上一篇介绍了卡尔曼滤波。它在线性高斯假设下是最优的递推估计器,但一旦状态转移函数 \(f\) 或观测函数 \(h\) 是非线性的,标准卡尔曼方程就不再适用。扩展卡尔曼滤波(Extended Kalman Filter, EKF)的思路最为直接:将非线性函数在当前估计点做一阶泰勒展开,用雅可比矩阵替代线性模型中的 \(F_k\) 和 \(H_k\)。
与标准卡尔曼滤波的对比
标准卡尔曼滤波的预测步是矩阵乘法 \(\hat{x}_{k|k-1} = F_k \hat{x}_{k-1|k-1}\),更新步的残差是 \(z_k - H_k \hat{x}_{k|k-1}\)——全是线性运算。EKF 把这两步中的线性变换换成非线性函数的直接求值:\(\hat{x}_{k|k-1} = f(\hat{x}_{k-1|k-1})\),残差变为 \(z_k - h(\hat{x}_{k|k-1})\)。雅可比矩阵仅在协方差传播中使用——它们近似描述不确定性如何通过非线性函数变换。
非线性模型
设状态转移和观测为非线性可微函数:
EKF 在每一时刻计算雅可比矩阵:
然后将标准卡尔曼方程中的 \(F_k\) 和 \(H_k\) 替换为这些雅可比矩阵,预测和更新的其余步骤完全不变。
预测-更新方程
预测步:
更新步:
注意与标准卡尔曼滤波的区别:预测步中 \(\hat{x}_{k|k-1}\) 直接由非线性函数 \(f\) 计算,而非矩阵乘法;更新步中残差由非线性观测函数 \(h\) 计算。雅可比矩阵仅在协方差传播中使用。
可视化
下图的 GIF 对比了线性 KF 和 EKF 在追踪圆周运动目标时的表现差异。线性 KF 使用匀速直线模型近似圆周运动,而 EKF 在每个时刻用非线性转弯模型预测。可以清楚地看到,EKF 的轨迹更紧密地贴合了真实圆周路径。
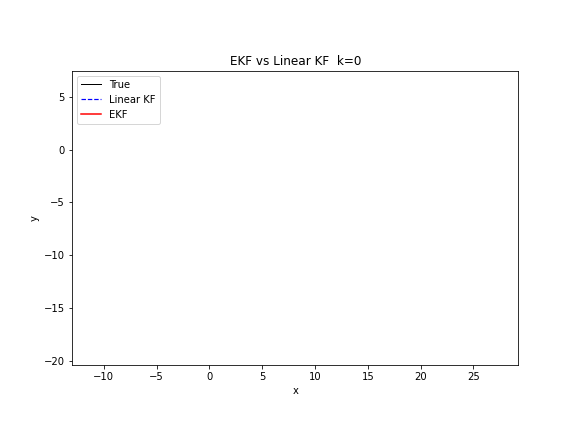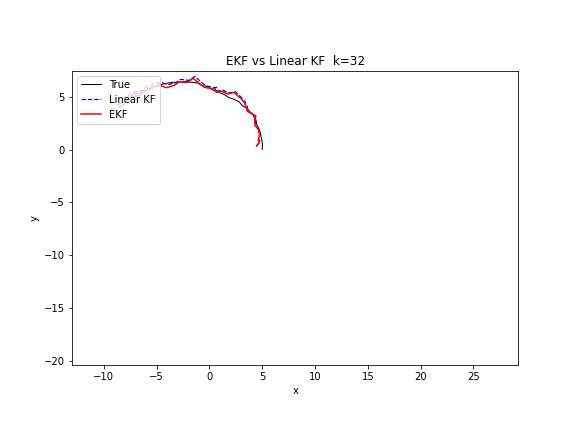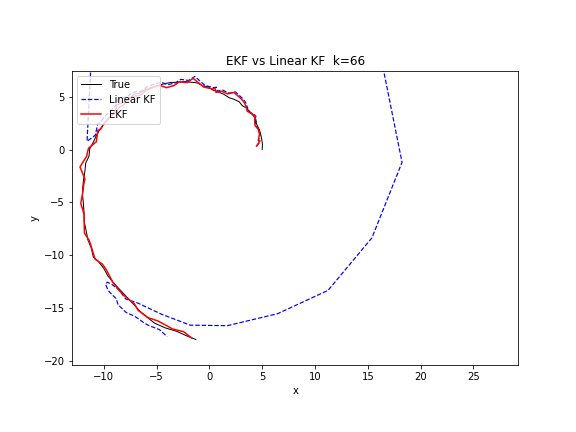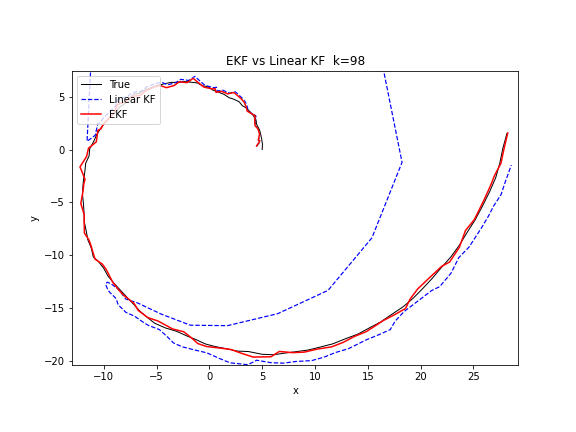
Python 实现
下面的代码对比线性 KF(匀速直线模型)与 EKF(非线性转弯模型,手动推导雅可比矩阵)对圆周运动目标的追踪。状态 \(x=[p_x, p_y, v_x, v_y]\),非线性观测函数为 \(h(x)=[\sqrt{p_x^2+p_y^2},\ \arctan2(p_y, p_x)]\),其雅可比矩阵(即观测函数对各状态分量的偏导数组成的矩阵)手动推导。输出轨迹对比图与误差图(SVG/PNG)、逐步展开的 GIF,以及记录 \(k\)、true、kf、ekf、errors 的 CSV。
import os
os.makedirs('images', exist_ok=True)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import csv
np.random.seed(42)
# ---------- 圆周运动真值 ----------
DT = 0.1
N = 120
OMEGA = 0.3 # 角速度 rad/s
R_TRUE = 1.0 # 半径
Q = np.diag([0.01, 0.01, 0.01, 0.01])
R_OBS = np.diag([0.05**2, 0.02**2]) # [距离噪声, 方位角噪声]
def true_trajectory():
tr = []
for k in range(N):
th = OMEGA * k * DT
px, py = R_TRUE * np.cos(th), R_TRUE * np.sin(th)
vx, vy = -R_TRUE * OMEGA * np.sin(th), R_TRUE * OMEGA * np.cos(th)
tr.append(np.array([px, py, vx, vy]))
return np.array(tr)
def h_obs(x):
px, py = x[0], x[1]
return np.array([np.hypot(px, py), np.arctan2(py, px)])
def H_jac(x):
# Jacobian matrix of observation function h(x):
# partial derivatives of [sqrt(px^2+py^2), atan2(py,px)] w.r.t. [px,py,vx,vy]
px, py = x[0], x[1]
r = np.hypot(px, py) + 1e-12
H = np.zeros((2, 4))
H[0, 0] = px / r
H[0, 1] = py / r
H[1, 0] = -py / (r * r)
H[1, 1] = px / (r * r)
return H
# ---------- 线性 KF:匀速直线模型 ----------
F_lin = np.array([[1, 0, DT, 0],
[0, 1, 0, DT],
[0, 0, 1, 0],
[0, 0, 0, 1]])
H_lin = np.array([[1, 0, 0, 0],
[0, 1, 0, 0]])
def kf_linear(zs):
x = np.array([1.0, 0.0, 0.0, OMEGA * R_TRUE])
P = np.eye(4) * 0.1
out = []
for z in zs:
# predict
x = F_lin @ x
P = F_lin @ P @ F_lin.T + Q
# update (观测为位置 px,py)
S = H_lin @ P @ H_lin.T + R_OBS
K = P @ H_lin.T @ np.linalg.inv(S)
x = x + K @ (z - H_lin @ x)
P = (np.eye(4) - K @ H_lin) @ P
out.append(x.copy())
return np.array(out)
# ---------- EKF:非线性转弯模型 ----------
def f_ekf(x):
px, py, vx, vy = x
# 匀速转弯:速度方向旋转 OMEGA*DT
c, s = np.cos(OMEGA * DT), np.sin(OMEGA * DT)
vx_n = c * vx - s * vy
vy_n = s * vx + c * vy
px_n = px + vx_n * DT
py_n = py + vy_n * DT
return np.array([px_n, py_n, vx_n, vy_n])
def F_jac(x):
# Jacobian matrix of state transition function f(x):
# partial derivatives of constant-turn model w.r.t. [px,py,vx,vy]
c, s = np.cos(OMEGA * DT), np.sin(OMEGA * DT)
return np.array([
[1, 0, c * DT, -s * DT],
[0, 1, s * DT, c * DT],
[0, 0, c, -s],
[0, 0, s, c],
])
def ekf(zs):
x = np.array([1.0, 0.0, 0.0, OMEGA * R_TRUE])
P = np.eye(4) * 0.1
out = []
for z in zs:
# predict
F = F_jac(x)
x = f_ekf(x)
P = F @ P @ F.T + Q
# update
H = H_jac(x)
zp = h_obs(x)
S = H @ P @ H.T + R_OBS
K = P @ H.T @ np.linalg.inv(S)
x = x + K @ (z - zp)
P = (np.eye(4) - K @ H) @ P
out.append(x.copy())
return np.array(out)
# ---------- 生成观测 ----------
truth = true_trajectory()
zs = np.array([h_obs(truth[k]) + np.random.multivariate_normal(np.zeros(2), R_OBS)
for k in range(N)])
kf_traj = kf_linear(zs)
ekf_traj = ekf(zs)
# ---------- 误差 ----------
kf_err = np.linalg.norm(kf_traj[:, :2] - truth[:, :2], axis=1)
ekf_err = np.linalg.norm(ekf_traj[:, :2] - truth[:, :2], axis=1)
# ---------- 轨迹图 ----------
fig, ax = plt.subplots(figsize=(6, 6))
ax.plot(truth[:, 0], truth[:, 1], 'k-', label='True')
ax.plot(kf_traj[:, 0], kf_traj[:, 1], 'r--', label='Linear KF')
ax.plot(ekf_traj[:, 0], ekf_traj[:, 1], 'b-.', label='EKF')
ax.set_xlabel('px'); ax.set_ylabel('py')
ax.set_title('Circular Motion: Linear KF vs EKF')
ax.legend(); ax.axis('equal'); ax.grid(True)
fig.tight_layout()
fig.savefig('images/ekf_trajectory.svg'); fig.savefig('images/ekf_trajectory.png')
plt.close(fig)
# ---------- 误差图 ----------
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(kf_err, 'r-', label='Linear KF')
ax.plot(ekf_err, 'b-', label='EKF')
ax.set_xlabel('k'); ax.set_ylabel('Position Error')
ax.set_title('Position Error: Linear KF vs EKF')
ax.legend(); ax.grid(True)
fig.tight_layout()
fig.savefig('images/ekf_error.svg'); fig.savefig('images/ekf_error.png')
plt.close(fig)
# ---------- GIF:两条轨迹逐步展开 ----------
fig, ax = plt.subplots(figsize=(6, 6))
ax.set_xlim(-1.5, 1.5); ax.set_ylim(-1.5, 1.5)
ax.set_xlabel('px'); ax.set_ylabel('py')
ax.set_title('Circular Motion: Linear KF vs EKF')
ax.grid(True)
ln_t, = ax.plot([], [], 'k-', label='True')
ln_k, = ax.plot([], [], 'r--', label='Linear KF')
ln_e, = ax.plot([], [], 'b-.', label='EKF')
ax.legend()
def update(i):
ln_t.set_data(truth[:i, 0], truth[:i, 1])
ln_k.set_data(kf_traj[:i, 0], kf_traj[:i, 1])
ln_e.set_data(ekf_traj[:i, 0], ekf_traj[:i, 1])
return ln_t, ln_k, ln_e
ani = animation.FuncAnimation(fig, update, frames=N, interval=50, blit=True)
ani.save('images/滤波05-图1.gif', writer='pillow')
plt.close(fig)
# ---------- CSV ----------
with open('images/ekf_comparison.csv', 'w', newline='') as f:
w = csv.writer(f)
w.writerow(['k', 'true_px', 'true_py', 'kf_px', 'kf_py', 'ekf_px', 'ekf_py', 'kf_err', 'ekf_err'])
for k in range(N):
w.writerow([k, truth[k, 0], truth[k, 1], kf_traj[k, 0], kf_traj[k, 1],
ekf_traj[k, 0], ekf_traj[k, 1], kf_err[k], ekf_err[k]])
演化与局限
EKF 把卡尔曼滤波从线性推广到了非线性,是工程实践中使用最广泛的非线性滤波器。但它的核心手段——一阶泰勒展开——有两个根本缺陷。第一,当非线性程度较强时,线性化会引入不可忽略的截断误差,估计精度显著下降。第二,它要求 \(f\) 和 \(h\) 处处可微,遇到不连续或不可微的函数时无法使用。
如果不去近似函数本身,而是去近似分布呢?用一组确定性的采样点通过非线性函数后再重建分布的均值和协方差——这避开了雅可比计算,也保留了更高阶的统计信息。这就是无迹卡尔曼滤波(UKF),下一篇的主题。
参考文献
[1] arXiv:1903.09247 — The Hitchhiker's Guide to Nonlinear Filtering.
[2] arXiv:2201.08180 — Sequential Bayesian Inference for Uncertain Nonlinear Dynamic Systems: A Tutorial.