上一篇介绍了 UKF。它通过西格玛点传播分布,比 EKF 精度更高且不需要计算雅可比矩阵。但 EKF 和 UKF 共享一个根本假设:后验分布可以用高斯分布近似。粒子滤波(Particle Filter)彻底放弃了这个假设,用大量带权重的随机样本直接表示任意分布——不假设任何参数形式。
与 EKF 和 UKF 的对比
EKF 用雅可比矩阵近似非线性函数(近似函数),UKF 用西格玛点近似高斯分布通过非线性函数的变换(近似分布)。两者都假设后验是高斯的。粒子滤波不做任何参数化假设:它用 \(N\) 个带权重的粒子 \(\{x_k^{(i)}, w_k^{(i)}\}\) 直接近似后验分布 \(p(x_k \mid z_{1:k})\),无论这个分布是什么形状——单峰、多峰、重尾、偏斜——都能表示。代价是计算量随状态维度指数增长。
核心思想
粒子滤波也称序贯蒙特卡洛(Sequential Monte Carlo, SMC)。它的基本思想是用 \(N\) 个带权重的粒子 \(\{x_k^{(i)}, w_k^{(i)}\}_{i=1}^N\) 来近似后验分布 \(p(x_k \mid z_{1:k})\):
其中 \(\delta(\cdot)\) 是 Dirac delta 函数。当粒子数 \(N \to \infty\) 时,这个近似收敛到真实的后验分布。粒子滤波可以处理任意的非线性、非高斯系统——这是它相对于卡尔曼类方法的根本优势。
三个基本步骤
粒子滤波的每步递推包含三个基本操作。
重要性采样
从提议分布 \(q(x_k \mid x_{k-1}^{(i)}, z_k)\) 中抽取新粒子 \(x_k^{(i)}\)。最简单的选择是使用状态转移分布作为提议分布:\(q = p(x_k \mid x_{k-1}^{(i)})\),即按照系统模型将每个粒子向前推进一步并加入过程噪声。
权重更新
根据观测似然为每个粒子赋予权重:
如果使用状态转移分布作为提议分布,权重恰好等于观测似然。权重归一化后 \(\sum_i w_k^{(i)} = 1\)。
重采样
依权重大小随机复制高权重粒子、丢弃低权重粒子,以避免粒子退化——即少数粒子占据了绝大部分权重而大多数粒子的权重几乎为零。常用的系统重采样算法构造累积权重分布的逆函数采样,确保高权重粒子被复制、低权重粒子被淘汰。
算法伪代码
初始化:从先验分布 \(p(x_0)\) 中抽取 \(N\) 个粒子 \(\{x_0^{(i)}\}\),权重 \(w_0^{(i)} = 1/N\)。
对每个时刻 \(k = 1, 2, \dots\):
- 采样:\(x_k^{(i)} \sim p(x_k \mid x_{k-1}^{(i)})\)
- 权重:\(w_k^{(i)} \propto p(z_k \mid x_k^{(i)})\)
- 归一化:\(w_k^{(i)} = w_k^{(i)} / \sum_j w_k^{(j)}\)
- 估计:\(\hat{x}_k = \sum_i w_k^{(i)} x_k^{(i)}\)
- 重采样:依 \(\{w_k^{(i)}\}\) 重采样,重置权重为 \(1/N\)
维数灾难
粒子滤波是完全通用的:它可以处理任意的非线性、非高斯系统。理论上,当粒子数趋于无穷时,粒子滤波收敛到精确的贝叶斯解。代价是计算量显著大于卡尔曼类方法,且在高维状态空间中面临维数灾难——为维持合理的表示精度所需的粒子数随状态维度指数增长。实践中,粒子滤波在 4 维以下的状态空间中表现良好,但在 10 维以上时通常需要极其庞大的粒子数。
可视化
下图的 GIF 展示了 500 个粒子在方位角观测下的追踪过程。蓝色点代表粒子集合,红色线代表加权估计。可以看到粒子云逐步从发散的初始分布收敛到真实轨迹附近。
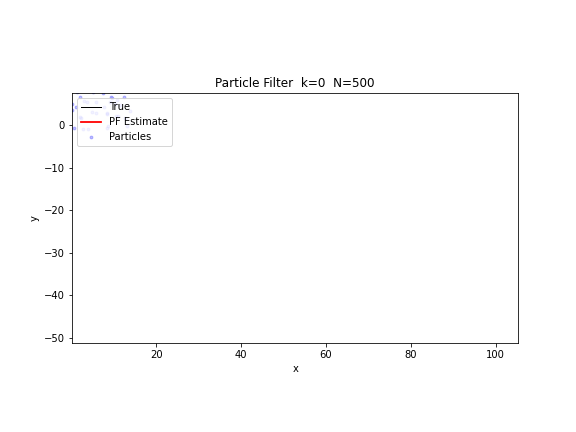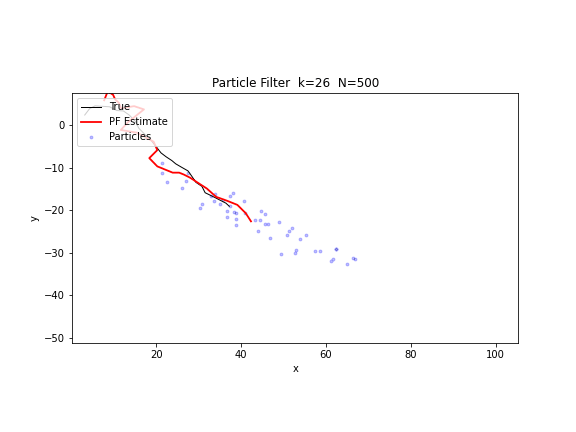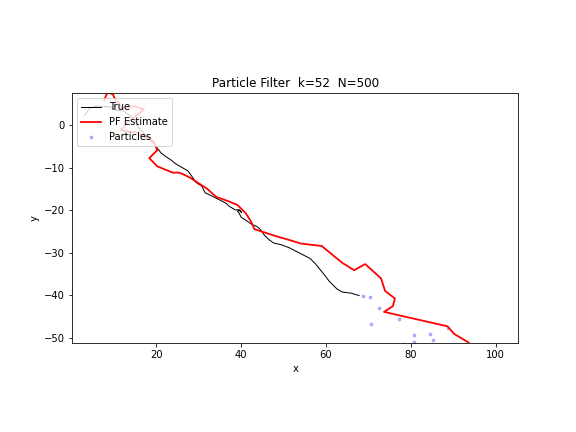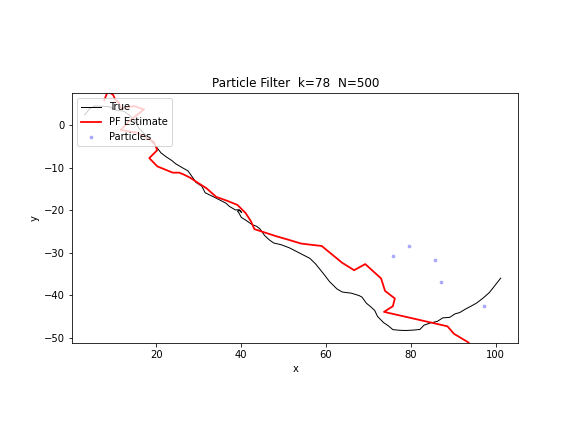
Python 实现
下面的代码实现一个 500 粒子的粒子滤波,用于方位角观测追踪。每步包含三个基本操作:重要性采样(按状态转移分布推进并加噪声)、权重更新(观测似然)、系统重采样。输出轨迹图(含粒子散点)与误差图(SVG/PNG)、粒子云与估计轨迹逐步展开的 GIF,以及记录 \(k\)、true、est、error 的 CSV。
import os
os.makedirs('images', exist_ok=True)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import csv
np.random.seed(42)
# ---------- 圆周运动真值 ----------
DT = 0.1
N = 120
OMEGA = 0.3
R_TRUE = 1.0
N_PARTICLES = 500
PROC_STD = np.array([0.02, 0.02, 0.05, 0.05]) # 过程噪声
OBS_ANGLE_STD = 0.03 # 方位角观测噪声
def true_trajectory():
tr = []
for k in range(N):
th = OMEGA * k * DT
px, py = R_TRUE * np.cos(th), R_TRUE * np.sin(th)
vx, vy = -R_TRUE * OMEGA * np.sin(th), R_TRUE * OMEGA * np.cos(th)
tr.append(np.array([px, py, vx, vy]))
return np.array(tr)
def transition(x):
px, py, vx, vy = x
c, s = np.cos(OMEGA * DT), np.sin(OMEGA * DT)
vx_n = c * vx - s * vy; vy_n = s * vx + c * vy
return np.array([px + vx_n * DT, py + vy_n * DT, vx_n, vy_n])
def observe_angle(x):
return np.arctan2(x[1], x[0])
# ---------- 系统重采样 ----------
def systematic_resample(weights):
pos = (np.arange(N_PARTICLES) + np.random.uniform()) / N_PARTICLES
cum = np.cumsum(weights)
cum[-1] = 1.0
idx = np.zeros(N_PARTICLES, dtype=int)
j = 0
for i in range(N_PARTICLES):
while j < len(cum) - 1 and pos[i] > cum[j]:
j += 1
idx[i] = j
return idx
# ---------- 粒子滤波主循环 ----------
def particle_filter(zs):
# 初始化:在真实初值附近撒粒子
particles = np.array([np.array([1.0, 0.0, 0.0, OMEGA * R_TRUE]) +
np.random.randn(4) * np.array([0.3, 0.3, 0.2, 0.2])
for _ in range(N_PARTICLES)])
weights = np.ones(N_PARTICLES) / N_PARTICLES
ests = []
particle_history = []
for z in zs:
# 1) 重要性采样:状态转移 + 过程噪声
particles = np.array([transition(p) + np.random.randn(4) * PROC_STD
for p in particles])
# 2) 权重更新:方位角观测似然(高斯)
angles = np.array([observe_angle(p) for p in particles])
innov = ((angles - z + np.pi) % (2 * np.pi)) - np.pi
weights = np.exp(-0.5 * (innov / OBS_ANGLE_STD) ** 2)
weights += 1e-300
weights /= np.sum(weights)
# 3) 估计:加权均值
est = np.sum(weights[:, None] * particles, axis=0)
ests.append(est.copy())
particle_history.append(particles.copy())
# 4) 系统重采样
neff = 1.0 / np.sum(weights ** 2)
if neff < N_PARTICLES / 2:
idx = systematic_resample(weights)
particles = particles[idx]
weights = np.ones(N_PARTICLES) / N_PARTICLES
return np.array(ests), np.array(particle_history)
# ---------- 生成观测 ----------
truth = true_trajectory()
zs = np.array([observe_angle(truth[k]) +
np.random.normal(0, OBS_ANGLE_STD) for k in range(N)])
est_traj, part_hist = particle_filter(zs)
est_err = np.linalg.norm(est_traj[:, :2] - truth[:, :2], axis=1)
# ---------- 轨迹图(含粒子散点,取最后一帧) ----------
fig, ax = plt.subplots(figsize=(6, 6))
ax.plot(truth[:, 0], truth[:, 1], 'k-', label='True')
ax.plot(est_traj[:, 0], est_traj[:, 1], 'r-', label='PF Estimate')
ax.scatter(part_hist[-1, :, 0], part_hist[-1, :, 1], s=2, c='b', alpha=0.3, label='Particles')
ax.set_xlabel('px'); ax.set_ylabel('py')
ax.set_title('Particle Filter Tracking')
ax.legend(); ax.axis('equal'); ax.grid(True)
fig.tight_layout()
fig.savefig('images/pf_trajectory.svg'); fig.savefig('images/pf_trajectory.png')
plt.close(fig)
# ---------- 误差图 ----------
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(est_err, 'r-', label='PF Estimate')
ax.set_xlabel('k'); ax.set_ylabel('Position Error')
ax.set_title('Particle Filter: Position Error')
ax.legend(); ax.grid(True)
fig.tight_layout()
fig.savefig('images/pf_error.svg'); fig.savefig('images/pf_error.png')
plt.close(fig)
# ---------- GIF:粒子云 + 估计轨迹逐步展开 ----------
fig, ax = plt.subplots(figsize=(6, 6))
ax.set_xlim(-1.5, 1.5); ax.set_ylim(-1.5, 1.5)
ax.set_xlabel('px'); ax.set_ylabel('py')
ax.set_title('Particle Filter Tracking')
ax.grid(True)
ln_t, = ax.plot([], [], 'k-', label='True')
ln_e, = ax.plot([], [], 'r-', label='PF Estimate')
scat = ax.scatter([], [], s=2, c='b', alpha=0.3, label='Particles')
ax.legend()
def update(i):
ln_t.set_data(truth[:i, 0], truth[:i, 1])
ln_e.set_data(est_traj[:i, 0], est_traj[:i, 1])
scat.set_offsets(part_hist[i, :, :2])
return ln_t, ln_e, scat
ani = animation.FuncAnimation(fig, update, frames=N, interval=50, blit=False)
ani.save('images/滤波07-图1.gif', writer='pillow')
plt.close(fig)
# ---------- CSV ----------
with open('images/pf_comparison.csv', 'w', newline='') as f:
w = csv.writer(f)
w.writerow(['k', 'true_px', 'true_py', 'est_px', 'est_py', 'error'])
for k in range(N):
w.writerow([k, truth[k, 0], truth[k, 1], est_traj[k, 0], est_traj[k, 1], est_err[k]])
参考文献
[1] arXiv:1903.09247 — The Hitchhiker's Guide to Nonlinear Filtering.
[2] arXiv:2201.08180 — Sequential Bayesian Inference for Uncertain Nonlinear Dynamic Systems: A Tutorial.