上一篇介绍了 EKF。它通过一阶泰勒展开(雅可比矩阵)把非线性系统线性化后代入卡尔曼方程。但线性化有两个根本缺陷:强非线性下截断误差大,且要求函数处处可微。Julier 和 Uhlmann 在 1997 年提出了完全不同的思路:不在函数上做近似,而是在分布上做近似。这就是无迹卡尔曼滤波(Unscented Kalman Filter, UKF)。
与 EKF 的对比
EKF 近似的是函数——用切线代替曲线。UKF 近似的是分布——用一组采样点代替高斯分布,让这些点各自通过真实的非线性函数,再用变换后的点集重建新的均值和协方差。这避开了雅可比计算,也保留了更高阶的统计信息。对高斯分布而言,UKF 的精度达到三阶泰勒展开等价,而 EKF 仅为一阶。
核心思想
UKF 在状态的均值和协方差周围选取一组称为西格玛点(sigma points)的确定性采样点,将这些点各自独立地通过非线性函数,然后用变换后的点集重建输出的均值和协方差。对于 \(n\) 维状态,共生成 \(2n+1\) 个西格玛点。
西格玛点采样
设当前估计为 \(\hat{x}\),协方差为 \(P\),尺度参数 \(\lambda = \alpha^2(n + \kappa) - n\),其中 \(\alpha\) 和 \(\kappa\) 是控制西格玛点扩散范围的参数。西格玛点定义为:
这里 \(\left( \sqrt{(n+\lambda)P} \right)_i\) 表示矩阵 \((n+\lambda)P\) 的 Cholesky 分解的第 \(i\) 列。
对应的权重为:
其中 \(\beta\) 是刻画先验分布高阶矩的参数(对高斯分布取 \(\beta = 2\) 最优)。
预测-更新递推
预测步——将西格玛点通过非线性状态转移函数 \(f\),加权重建先验估计:
更新步——将先验西格玛点通过非线性观测函数 \(h\),加权重建观测预测和交叉协方差:
可视化
下图的 GIF 在同一个非线性追踪场景中对比了 EKF 和 UKF 的表现。UKF 通过西格玛点传播分布,不需要计算雅可比矩阵,在转弯模型下的估计精度明显优于 EKF。
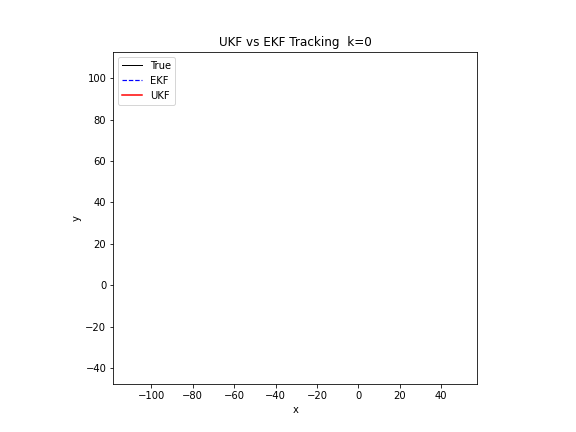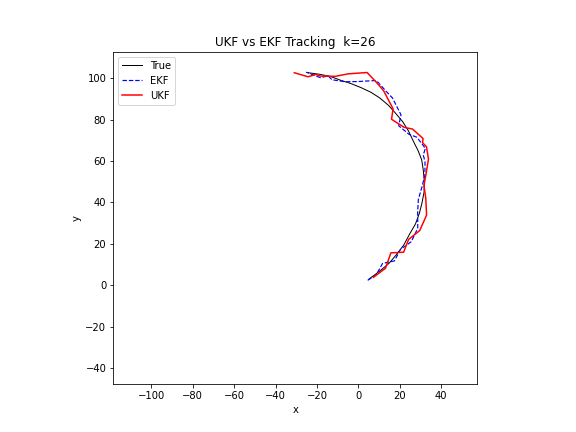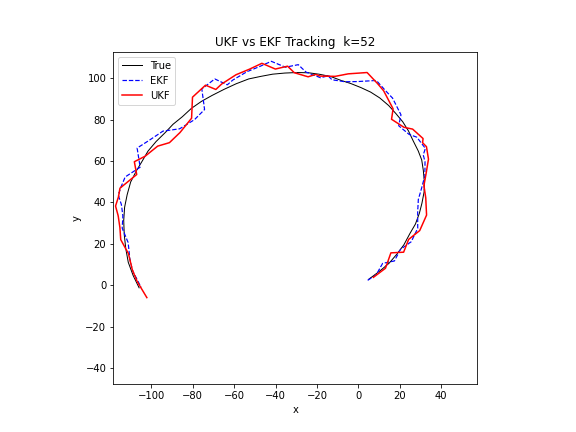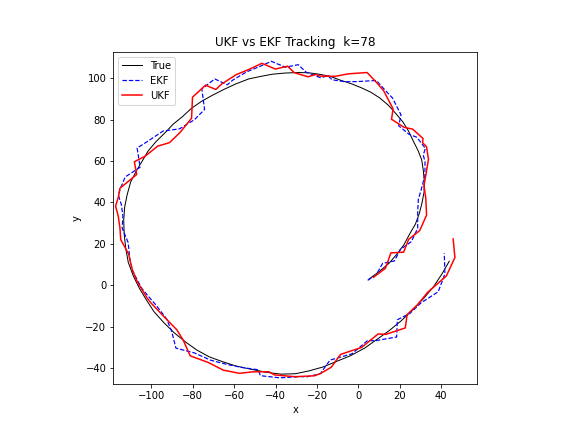
Python 实现
下面的代码在同一个圆周运动追踪场景中对比 EKF 与 UKF。UKF 采用 \(2n+1=9\) 个西格玛点(状态维数 \(n=4\)),通过非线性状态转移函数 \(f\) 后加权重建均值和协方差,再通过非线性观测函数 \(h\) 重建预测观测与交叉协方差。输出轨迹对比图与误差图(SVG/PNG)、逐步展开的 GIF,以及记录 \(k\)、true、ekf、ukf、errors 的 CSV。
import os
os.makedirs('images', exist_ok=True)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import csv
np.random.seed(42)
# ---------- 圆周运动真值 ----------
DT = 0.1
N = 120
OMEGA = 0.3
R_TRUE = 1.0
Q = np.diag([0.01, 0.01, 0.01, 0.01])
R_OBS = np.diag([0.05**2, 0.02**2])
N_STATE = 4
def true_trajectory():
tr = []
for k in range(N):
th = OMEGA * k * DT
px, py = R_TRUE * np.cos(th), R_TRUE * np.sin(th)
vx, vy = -R_TRUE * OMEGA * np.sin(th), R_TRUE * OMEGA * np.cos(th)
tr.append(np.array([px, py, vx, vy]))
return np.array(tr)
def h_obs(x):
px, py = x[0], x[1]
return np.array([np.hypot(px, py), np.arctan2(py, px)])
def H_jac(x):
# Jacobian matrix of observation function h(x)
px, py = x[0], x[1]
r = np.hypot(px, py) + 1e-12
H = np.zeros((2, 4))
H[0, 0] = px / r; H[0, 1] = py / r
H[1, 0] = -py / (r * r); H[1, 1] = px / (r * r)
return H
def f_ekf(x):
px, py, vx, vy = x
c, s = np.cos(OMEGA * DT), np.sin(OMEGA * DT)
vx_n = c * vx - s * vy; vy_n = s * vx + c * vy
return np.array([px + vx_n * DT, py + vy_n * DT, vx_n, vy_n])
def F_jac(x):
# Jacobian matrix of state transition function f(x)
c, s = np.cos(OMEGA * DT), np.sin(OMEGA * DT)
return np.array([[1, 0, c * DT, -s * DT],
[0, 1, s * DT, c * DT],
[0, 0, c, -s],
[0, 0, s, c]])
# ---------- EKF ----------
def ekf(zs):
x = np.array([1.0, 0.0, 0.0, OMEGA * R_TRUE])
P = np.eye(4) * 0.1
out = []
for z in zs:
F = F_jac(x); x = f_ekf(x)
P = F @ P @ F.T + Q
H = H_jac(x); zp = h_obs(x)
S = H @ P @ H.T + R_OBS
K = P @ H.T @ np.linalg.inv(S)
x = x + K @ (z - zp)
P = (np.eye(4) - K @ H) @ P
out.append(x.copy())
return np.array(out)
# ---------- UKF ----------
ALPHA, BETA, KAPPA = 1e-3, 2.0, 0.0
LAMBDA = ALPHA ** 2 * (N_STATE + KAPPA) - N_STATE
def sigma_points(x, P):
sqrt = np.linalg.cholesky((N_STATE + LAMBDA) * P)
pts = [x]
for i in range(N_STATE):
pts.append(x + sqrt[:, i])
pts.append(x - sqrt[:, i])
return np.array(pts)
def ukf_weights():
Wm = np.full(2 * N_STATE + 1, 1.0 / (2 * (N_STATE + LAMBDA)))
Wc = np.full(2 * N_STATE + 1, 1.0 / (2 * (N_STATE + LAMBDA)))
Wm[0] = LAMBDA / (N_STATE + LAMBDA)
Wc[0] = LAMBDA / (N_STATE + LAMBDA) + (1 - ALPHA ** 2 + BETA)
return Wm, Wc
def ukf(zs):
x = np.array([1.0, 0.0, 0.0, OMEGA * R_TRUE])
P = np.eye(4) * 0.1
Wm, Wc = ukf_weights()
out = []
for z in zs:
# predict
sig = sigma_points(x, P)
sig_f = np.array([f_ekf(p) for p in sig])
x = np.sum(Wm[:, None] * sig_f, axis=0)
P = np.zeros((4, 4))
for i in range(2 * N_STATE + 1):
d = (sig_f[i] - x).reshape(-1, 1)
P += Wc[i] * d @ d.T
P += Q
# update
sig = sigma_points(x, P)
sig_h = np.array([h_obs(p) for p in sig])
zp = np.sum(Wm[:, None] * sig_h, axis=0)
Pzz = np.zeros((2, 2)); Pxz = np.zeros((4, 2))
for i in range(2 * N_STATE + 1):
dz = (sig_h[i] - zp).reshape(-1, 1)
dx = (sig[i] - x).reshape(-1, 1)
Pzz += Wc[i] * dz @ dz.T
Pxz += Wc[i] * dx @ dz.T
Pzz += R_OBS
K = Pxz @ np.linalg.inv(Pzz)
x = x + K @ (z - zp)
P = P - K @ Pzz @ K.T
out.append(x.copy())
return np.array(out)
# ---------- 生成观测 ----------
truth = true_trajectory()
zs = np.array([h_obs(truth[k]) + np.random.multivariate_normal(np.zeros(2), R_OBS)
for k in range(N)])
ekf_traj = ekf(zs)
ukf_traj = ukf(zs)
ekf_err = np.linalg.norm(ekf_traj[:, :2] - truth[:, :2], axis=1)
ukf_err = np.linalg.norm(ukf_traj[:, :2] - truth[:, :2], axis=1)
# ---------- 轨迹图 ----------
fig, ax = plt.subplots(figsize=(6, 6))
ax.plot(truth[:, 0], truth[:, 1], 'k-', label='True')
ax.plot(ekf_traj[:, 0], ekf_traj[:, 1], 'r--', label='EKF')
ax.plot(ukf_traj[:, 0], ukf_traj[:, 1], 'b-.', label='UKF')
ax.set_xlabel('px'); ax.set_ylabel('py')
ax.set_title('UKF vs EKF: Constant Turn Model')
ax.legend(); ax.axis('equal'); ax.grid(True)
fig.tight_layout()
fig.savefig('images/ukf_trajectory.svg'); fig.savefig('images/ukf_trajectory.png')
plt.close(fig)
# ---------- 误差图 ----------
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(ekf_err, 'r-', label='EKF')
ax.plot(ukf_err, 'b-', label='UKF')
ax.set_xlabel('k'); ax.set_ylabel('Position Error')
ax.set_title('Position Error: UKF vs EKF')
ax.legend(); ax.grid(True)
fig.tight_layout()
fig.savefig('images/ukf_error.svg'); fig.savefig('images/ukf_error.png')
plt.close(fig)
# ---------- GIF:EKF 和 UKF 轨迹逐步展开 ----------
fig, ax = plt.subplots(figsize=(6, 6))
ax.set_xlim(-1.5, 1.5); ax.set_ylim(-1.5, 1.5)
ax.set_xlabel('px'); ax.set_ylabel('py')
ax.set_title('UKF vs EKF: Constant Turn Model')
ax.grid(True)
ln_t, = ax.plot([], [], 'k-', label='True')
ln_e, = ax.plot([], [], 'r--', label='EKF')
ln_u, = ax.plot([], [], 'b-.', label='UKF')
ax.legend()
def update(i):
ln_t.set_data(truth[:i, 0], truth[:i, 1])
ln_e.set_data(ekf_traj[:i, 0], ekf_traj[:i, 1])
ln_u.set_data(ukf_traj[:i, 0], ukf_traj[:i, 1])
return ln_t, ln_e, ln_u
ani = animation.FuncAnimation(fig, update, frames=N, interval=50, blit=True)
ani.save('images/滤波06-图1.gif', writer='pillow')
plt.close(fig)
# ---------- CSV ----------
with open('images/ukf_comparison.csv', 'w', newline='') as f:
w = csv.writer(f)
w.writerow(['k', 'true_px', 'true_py', 'ekf_px', 'ekf_py', 'ukf_px', 'ukf_py', 'ekf_err', 'ukf_err'])
for k in range(N):
w.writerow([k, truth[k, 0], truth[k, 1], ekf_traj[k, 0], ekf_traj[k, 1],
ukf_traj[k, 0], ukf_traj[k, 1], ekf_err[k], ukf_err[k]])
演化与局限
UKF 相比 EKF 是显著进步:不需要计算雅可比矩阵、精度更高、可处理不可微函数。但 EKF 和 UKF 共享一个根本假设——后验分布可以用高斯分布近似表示。当系统的噪声严重非高斯(如多峰分布、重尾分布),或当后验分布本身高度非高斯时,这个假设导致两者都会失效。
要彻底放弃高斯假设,需要用大量随机样本直接表示任意分布——不假设任何参数形式。这就是粒子滤波,下一篇也是最后一篇的主题。
参考文献
[1] arXiv:1903.09247 — The Hitchhiker's Guide to Nonlinear Filtering.
[2] arXiv:2201.08180 — Sequential Bayesian Inference for Uncertain Nonlinear Dynamic Systems: A Tutorial.