平时看一些冷门的外语视频或者听外文歌的时候,经常会遇到一个尴尬的情况:想看懂内容,但是找不到字幕,字幕组也不一定会做。虽然现在市面上有一些自动生成字幕的软件,但要么收费贵,要么需要上传文件到云端,对于比较注重隐私或者钱包不鼓的朋友来说,多少有点劝退。
为了解决这个问题,我最近利用业余时间写了一个小开源项目,取名叫 TingShuo (听说)。
做这个小工具的初衷很简单,就是想利用现在已经很强大的开源语音识别模型(比如 Whisper),在自己的电脑上就能给音视频文件生成字幕。它不是什么功能繁复的商业软件,就是为了解决两个最基础的需求:
第一是给视频生成 SRT 字幕。 如果你下载了一部没有字幕的生肉电影,或者想看一段没有翻译的视频,可以直接把视频文件丢给 TingShuo。它会调用本地的模型,自动识别语音并生成一个 SRT 字幕文件。虽然机器识别的准确率肯定比不上人工精校,但用来辅助理解剧情,或者作为“啃生肉”的辅助,已经完全够用了。
第二是给音频生成 LRC 歌词文件。 有时候听到一首好听的外语歌,或者想整理一下播客的内容,也可以用它来处理音频文件。它会生成带时间戳的 LRC 文件,方便配合播放器使用。
因为是跑在本地的,所以完全不需要担心隐私问题,也不需要联网上传文件(除了下载模型的时候)。只要你的电脑性能还过得去,识别速度也是可以接受的。
目前这个项目还处在比较早期的阶段,代码可能还不够优雅,识别效果也很大程度上依赖于所选的开源模型能力,难免会有识别错误或者时间轴对不齐的情况。作为一个个人的小开源项目,肯定还有很多不完善的地方,大家在使用过程中如果遇到 bug 或者有什么建议,欢迎随时反馈,后续我也会在业余时间慢慢更新和优化。
如果你也想试一试,可以参考下面的安装和使用方法。因为是 Python 写的小程序,所以需要你的电脑上安装了 Python 环境(建议 3.12 以上版本)以及 ffmpeg(用于处理音视频)。
安装方法
最简单的方式就是直接用 pip 安装。打开你的终端或者命令行,输入:
# 推荐安装 faster-whisper 引擎,速度快,支持显卡加速
pip install tingshuo[faster-whisper]
如果你想体验更多引擎(比如 vosk 或者原本的 whisper),也可以把中括号里的内容换一下,或者干脆全装上:
pip install tingshuo[all]
关于模型下载
第一次运行的时候,程序会自动下载需要的语音识别模型。
我知道国内下载 HuggingFace 的模型有时候会很慢或者直接失败,所以特意内置了镜像支持。如果你发现下载不动,可以在命令后面加上镜像参数--hf-mirror https://hf-mirror.com,或者在图形界面里勾选“Use HF Mirror”。
如何使用
安装好之后,有2种方式可以使用它,大家看自己习惯选哪种都行。
1. 图形界面(GUI)
如果你不喜欢敲命令,安装完直接运行这一句,就能弹出一个操作界面:
tingshuo --gui
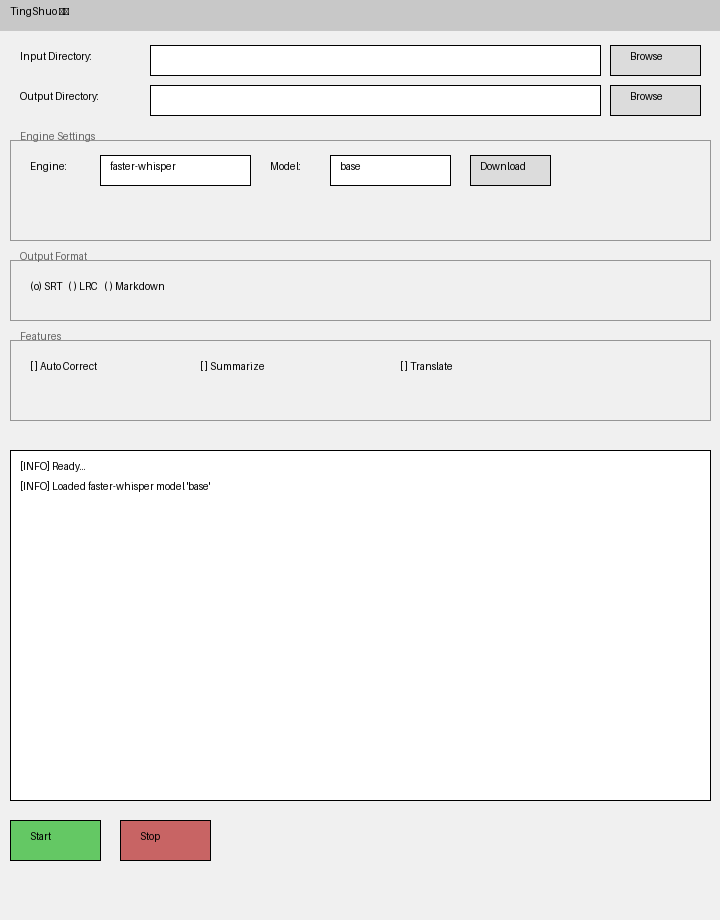
在界面里选好你的视频文件夹,点一下开始,等着收字幕就行了。
2. 命令行(CLI)
如果你是极客用户,喜欢用命令行批量处理,也可以直接一条命令搞定。比如把 videos 文件夹里的视频都生成 SRT 字幕:
tingshuo -i ./videos -e faster-whisper -f srt
虽然它只是一个小工具,但如果能帮你省去等待字幕的时间,或者让你在看生肉视频时稍微轻松一点,那它的目的就达到了。
项目地址:https://github.com/cycleuser/TingShuo