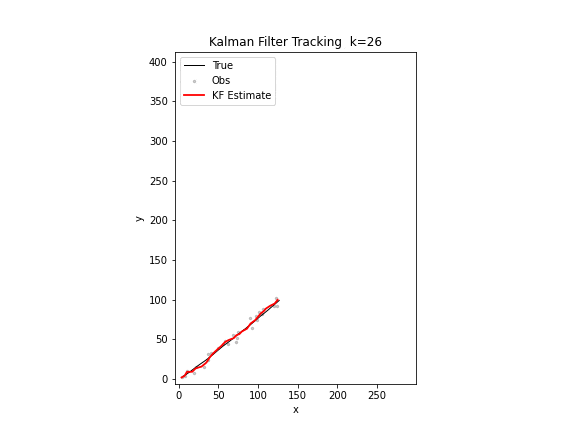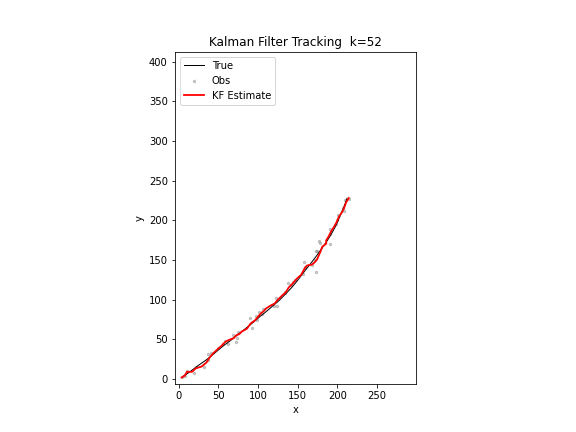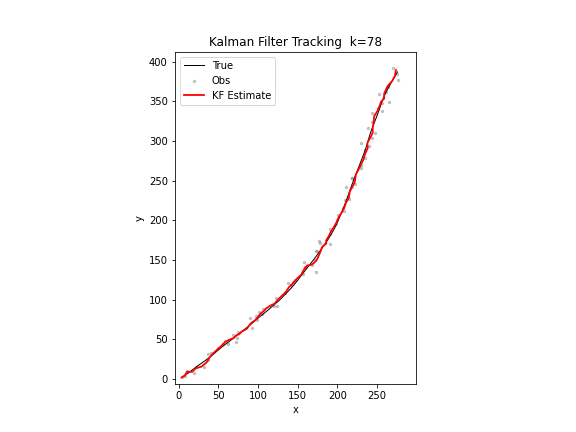
图 17. 卡尔曼滤波追踪。黑色为真实轨迹,红色为滤波估计,红色椭圆为误差协方差矩阵的 2σ 置信区域。随着观测不断到达,估计轨迹逐步贴合真实轨迹,椭圆逐渐缩小。
import numpy as np
def kalman_filter(z_obs, F, H, Q, R, x0, P0):
N, n = len(z_obs), len(x0)
x_est = np.zeros((N, n)); x, P = x0, P0
for k in range(N):
xp = F @ x; Pp = F @ P @ F.T + Q
S = H @ Pp @ H.T + R; K = Pp @ H.T @ np.linalg.inv(S)
x = xp + K @ (z_obs[k] - H @ xp)
P = (np.eye(n) - K @ H) @ Pp
x_est[k] = x
return x_est
卡尔曼滤波在线性高斯假设下是最优的——它给出了最小均方误差估计。但现实中的系统往往是非线性的:雷达测量的是距离和方位角(观测的非线性),飞行器的动力学涉及旋转(状态转移的非线性)。一旦离开线性的框架,矩阵乘法就不再适用。最直接的推广思路是在当前估计点把非线性函数做一阶泰勒展开——这就是扩展卡尔曼滤波。
五、扩展卡尔曼滤波(EKF)
标准卡尔曼滤波的预测步是 ,一个矩阵乘法。EKF 把这个线性变换替换为非线性函数的直接求值 。矩阵只在协方差传播中出现——用来近似描述不确定性如何通过非线性函数传播。
设系统为 ,。EKF 在每一时刻计算两个雅可比矩阵: 是状态转移函数 对状态向量的偏导数矩阵, 是观测函数 对状态向量的偏导数矩阵。这两个矩阵是多元微积分中"导数"概念的推广——在展开点附近给出非线性函数的最佳线性近似。
预测步变为 ,协方差仍用雅可比传播:。更新步中残差变为 , 是观测函数的雅可比矩阵。
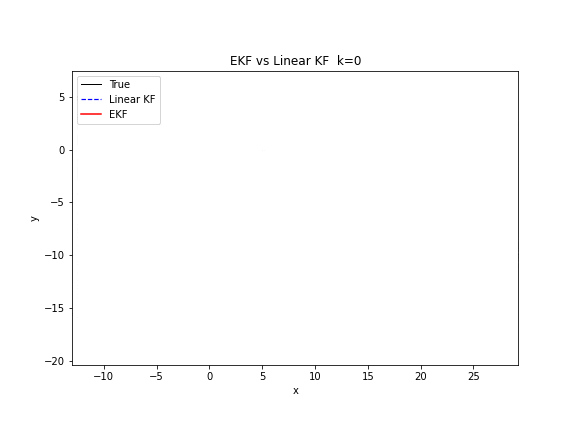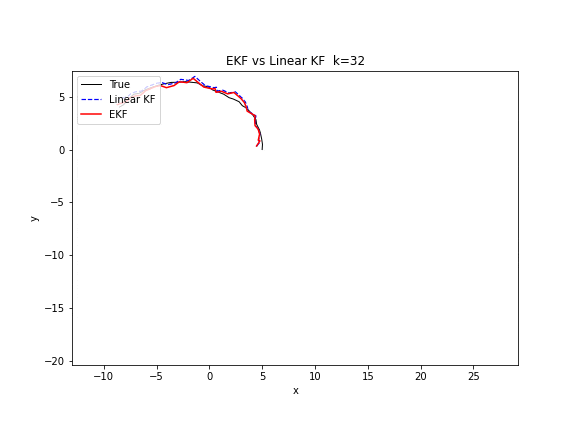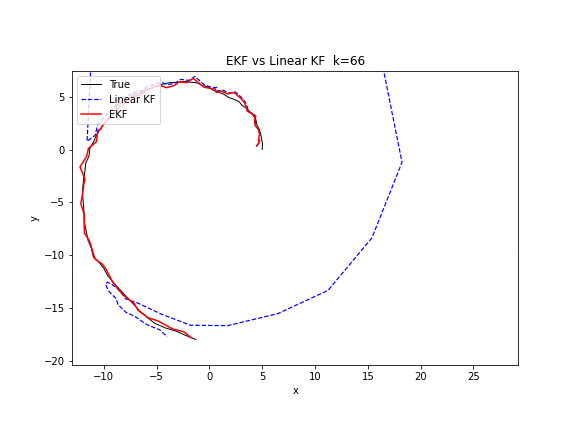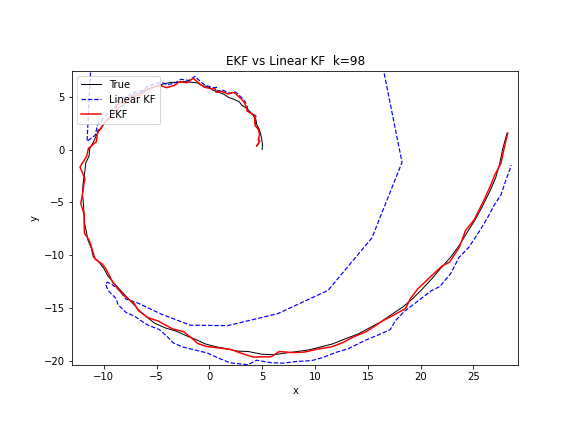
图 18. EKF 与线性 KF 的对比。目标做圆周运动(非线性)。线性 KF(蓝色虚线)使用匀速直线模型来近似,轨迹逐渐偏离圆弧。EKF(红色实线)在每个时刻用非线性转弯模型和雅可比矩阵来预测,轨迹紧密贴合真实圆周。
import numpy as np
def ekf(z_obs, f, h, F_jac, H_jac, Q, R, x0, P0):
N, n = len(z_obs), len(x0)
x_est = np.zeros((N, n)); x, P = x0, P0
for k in range(N):
F = F_jac(x); xp = f(x); Pp = F @ P @ F.T + Q
H = H_jac(xp); S = H @ Pp @ H.T + R
K = Pp @ H.T @ np.linalg.inv(S)
x = xp + K @ (z_obs[k] - h(xp))
P = (np.eye(n) - K @ H) @ Pp
x_est[k] = x
return x_est
EKF 把卡尔曼滤波从线性成功推广到了非线性,至今仍是工程中最广泛使用的非线性滤波器。但它的核心手段——一阶泰勒展开——有两个根本缺陷:强非线性下截断误差大,且要求函数处处可微。如果不用导数来近似函数,而是用采样点来近似分布——这就是无迹卡尔曼滤波的思路。
六、无迹卡尔曼滤波(UKF)
EKF 近似的是函数——用切线代替曲线。UKF 近似的是分布——用一组精心选取的采样点(西格玛点)代替整个高斯分布,让这些点各自独立地通过真实的非线性函数,然后用变换后的点集重建新的均值和协方差。由于没有线性化步骤,就不需要计算雅可比矩阵;由于西格玛点保留了分布的三阶矩信息,UKF 在强非线性下的精度通常优于 EKF。
对于 维状态,UKF 生成 个西格玛点:
其中 是协方差矩阵 的 Cholesky 分解的第 列, 是控制采样点扩散范围的尺度参数。
预测步:将西格玛点通过非线性函数 ,加权求和得到先验估计 ,先验协方差由各点偏离的加权外积加上 得到。
更新步:将西格玛点通过非线性函数 ,计算预测观测 、观测协方差 、交叉协方差 ,然后 完成更新。
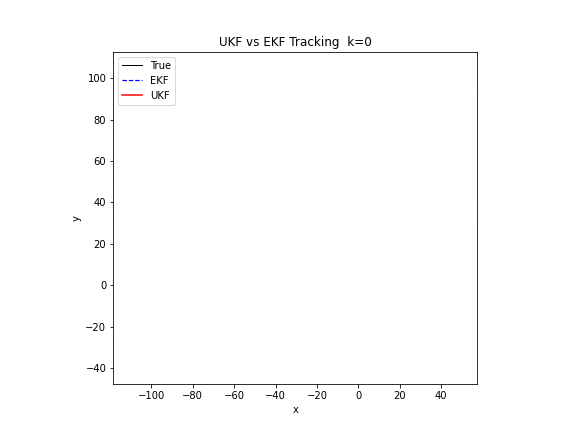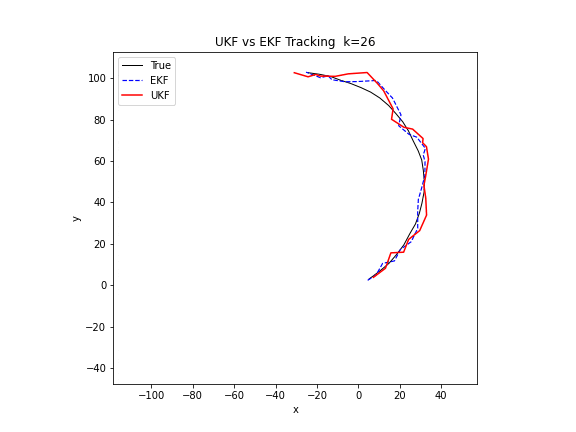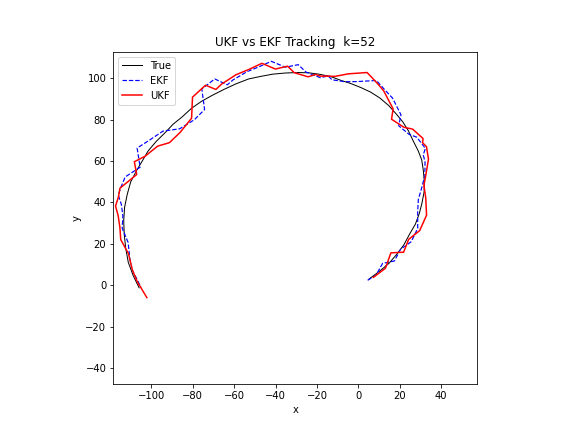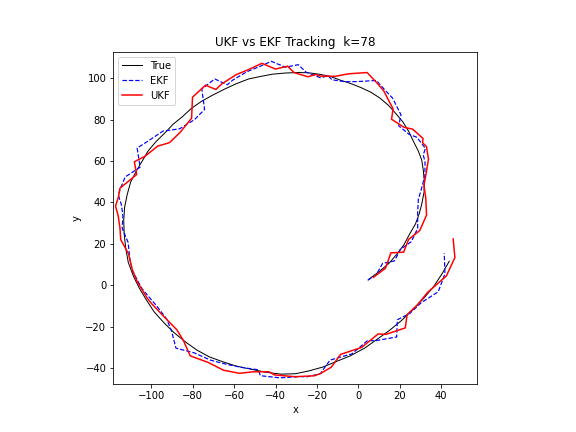
图 19. UKF 与 EKF 的对比。在相同的非线性转弯追踪场景中,UKF(红色)相比 EKF(蓝色虚线)更紧密地附着在真实轨迹(黑色)上。UKF 通过 9 个西格玛点传播分布,避免了 EKF 中雅可比矩阵线性化引入的截断误差。
import numpy as np
from scipy.linalg import cholesky, inv
def ukf(z_obs, f, h, Q, R, x0, P0, alpha=1e-3, kappa=0):
n = len(x0); lam = alpha**2 * (n + kappa) - n
wm = np.full(2*n+1, 1/(2*(n+lam))); wm[0] = lam/(n+lam)
wc = wm.copy(); wc[0] += 1 - alpha**2 + 2
N = len(z_obs); x_est = np.zeros((N, n)); x, P = x0, P0
for k in range(N):
L = cholesky((n + lam) * P + 1e-6*np.eye(n), lower=True)
sig = np.zeros((2*n+1, n)); sig[0] = x
for i in range(n):
sig[i+1] = x + L[:, i]; sig[i+1+n] = x - L[:, i]
f_sig = np.array([f(s) for s in sig])
xp = np.sum(wm[:, None] * f_sig, axis=0)
Pp = Q + sum(wc[i] * np.outer(f_sig[i]-xp, f_sig[i]-xp) for i in range(2*n+1))
h_sig = np.array([h(s) for s in sig])
zp = np.sum(wm[:, None] * h_sig, axis=0)
Pzz = R + sum(wc[i] * np.outer(h_sig[i]-zp, h_sig[i]-zp) for i in range(2*n+1))
Pxz = sum(wc[i] * np.outer(f_sig[i]-xp, h_sig[i]-zp) for i in range(2*n+1))
K = Pxz @ inv(Pzz); x = xp + K @ (z_obs[k] - zp)
P = Pp - K @ Pzz @ K.T; x_est[k] = x
return x_est
UKF 比 EKF 精度更高、不需要雅可比矩阵、可处理不可微函数。但 EKF 和 UKF 共享一个根本局限:它们都假设后验分布可以用一个高斯分布来近似。一旦后验是多峰的、重尾的、或者高度非高斯的,这个假设就失效了。要彻底放弃高斯假设,需要一种完全不同的方法——用大量随机样本来表示任意分布。
七、粒子滤波
EKF 用雅可比矩阵近似函数,UKF 用西格玛点近似高斯分布的变换。两者都依赖同一个假设:后验是高斯分布。粒子滤波完全放弃了这个假设。它用 个带权重的随机样本——粒子——直接表示后验分布,不论这个分布是什么形状都无所谓。这是所有滤波方法中最通用的一种。
粒子滤波的核心近似是 。当粒子数 时,这个近似在理论上收敛到真实的贝叶斯后验。
每一步递推包含三个操作。重要性采样:从提议分布中抽取新的粒子——最简方案是直接按状态转移分布推进每一颗粒子并加过程噪声。权重更新:根据观测似然计算每颗粒子的权重——当前观测下粒子状态越合理权重越高。重采样:依权重随机复制高权重粒子、丢弃低权重粒子,防止大部分权重集中在少数粒子上(粒子退化)。
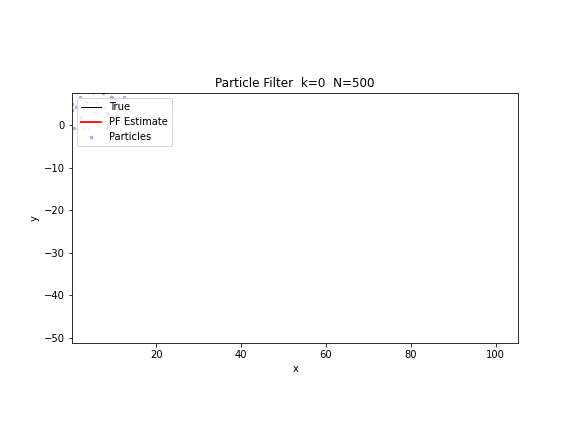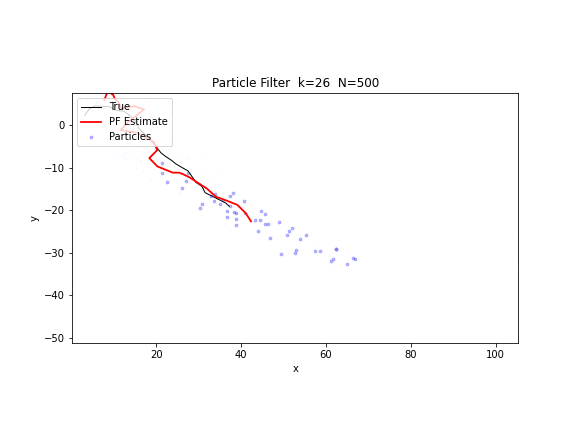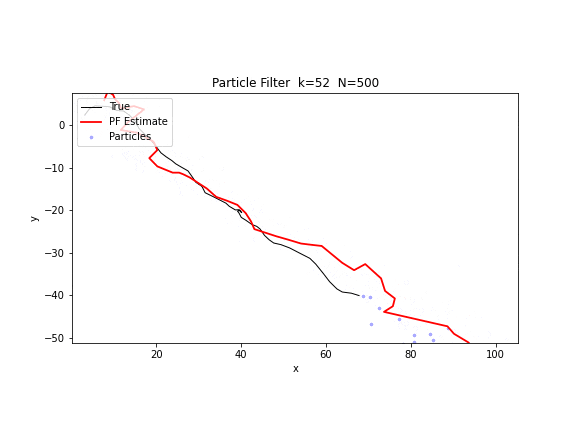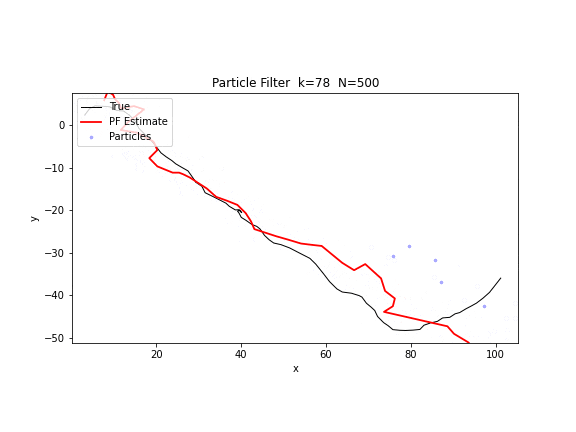
图 20. 粒子滤波追踪。500 个粒子(蓝色散点)在仅有方位角观测的条件下追踪一个运动目标。粒子云从初始的广泛散布逐步收敛到真实轨迹附近,红色线为加权估计。
import numpy as np
def particle_filter(z_obs, f, h, Q, R_std, n_particles, state_dim):
N = len(z_obs)
particles = np.random.randn(n_particles, state_dim) * 5
weights = np.ones(n_particles) / n_particles
x_est = np.zeros((N, state_dim))
for k in range(N):
particles = np.array([f(p) + np.random.multivariate_normal(np.zeros(state_dim), Q)
for p in particles])
z_pred = np.array([h(p) for p in particles])
innov = z_obs[k] - z_pred
weights = np.exp(-0.5 * np.sum((innov / R_std)**2,
axis=1if innov.ndim > 1else0))
weights /= np.sum(weights) + 1e-300
x_est[k] = np.sum(weights[:, None] * particles, axis=0)
cdf = np.cumsum(weights); cdf[-1] = 1.0
u = np.random.uniform(0, 1/n_particles)
idx = np.searchsorted(cdf, u + np.arange(n_particles) / n_particles)
particles = particles[idx]; weights.fill(1/n_particles)
return x_est
粒子滤波的通用性是有代价的:计算量显著大于卡尔曼类方法,且在高维状态空间中粒子数需要呈指数增长才能维持表示精度——维数灾难。实际应用中,粒子滤波在 4 维以下的状态空间表现良好,但在 10 维以上通常极其昂贵。
七种方法综合对比
| 方法 | 线性要求 | 高斯要求 | 递推 | 最优性 | 代价 |
|---|---|---|---|---|---|
| 移动平均 | — | — | 近似 | 仅常数信号 | 极低 |
| 指数平滑 | — | — | 是 | 仅常数信号 | 极低 |
| 维纳滤波 | 线性时不变 | 平稳 | 否 | 平稳信号最优 | 中 |
| 卡尔曼滤波 | 线性 | 高斯 | 是 | 线性高斯最优 | 低 |
| EKF | 局部可微 | 近似高斯 | 是 | 一阶近似 | 中 |
| UKF | — | 近似高斯 | 是 | 三阶近似 | 中 |
| 粒子滤波 | — | — | 是 | 渐近最优 | 高 |
从移动平均到粒子滤波,本质上是一条逐步放宽假设、提升精度的演化路径。移动平均不需要任何统计模型——给出一个窗口宽度就能跑。指数平滑用一个标量状态递推,存储和计算几乎免费。维纳滤波第一次引入统计最优性,但绑定在频域和平稳假设上。卡尔曼滤波用状态空间模型实现时域递推,在线性高斯框架下是最优的。EKF 和 UKF 把卡尔曼框架推广到非线性系统:一个近似函数,一个近似分布。粒子滤波在最极端的情况下也成立——没有任何线性或高斯的假设,代价是计算量。
在实践中选择哪种方法,取决于问题的线性程度、噪声性质、实时性要求和可用计算资源。如果系统近似线性高斯,卡尔曼滤波几乎总是首选。有中等非线性时,EKF 足够且实现简单。强非线性且状态维度不高时,UKF 更精准。噪声严重非高斯或后验本身复杂时,粒子滤波是唯一可靠的选择——前提是算得起。
预览时标签不可点
Close
更多
Name cleared
微信扫一扫赞赏作者
Like the AuthorOther Amount
赞赏后展示我的头像
作品
暂无作品
Like the Author
Other Amount
¥
最低赞赏 ¥0
OK
Back
Other Amount
更多
赞赏金额
¥
最低赞赏 ¥0
1
2
3
4
5
6
7
8
9
0
.
基础知识 · 目录
基础知识
上一篇你的电脑每秒能做多少次浮点运算?—— FLOPS 的故事下一篇学习这件事,得先让孩子不恨它
Close
更多
搜索「」网络结果
Close
调整当前正文文字大小
更多
100%